sdf
构造一个图像对,然后每个图像都依次输入该网络中,得到每张图像的每个像素的descriptors和reliability和repeatability,然后计算损失。
代码:
python train.py --save-path /path/to/model.pt 输入数据是什么?
一个字典,包含dict_keys(['img1', 'img2', 'aflow', 'mask'])
img1和img2的shape:torch.Size([3, 3, 192, 192])
aflow的shape:torch.Size([3, 2, 192, 192]) aflow是通过通过homography计算的,第一张图的对应点在第二张图上的坐标
mask的shape:torch.Size([3, 192, 192])
输入数据的计算:datasets/pair_dataset.py
class SyntheticPairDataset (PairDataset):
original_img = self.dataset.get_image(i)#获得输入图像,作为img1
#对该输入图像做变换,获得disorted后的输入图像
scaled_and_distorted_image = self.distort( dict(img=scaled_image2, persp=(1,0,0,0,1,0,0,0))) 作为img2
#根据warp的homography,获得点与点之间的对应关系,保存至aflow中(img1在img2中的对应位置)
trf = scaled_and_distorted_image['persp']#一个homography矩阵
xy = np.mgrid[0:H,0:W][::-1].reshape(2,H*W).T
aflow = np.float32(persp_apply(trf, xy).reshape(H,W,2))
meta['aflow'] = aflow
网络结构:
output = self.net(imgs=[inputs.pop('img1'),inputs.pop('img2')])
p self.net
Quad_L2Net_ConfCFS(
(ops): ModuleList(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=False, track_running_stats=True)
(2): ReLU(inplace)
(3): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=False, track_running_stats=True)
(5): ReLU(inplace)
(6): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=False, track_running_stats=True)
(8): ReLU(inplace)
(9): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2))
(10): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=False, track_running_stats=True)
(11): ReLU(inplace)
(12): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2))
(13): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=False, track_running_stats=True)
(14): ReLU(inplace)
(15): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(4, 4), dilation=(4, 4))
(16): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=False, track_running_stats=True)
(17): ReLU(inplace)
(18): Conv2d(128, 128, kernel_size=(2, 2), stride=(1, 1), padding=(2, 2), dilation=(4, 4))
(19): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=False, track_running_stats=True)
(20): Conv2d(128, 128, kernel_size=(2, 2), stride=(1, 1), padding=(4, 4), dilation=(8, 8))
(21): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=False, track_running_stats=True)
(22): Conv2d(128, 128, kernel_size=(2, 2), stride=(1, 1), padding=(8, 8), dilation=(16, 16))
)
(clf): Conv2d(128, 2, kernel_size=(1, 1), stride=(1, 1))
(sal): Conv2d(128, 1, kernel_size=(1, 1), stride=(1, 1))
)
在网络结构中的操作:先卷积操作,然后cls和sal操作
for op in self.ops:
x = op(x)
# compute the confidence maps
ureliability = self.clf(x**2)
urepeatability = self.sal(x**2)
return self.normalize(x, ureliability, urepeatability)
返回结果:dict_keys(['descriptors', 'repeatability', 'reliability', 'imgs'])
其中'descriptors'是两个(一对)图片的描述符,每个图片描述符的shape为(128,192,192)
repeatability是两个图片可重复性的度量,每个图片对应的shape为(1,192,192)
'reliability'也是一样的,两个图片可靠性的度量,每个图片对应的shape为(1,192,192)
'imgs'应该还是指的原来的两幅输入图像,每幅图像的大小为(3,192,192)
损失函数:
loss, details = self.loss_func(**allvars)
其中loss_func的输入为:dict_keys(['aflow', 'mask', 'descriptors', 'repeatability', 'reliability', 'imgs'])
loss的定义为:
MultiLoss(
(losses): ModuleList(
(0): ReliabilityLoss(
(aploss): APLoss(
(quantizer): Conv1d(1, 40, kernel_size=(1,), stride=(1,))
)
(sampler): NghSampler2()
)
(1): CosimLoss(
(patches): Unfold(kernel_size=16, dilation=1, padding=0, stride=8)
)
(2): PeakyLoss(
(preproc): AvgPool2d(kernel_size=3, stride=1, padding=1)
(maxpool): MaxPool2d(kernel_size=17, stride=1, padding=8, dilation=1, ceil_mode=False)
(avgpool): AvgPool2d(kernel_size=17, stride=1, padding=8)
)
)
)
reliablityLoss:
return 1 - ap*rel - (1-rel)*self.base
![]()
其中ap的计算:
计算每个点的ap
(1)将一个点和它在另一幅图中对应点周边3个像素内的点记为正样本,其他记为负样本。对正负样本采样(样本是指一对点是否为对应点),获得gt(1表示这对点为对应点,0表示这对点不是对应点)
(2)通过一对样本点的2个descriptor,计算得到一个分数。
(3)设置不同的分数阈值,计算正样本的pre和recall,然后计算这些样本点的ap
Ri,j是我们预测得到的点(i,j)的可靠性,如果该点越可靠,Ri,j越大,点的AP越重要,表明该点对损失的作用越大。如果该点不重要,我们希望Ri,j比较小,这点的AP就不重要
repeatability:
def forward(self, repeatability, aflow, **kw):
B,two,H,W = aflow.shape
assert two == 2
# normalize
sali1, sali2 = repeatability
grid = FullSampler._aflow_to_grid(aflow)
sali2 = F.grid_sample(sali2, grid, mode='bilinear', padding_mode='border')
patches1 = self.extract_patches(sali1)
patches2 = self.extract_patches(sali2)
cosim = (patches1 * patches2).sum(dim=2)
return 1 - cosim.mean()
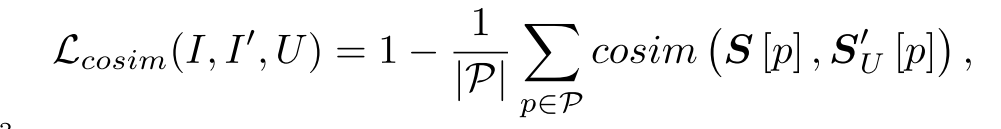

推理:
