爬取美团的用户评价
1.分析网页
(1)对比切换网页时的URL
第一页如下图:

切换到第2页时如下图:

对两页的链接进行对比:
第1页链接为:
https://www.meituan.com/meishi/2469129/
第2页链接为:
https://www.meituan.com/meishi/2469129/
对比后发现两个链接一样,故该网站是基于ajax跳转的, 要使用抓包的方式来爬取数据
(2)ajax与抓包技术介绍
每一个网页都有一个html框架,网页上的内容将在这个框架中呈现,而基于ajax跳转的网页(即切换网页时,链接无变化的网页),就是将ajax加载出来的内容放到html框架中去。而抓包技术就是在ajax将加载出来的内容放到html框架的这个过程中,利用python语言将数据拦截并获取下来
2.利用抓包技术抓取网页
(1)审查代码
找到包含有评论的那个文件,如下图:
 在选中的文件中,发现文件中的文字和网页上显示的文字相对应,即这个文件就是我们要找的文件包
在选中的文件中,发现文件中的文字和网页上显示的文字相对应,即这个文件就是我们要找的文件包
(2)打开jupyter notebook
- 新建一个文件夹,并在其中打开
Jupyter notebook

将张一步找到的那个链接在新标签页打开,便可看到该网页上的所有内容,如下图:
 打开后,如下图所示:
打开后,如下图所示:
 通过红圈中的内容和网页的对比,可以确定就是我们所要的评论内容
通过红圈中的内容和网页的对比,可以确定就是我们所要的评论内容
(3)将评论的json文件解析出来
- 将json文件的内容复制到一个json在线解析之中解析出具有规范化格式的文件
json在线解析网址:
https://www.sojson.com/simple_json.html
要复制的内容为:
 利用json在线解析解析出来的内容为:
利用json在线解析解析出来的内容为:

(4)复制内容链接
- 方法一:
 得到链接为:
得到链接为:
https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=c1b7c81aeaf04a259833.1586665372.1.0.0&platform=1&partner=126&originUrl=https%3A%2F%2Fwww.meituan.com%2Fmeishi%2F2469129%2F&riskLevel=1&optimusCode=10&id=2469129&userId=&offset=0&pageSize=10&sortType=1
Headers下方的Reponse URL即是我们要复制的链接
- 方法二:
 右击,选择
右击,选择copy、再点击copy link address也可得到我们要的链接
链接为:https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=c1b7c81aeaf04a259833.1586665372.1.0.0&platform=1&partner=126&originUrl=https%3A%2F%2Fwww.meituan.com%2Fmeishi%2F2469129%2F&riskLevel=1&optimusCode=10&id=2469129&userId=&offset=0&pageSize=10&sortType=1
(5)请求网页
- 步骤和基于html跳转的网页一样,只是此处的链接是那个文件包的链接,也就是上一步所复制的链接,代码及运行结果如下:
#导入requests 库
import requests
#复制链接
ajax_url="https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=c1b7c81aeaf04a259833.1586665372.1.0.0&platform=1&partner=126&originUrl=https%3A%2F%2Fwww.meituan.com%2Fmeishi%2F2469129%2F&riskLevel=1&optimusCode=10&id=2469129&userId=&offset=0&pageSize=10&sortType=1"
#构造字典
headers_meituan={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36"
}
requests.get(url=ajax_url,headers=headers_meituan)
运行结果为:
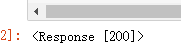
返回200,说明请求网页成功
requests.get(url=ajax_url,headers=headers_meituan)将语句赋一个值,看一下网页返回的内容
#导入requests库
import requests
#复制链接
ajax_url="https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=c1b7c81aeaf04a259833.1586665372.1.0.0&platform=1&partner=126&originUrl=https%3A%2F%2Fwww.meituan.com%2Fmeishi%2F2469129%2F&riskLevel=1&optimusCode=10&id=2469129&userId=&offset=0&pageSize=10&sortType=1"
#构造字典
headers_meituan={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36"
}
reponse=requests.get(url=ajax_url,headers=headers_meituan)
print(reponse)
reponse.text #输出返回值文本内容
运行结果为:

