python3爬虫系列16之多线程爬取汽车之家批量下载图片
1.前言
上一篇呢,python3爬虫系列14之爬虫增速多线程,线程池,队列的用法(通俗易懂),主要介绍了线程,多线程,和两个线程池的使用。
这一篇,我们就来实战一下下了~
鼠标我最近飘了,都敢去看车网浏览了,看着这么多车,又买不起,心中伤感,于是抓紧把他们拿下来,偷偷欣赏。
打开了一个看车网站,
https://car.autohome.com.cn/pic/series/66-1.html

这么多车呢?不爬取下,岂不是浪费技能?

2.网页分析
首先我们来分析一下;
宝马三系,其它细节图
https://car.autohome.com.cn/pic/series/66-12-p1.html
打开这个看车的网站图片页面
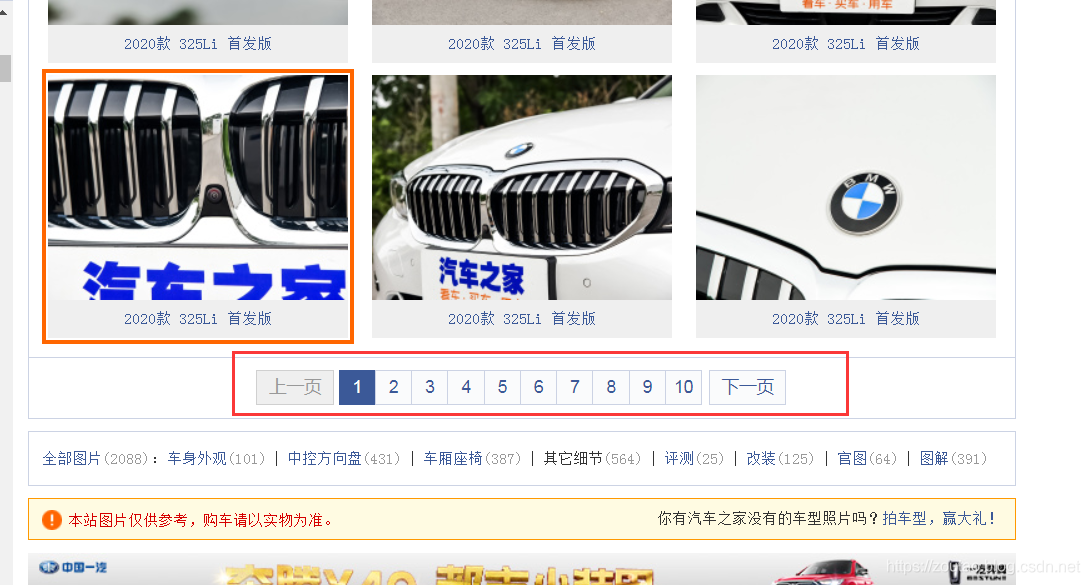
可以看到一共有 10 页,
其中每一页都是不同的细节图,而且每页基本上60张图。
够了,够了,现在点击下一页,
- 第1页: https://car.autohome.com.cn/pic/series/66-12-p1.html
- 第2页: https://car.autohome.com.cn/pic/series/66-12-p2.html
- 第3页: https://car.autohome.com.cn/pic/series/66-12-p3.html
…
可以发现 URL 变了
https://car.autohome.com.cn/pic/series/66-12-pX,
所以这个变化的地方,就是表示页数,后面直接当做变量处理,爬完一页就传下一页的参数,这样就可以一直快乐了。

紧接着,F12打开网页审查,看一下源代码,
我们要爬车的名字,所以先找到我们的车名的地址:

copy下他的xpath路径:所有车图片的div
/html/body/div[2]/div/div[2]/div[7]/div/div[2]/div[2]
再找到我们的车的细节图片img:
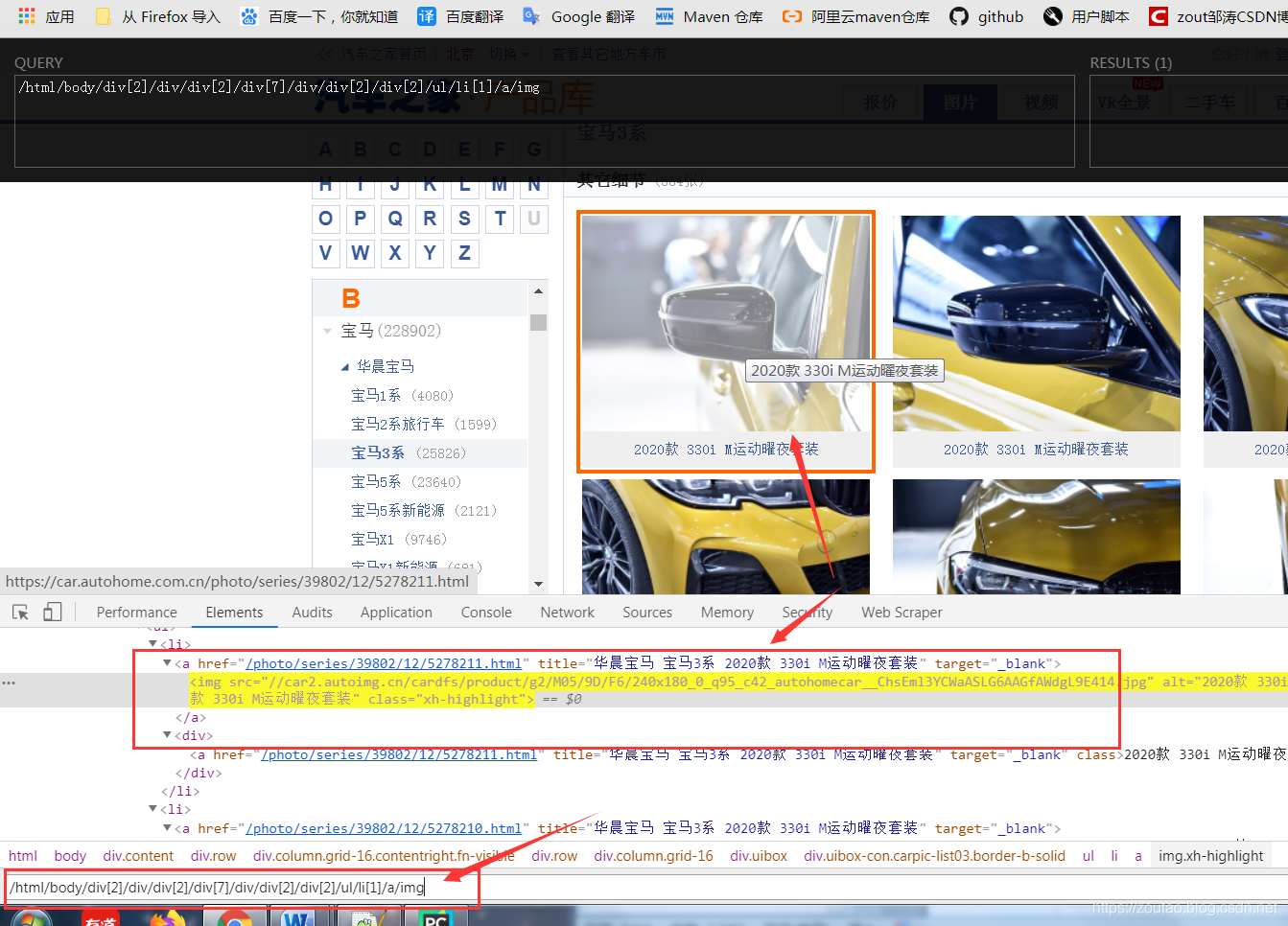
copy下他的xpath路径:所有车图片的img
/html/body/div[2]/div/div[2]/div[7]/div/div[2]/div[2]/ul/li[1]/a/img
3.写代码了
本次使用queue队列,和多线程threading一起来,还有咱们的lxml+xpath的方式。
不记得的,回头去看看:python3爬虫系列11之xpath和css selector方式的内容提取介绍。
不说了,开撸
先定义一下线程的数量:
concurrent = 3 # 采集线程数
conparse = 3 # 解析线程数
再构造每一页的url
def main():
# 生成请求队列
req_list = queue.Queue()
# 生成数据队列 ,请求以后,响应内容放到数据队列里
data_list = queue.Queue()
# 创建文件对象
f = open('qichezhijia.json','w',encoding='utf-8')
# 循环生成多个请求url
for i in range(1,10 + 1): # 10页
base_url='https://car.autohome.com.cn/pic/series/66-12-p%d.html' % i
# 加入到请求队列中
req_list.put(base_url)
生成N个采集线程:用来调用Crawl创造线程方法
# 生成N个采集线程
req_thread = []
for i in range(concurrent):
t = Crawl(i + 1, req_list, data_list) # 1.调用创造线程方法
t.start()
req_thread.append(t)
生成N个解析线程:用来调用Parse创造解析线程方法
# 生成N个解析线程
parse_thread = []
for i in range(conparse):
t = Parse(i + 1,data_list,req_thread,f) # 2.创造解析线程方法
t.start()
parse_thread.append(t)
for t in req_thread:
然后记得join一下线程:
for t in req_thread:
t.join()
for t in parse_thread:
t.join()
然后新建一个采集线程类:class Crawl(threading.Thread):
'''
采集线程类
'''
class Crawl(threading.Thread):
# 初始化
def __init__(self,number,req_list,data_list):
# 调用Thread 父类方法
super(Crawl,self).__init__()
# 初始化子类属性
self.number = number
self.req_list = req_list
self.data_list = data_list
self.headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.89 Safari/537.36'
}
# 线程启动的时候调用
def run(self):
# 输出启动线程信息
print('启动采集线程%d号' % self.number)
# 如果请求队列不为空,则无限循环,从请求队列里拿请求url
while self.req_list.qsize() > 0:
# 从请求队列里提取url
url = self.req_list.get()
print('%d号线程采集:%s' % (self.number,url))
# 防止请求频率过快,随机设置阻塞时间
time.sleep(random.randint(1,3))
# 发起http请求,获取响应内容,追加到数据队列里,等待解析
response = requests.get(url,headers=self.headers)
if response.status_code == 200:
self.data_list.put(response.text) # 向数据队列里追加
用来发送网页请求,get到网页源代码的。
在写一个解析线程类class Parse(threading.Thread):
'''
解析线程类
'''
class Parse(threading.Thread):
# 初始化属性
def __init__(self,number,data_list,req_thread,f):
super(Parse ,self).__init__()
self.number = number # 线程编号
self.data_list = data_list # 数据队列
self.req_thread = req_thread # 请求队列,为了判断采集线程存活状态
self.f = f # 获取文件对象
self.is_parse = True # 判断是否从数据队列里提取数据
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.89 Safari/537.36'
}
def run(self):
print('启动%d号解析线程' % self.number)
# 无限循环,
while True:
# 如何判断解析线程的结束条件
for t in self.req_thread: # 循环所有采集线程
if t.is_alive(): # 判断线程是否存活
break
else: # 如果循环完毕,没有执行break语句,则进入else
if self.data_list.qsize() == 0: # 判断数据队列是否为空
self.is_parse = False # 设置解析为False
# 判断是否继续解析
if self.is_parse: # 解析
try:
data = self.data_list.get(timeout=3) # 从数据队列里提取一个数据
except Exception as e: # 超时以后进入异常
data = None
# 如果成功拿到数据,则调用解析方法
if data is not None:
self.parse(data) # 3.调用页面解析方法
else:
break # 结束while 无限循环
print('退出%d号解析线程' % self.number)
# 页面解析函数
def parse(self,data):
html = etree.HTML(data)
# 获取所有车图片的div==/html/body/div[2]/div/div[2]/div[7]/div/div[2]/div[2]
duanzi_div = html.xpath('/html/body/div[2]/div/div[2]/div[7]/div/div[2]/div[2]')
for duanzi in duanzi_div:
# 获取车名
carName = duanzi.xpath('./ul/li/div/a/text()')
print('车名:',carName,len(carName))
# 获取车图==/html/body/div[2]/div/div[2]/div[7]/div/div[2]/div[2]/ul/li[1]/a/img
imgList= duanzi.xpath('./ul/li/a/img/@src')
print('图片:',imgList,type(imgList),len(imgList)) # <class 'list'>
downfiles(imgList,carName)
这是用来提取内容,采用的
