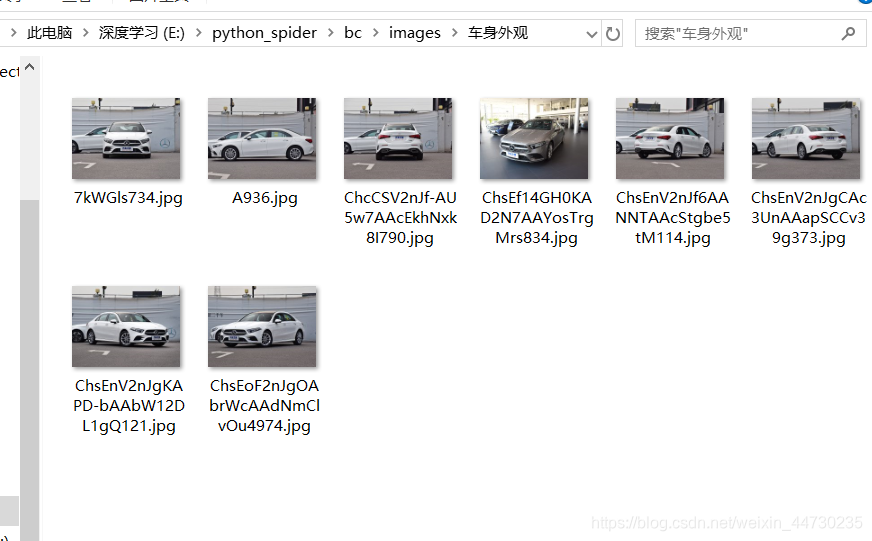
先看一下利用scrapy框架爬取汽车之家奔驰A级的效果图

1)进入cmd命令模式下,进入想要存取爬虫代码的文件,我这里是进入e盘下的python_spider文件夹内
C:\Users\15538>e:
E:\>cd python_spider
E:\python_spider>scrapy startproject bc
创建成功后,进入文件夹内
E:\python_spider>cd bc
E:\python_spider\bc>scrapy genspider bcA级 "https://www.autohome.com.cn"
创建成功,会有相对应的输出代码
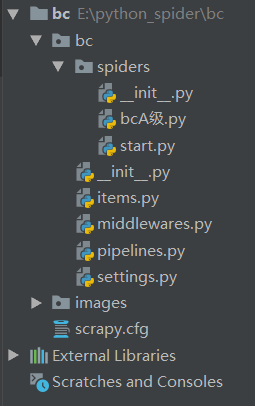
2)打开pycharm,导入文件,效果如下
3)创建start.py文件,为了更好的运行爬虫
from scrapy import cmdline
cmdline.execute("scrapy crawl bcA级".split())
#至此,start文件建立好
4)修改settings.py



5)进入主爬虫bcA级.py,编写爬虫
# -*- coding: utf-8 -*-
import scrapy
class Bca级Spider(scrapy.Spider):
name = 'bcA级'
allowed_domains = ['https://www.autohome.com.cn/4764/']
start_urls = ['https://car.autohome.com.cn/pic/series/4764.html#pvareaid=3454438']
#其中start_urls需要我们修改,打开汽车之家官网,按品牌找车--> 奔驰 --> 奔驰A级--> 图片实拍
#然后复制其地址,与原来的start_urls的参数替换即可
def parse(self,response):
#利用xpath提取,不需要全景看车,所以索引从1开始
uibox = response.xpath("//div[@class='uibox']")[1:]
for uibox in uiboxs:
title = uibox.xpath(".//div[@class='uibox-title']/a/text()").get()
urls = uibox.xpath(".//ul/li/a/img/@src").getall()
urls = list(map(lambda url:response.urljoin(url),urls))
#后面这两行代码是需要编写完items.py后,才写的。
#为了讲解清楚,我先给这两行代码注释
"""
item = BcItem(title=title,urls=urls)
yield item
"""
6)编写items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class BcItem(scrapy.Item):
#只需写两行代码即可
title = scrapy.Field()
urls = scrapy.Field()
回到bcA级.py中,在上方导入
from bc.items import BcItem
之后可以将bcA级中的最后两行代码取消注释,注意那两行代码也是写的,当时并没有,就好比这个导入,我只是为了讲解的更清晰一点。
7)编写pipelines.py
import os
from urllib import request
class BcPipeline(object):
def __init__(self):
self.path = os.path.join(os.path.dirname(os.path.dirname(__file__)),'images')
if not os.path.exists(self.path):
os.mkdir(self.path)
def process_item(self,item,spider):
title = item['title']
urls = item['urls']
title_path = os.path.join(self.path,title)
if not os.path.exists(title_path):
os.mkdir(title_path)
for url in urls:
#这行代码是给每一种图片以它的地址命名,你仔细分析每一张图的图片地址前面的都一样,所以以下划线分割,取到最后一位字符就是名字。
image_name = url.split("_")[-1]
#利用request库的urlretrieve将图片下载到title_path绝对路径。
request.urlretrieve(url,os.path.join(title_path,image_name))
return item