- 上一步中用
reponse.text语句返回的值较为凌乱,不便于提取信息,故我们将用另一个语句reponse.json()来输出reponse,如下图:
#导入requests 库
import requests
#复制链接
ajax_url="https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=c1b7c81aeaf04a259833.1586665372.1.0.0&platform=1&partner=126&originUrl=https%3A%2F%2Fwww.meituan.com%2Fmeishi%2F2469129%2F&riskLevel=1&optimusCode=10&id=2469129&userId=&offset=0&pageSize=10&sortType=1"
#构造字典
headers_meituan={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36"
}
reponse=requests.get(url=ajax_url,headers=headers_meituan)
print(reponse)
reponse.json()
运行结果为:
 和上面用
和上面用reponse.text语句来输出的结果比较起来,格式更为规范
3.提取json文件中的信息
(1)理解html中层级关系
 (图片来自于
(图片来自于json在线解析中),理解html中代码间的层级关系,我们将根据这种层级关系来提取信息
(2)开始提取信息
- 获取包含在第二阶梯
["comments"]内的信息
reponse.json()["data"]["comments"] #获取到了第二阶梯内的内容
运行结果如下:
 在
在jupyter notebook页面使用ctrl+f对运行出来的userName进行查找,可得:

说明一共显示出来10个用户在第二阶梯["comments"]的相关信息
- 如何准确地查找某一个评论用户的姓名?
如查找第一个用户的名字:
reponse.json()["data"]["comments"][0]["userName"]
#获取第一个评论用户的名字
运行结果:

查找第二个用户的名字:
reponse.json()["data"]["comments"][1]["userName"]
#获取第二个评论用户的名字
运行结果:
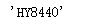
查找第十个用户的名字:
reponse.json()["data"]["comments"][9]["userName"]
#获取第十个评论用户的名字
运行结果:
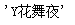
- 用
for循环语句将10个用户的名字一次性提取出来
for item in reponse.json()["data"]["comments"]:
name=item["userName"]
print(name)
运行结果:

(3) 提取所有用户的评论
for item in reponse.json()["data"]["comments"]:
name=item["userName"]
comment=item["comment"]
print(name)
print(comment)
运行结果:

(4) 再提取所有用户的用户id和头像链接
for item in reponse.json()["data"]["comments"]:
name=item["userName"]
user_id=item["userId"]
user_Url=item["userUrl"]
comment=item["comment"]
print("-"*90)
print(name,user_id,user_Url,comment)
运行结果为:

4.将提取到的信息保存为csv文件
import csv
fp=open("./美团.csv",'a',newline='',encoding='utf-8-sig')
writer=csv.writer(fp)
writer.writerow(("用户姓名","ID","头像链接","评论"))
for item in reponse.json()["data"]["comments"]:
name=item["userName"]
user_id=item["userId"]
user_Url=item["userUrl"]
comment=item["comment"]
result=(name,user_id,user_Url,comment)
writer.writerow(result)
fp.close()
运行结果:
打开美团文件夹:
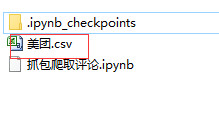
成功保存为csv文件,打开文件检查:
 成功写入文件
成功写入文件
5.将所有页面的内容提取并保存
只要在上述代码中将所有网页url进行循环,即可爬取到所有页面的相关内容
(1)分析ajax页面链接
第一页:https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=c1b7c81aeaf04a259833.1586665372.1.0.0&platform=1&partner=126&originUrl=https%3A%2F%2Fwww.meituan.com%2Fmeishi%2F2469129%2F&riskLevel=1&optimusCode=10&id=2469129&userId=&offset=0&pageSize=10&sortType=1
第二页:https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=c1b7c81aeaf04a259833.1586665372.1.0.0&platform=1&partner=126&originUrl=https%3A%2F%2Fwww.meituan.com%2Fmeishi%2F2469129%2F&riskLevel=1&optimusCode=10&id=2469129&userId=&offset=10&pageSize=10&sortType=1
第三页:https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=c1b7c81aeaf04a259833.1586665372.1.0.0&platform=1&partner=126&originUrl=https%3A%2F%2Fwww.meituan.com%2Fmeishi%2F2469129%2F&riskLevel=1&optimusCode=10&id=2469129&userId=&offset=20&pageSize=10&sortType=1
第680页:https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=c1b7c81aeaf04a259833.1586665372.1.0.0&platform=1&partner=126&originUrl=https%3A%2F%2Fwww.meituan.com%2Fmeishi%2F2469129%2F&riskLevel=1&optimusCode=10&id=2469129&userId=&offset=680&pageSize=10&sortType=1
可以发现,所有链接间只有下面这个位置不一样:
- 用
for循环表示这个规律:
for num in range(0,681,10):
print(num)
运行结果:
(此处为部分运行结果)
- 将循环规律放入链接中
for num in range(0,681,10):
ajax_url="https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=c1b7c81aeaf04a259833.1586665372.1.0.0&platform=1&partner=126&originUrl=https%3A%2F%2Fwww.meituan.com%2Fmeishi%2F2469129%2F&riskLevel=1&optimusCode=10&id=2469129&userId=&offset=%s&pageSize=10&sortType=1"%num
print(ajax_url)
结果如下:
 因为在链接中加入循环规律时,加了一个
因为在链接中加入循环规律时,加了一个%s,而连接中本身就带有一个%,所以识别不出加入的%s
- 使用另一种方法加入循环规律
for num in range(0,681,10):
ajax_url="https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=c1b7c81aeaf04a259833.1586665372.1.0.0&platform=1&partner=126&originUrl=https%3A%2F%2Fwww.meituan.com%2Fmeishi%2F2469129%2F&riskLevel=1&optimusCode=10&id=2469129&userId=&offset=" +str(num)+ "&pageSize=10&sortType=1"
print(ajax_url)
即在offset=的后面将数字删去,然后改为" +str(num)+ "即可
运行结果:

(2)提取所有内容并保存
- 保存所有页面的代码写好以后,因为上面单独保存过第一页的内容,所以现在保存所有页面的内容需要把保存第一页生成的.csv文件先删除,但是出现无法删除的情况:
 因为保存所有页面的代码中,有打开该文件的语句,所以需要在综合代码的下一行,单独写一个
因为保存所有页面的代码中,有打开该文件的语句,所以需要在综合代码的下一行,单独写一个fp.close()语句,将该文件关闭以后才能删除:(还可以点击jupyter notebook中的重启服务,也可将文件关闭)
- 运行爬取所有页面的代码
#汇总代码
#导入库
import requests,csv
#写入代理,构造字典
headers_meituan={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36"
}
#打开文件,写入头部
fp=open("./美团.csv",'a',newline='',encoding='utf-8-sig')
writer=csv.writer(fp)
writer.writerow(("用户姓名","ID","头像链接","评论"))
#循环链接
for num in range(0,681,10):
print("正在爬取%s条……"%num)
ajax_url="https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=c1b7c81aeaf04a259833.1586665372.1.0.0&platform=1&partner=126&originUrl=https%3A%2F%2Fwww.meituan.com%2Fmeishi%2F2469129%2F&riskLevel=1&optimusCode=10&id=2469129&userId=&offset=" +str(num)+ "&pageSize=10&sortType=1"
print(ajax_url)
#请求链接
reponse=requests.get(url=ajax_url,headers=headers_meituan)
#提取内容
for item in reponse.json()["data"]["comments"]:
name=item["userName"]
user_id=item["userId"]
user_Url=item["userUrl"]
comment=item["comment"]
result=(name,user_id,user_Url,comment)
writer.writerow(result)
fp.close() #爬取完成后关闭文件
运行结果:
 打开保存内容的文件查看:
打开保存内容的文件查看:
 至此,使用抓包方式爬取并保存内容成功!
至此,使用抓包方式爬取并保存内容成功!