html = etree.HTML(data)来解析请求到的html源代码,然后通过xpath路径来抓取需要的数据,然后封装成为字典,便于持久化入库等操作。
# 内容封装到字典
item = {
'carname': carName,
'img': imgList,
}
# 转为json对象-写入文件
self.f.write(json.dumps(item,ensure_ascii=False) + '\n')
print('爬虫完毕。')
最后调用一下 downfiles(imgList,carName)下载这个图片。
新建一个downfiles下载图片的函数:
# 创建文件对
f = open('qichezhijia.json','w',encoding='utf-8')
'''
下载图片文件
'''
def downfiles(imglist, carName):
x = 0 # 计数
for name in carName:
folder = './pic/01/' + name + '_' + str(x) # 设置图片保存的路径
if not os.path.exists(folder):
#os.makedirs(folder)
print(folder + ' => 创建成功')
# 从imglist中遍历拿到单个的imgurl
for imgurl in imglist:
# 发起网络请求来下载图片!!!(很重要)
imgres = requests.get("http:" + imgurl)
if imgres.status_code == 200:
# img.content用来返回二进制数据,wb是二进制流写入
fname = imgurl.split('/')[-1]
with open(folder + fname, "wb") as f:
f.write(imgres.content)
x += 1
print("下载第", x, "张")
else:
print('图片下载失败:',imgres.status_code)
else:
pass
print('路径已创建,请忽略 => ' + carName)
在启动一下:
if __name__ == '__main__':
start = time.time()
main() # 运行爬虫程序
end = time.time()
spendtime = end - start
print("用时 " + str(spendtime) + "秒")
运行:
耗时:
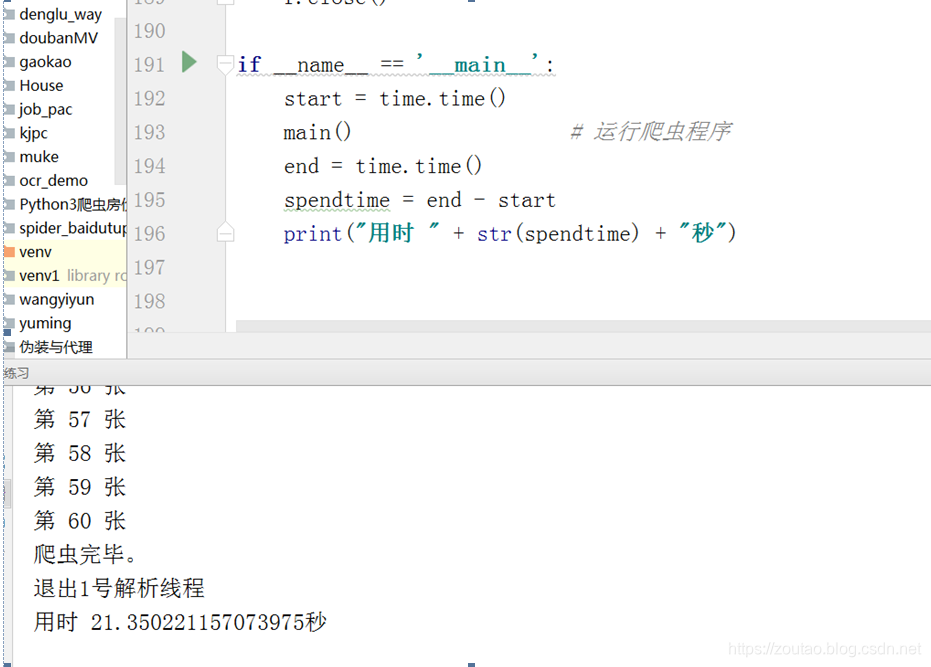
爬了:21秒。
最终效果:
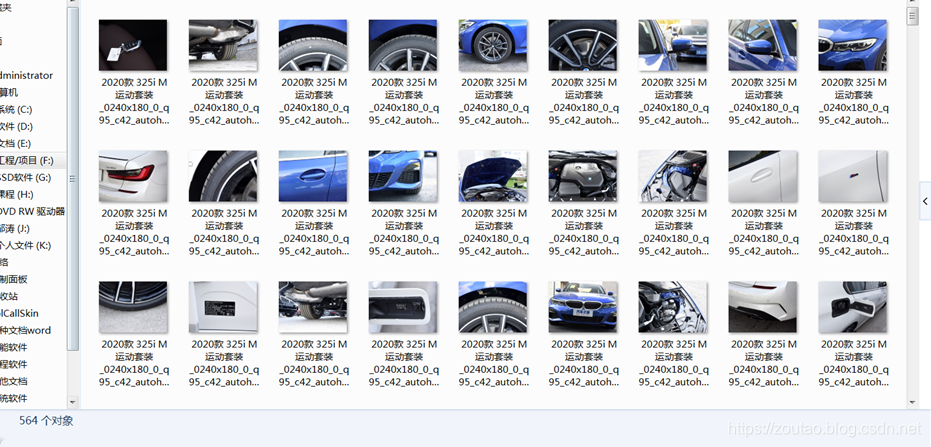
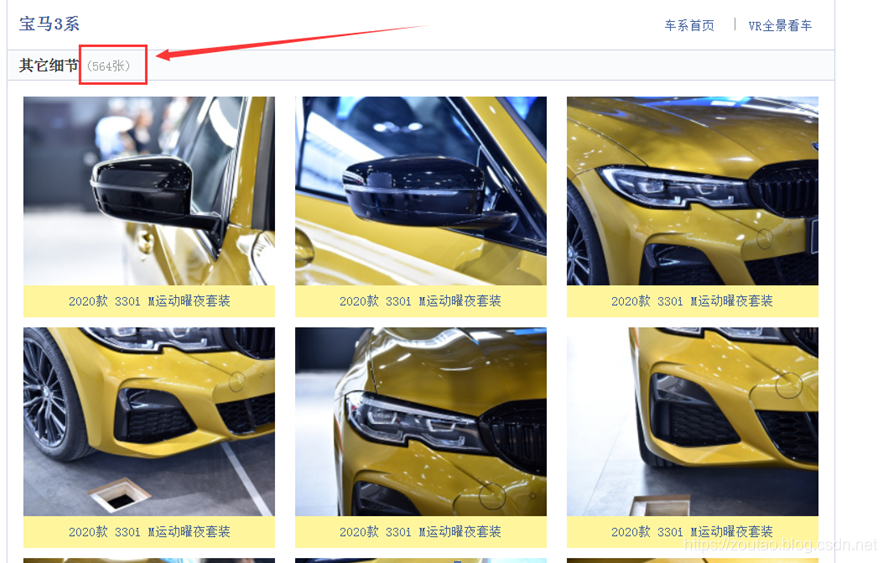
可以看到我们爬了564张。
网站上也是564张。
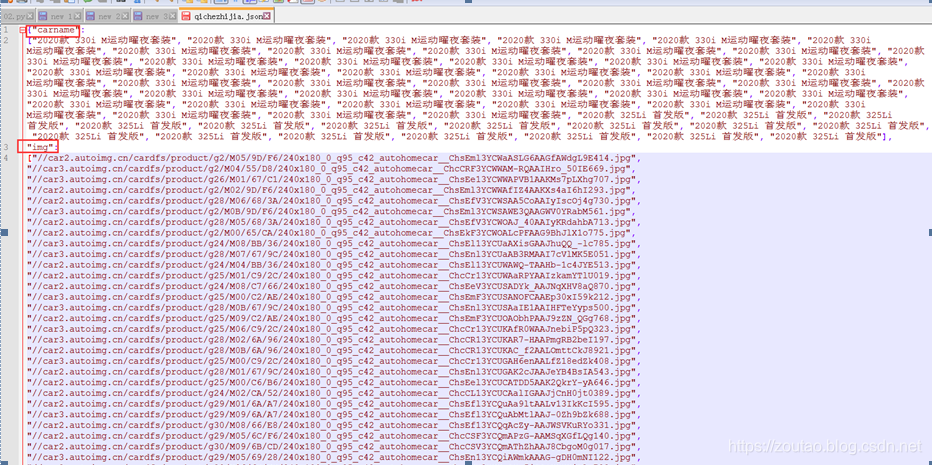
同时我们还存了json数据,方便入库。
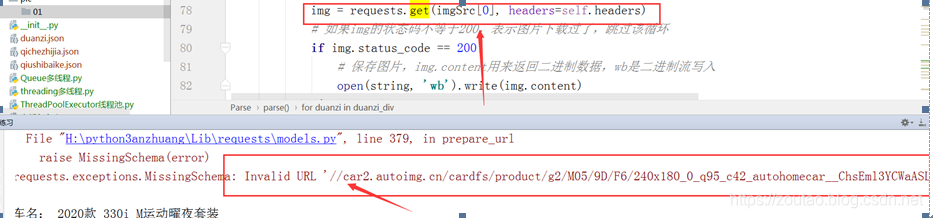
报错处理
- requests.exceptions.MissingSchema: Invalid URL ‘None’: No schema supplied. Perhaps you meant http://None?
或者这样:
- requests.exceptions.MissingSchema: Invalid URL
‘//car2.autoimg.cn/cardfs/product/g2/M05/9D/F6/240x180_0_q95_c42_autohomecar__ChsEml3YCWaASLG6AAGfAWdgL9E414.jpg’: No schema supplied. Perhaps you meant http:////car2.autoimg.cn/cardfs/product/g2/M05/9D/F6/240x180_0_q95_c42_autohomecar__ChsEml3YCWaASLG6AAGfAWdgL9E414.jpg?
图示:

原因:
爬虫中,原网页的图片img路径为不规则形式,//路径字符,自动带有的,
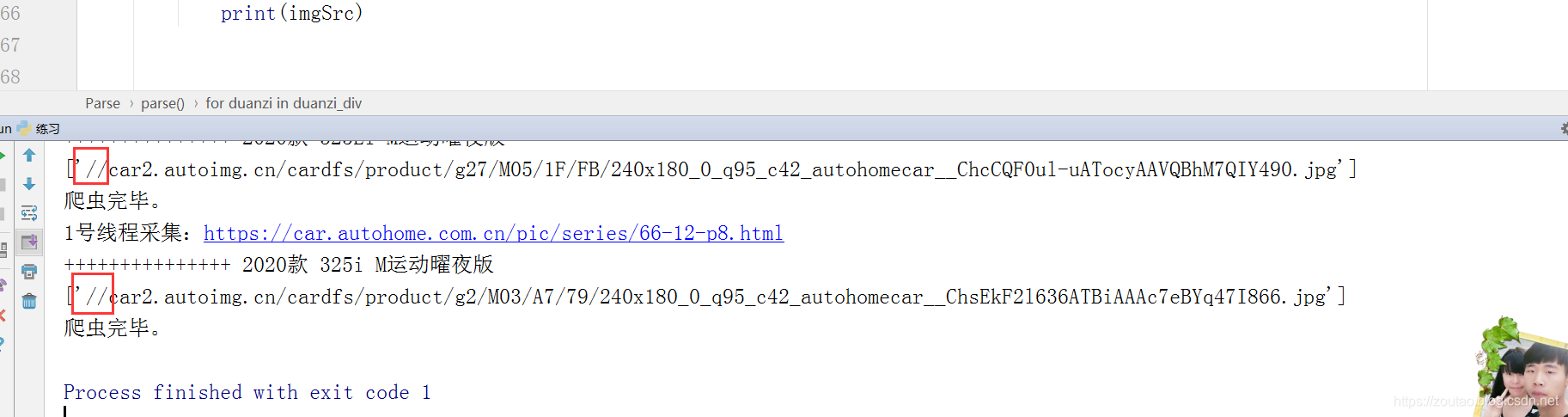
是这样的:
[’//car3.autoimg.cn/cardfs/product/g27/M0B/56/28/240x180_0_q95_c42_autohomecar__ChcCQF3ST7uAJQgYAAUBwmZly3E432.jpg’] <class ‘list’>
虽然网页请求是没有问题。: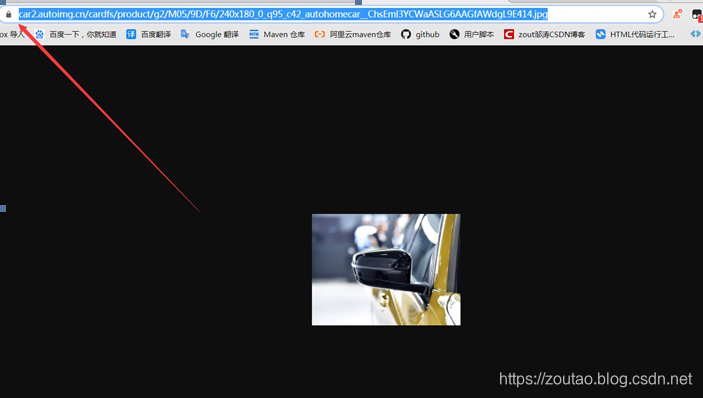
但是这种情况,我们要处理:
列表插入的方式,加个https的头,
解决方案 :
我的img是个list。
#如果url正常的,则这样就可下载图片 img = requests.get(imgSrc[0],headers=self.headers)
#如果不是正常的,则发起网络请求来下载图片!!!(很重要) img = requests.get(“http:”+imgSrc[0],headers=self.headers)
- 批量下载list集图片工具类
'''
下载文件
'''
def downfiles(imglist, title):
x = 0
folder = 'D:\\xxxxxx\\'+ time.strftime("%Y%m%d", time.localtime()) +'\\' + strreplace(title) + '\\'
if not os.path.exists(folder):
os.makedirs(folder)
print(folder+' => 已创建')
# 遍历
for imgurl in imglist:
# 获取从imglist中遍历得到的imgurl
imgres = requests.get(imgurl)
fname = imgurl.split('/')[-1]
with open(folder + fname, "wb") as f:
f.write(imgres.content)
x += 1
print("第", x ,"张")
else:
pass
print('忽略 => ' + title);
实际上源码已经附在文章,拼接即可。
也提供源码下载地址:多线程爬虫汽车之家
没有积分留下邮箱,发给你。
番外篇:
现在假如你的CPU有8核,每核CPU都可以用1个进程,每个进程可以用1个线程来进行计算。那么8核CPU同时只能对8个任务进行操作了,这样来爬虫就会非常高效。
多进程爬虫:
想要充分利用多核的CPU还是用多进程。可以做到并行爬取。
多线程爬虫:
多线程下的 GIL 锁会让多线程显得有点鸡肋。
通俗点说 GIL锁 就是一把超级大锁,即全局排他锁,保护了数据安全性的同时,使得多线程提高效率的能力几乎丧失(Python 里一个进程永远只能同时执行一个线程,拿到 GIL 的线程才能执行),这就是为什么在多核CPU上,Python 的多线程效率并不高的根本原因。
结果方法之一是python提供了mutiprocess(多进程)来弥补这个问题,
所以,在 Python 里面推荐使【用多进程】而【不用多线程】。
