python3爬虫系列12之lxml+xpath和BeautifulSoup+css selector不同方式的tiobe网站爬取
接上一篇 python3爬虫系列11之xpath和css selector方式的内容提取介绍,里面说了方法,没有实战某个网站。
本文则是作为上一篇的补充:
爬虫目标网站:https://www.tiobe.com/tiobe-index/ ,即 tiobe网,是个反映某个编程语言的热门程度的网站。
TIOBE排行榜是根据互联网上有经验的程序员、课程和第三方厂商的数量,并使用搜索引擎(如Google、Bing、Yahoo!)以及Wikipedia、Amazon、YouTube统计出排名数据,只是反映某个编程语言的热门程度,但是并不能说明一门编程语言好不好,或者一门语言所编写的代码数量多少。
1.lxml+Xpath方式爬虫tiobe最热门开发语言top20:
目标地址:
https://www.tiobe.com/tiobe-index/
目标内容:
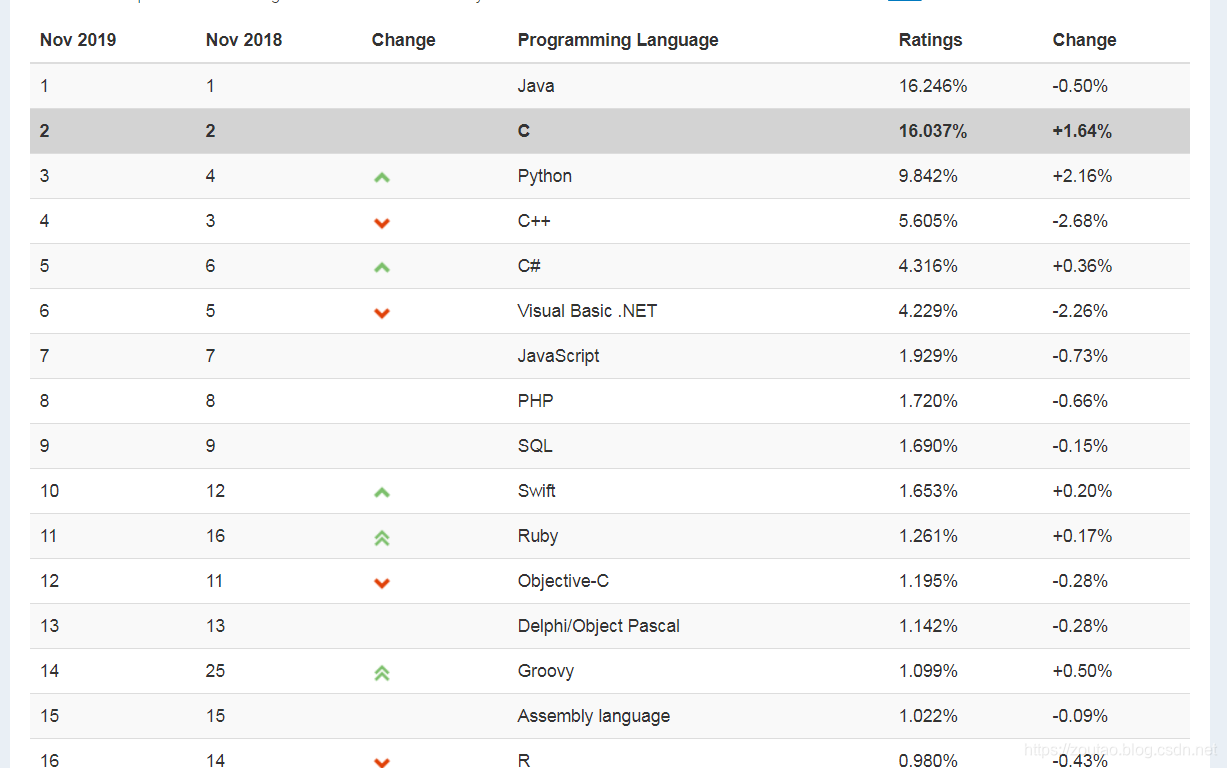
Xpath路径:
/html/body/section/section/section/article/table[1]/tbody/tr
爬虫代码如下:
#!/usr/bin/python3
import requests
from requests.exceptions import RequestException
import time
from lxml import etree
from lxml.etree import ParseError
import json
def one_to_page(html):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
try:
response = requests.get(html, headers=headers)
body = response.text # 获取网页内容
except RequestException as e:
print('request is error!', e)
try:
html = etree.HTML(body, etree.HTMLParser()) # 解析HTML文本内容
# /html/body/section/section/section/article/table[1]/tbody/tr
result = html.xpath('/html/body/section/section/section/article/table[1]/tbody/tr//text()') # //text()获取所有文本数据
print('xpath输出:',type(result),result)
pos = 0
for i in range(20): # top20
if i == 0:
yield result[i:5]
else:
yield result[pos:pos + 5] # 返回排名生成器
pos += 5
except ParseError as e:
print(e.position)
def write_file(data): # 将数据重新组合成字典写入文件并输出
print(type(data)) # generator
for list in data:
datadic = {
'2019年11月排行': list[0],
'2018年11排行':list[1],
'开发语言': list[2],
'使用率': list[3],
'增长率': list[4]
}
with open('lxml_xpath_lang.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(datadic, ensure_ascii=False) + '\n') # 必须格式化数据
f.close()
print(datadic)
return None
def main():
url = 'https://www.tiobe.com/tiobe-index/'
data = one_to_page(url)
revaule = write_file(data)
if revaule == None:
print('ok爬虫完毕。')
# 计算时间
def timeup(function):
start = time.clock()
main() # 执行函数
end = time.clock()
timeuse = end - start
print( '\n[%s()]函数一共使用了%d秒时间。\n' %(function.__name__, timeuse))
return timeuse
if __name__ == '__main__':
timeup(main)
其中注意
html.xpath('/html/body/section/section/section/article/table[1]/tbody/tr//text()') # //text()
//text()函数可以获取所有文本的数据。
效果图:
耗时:

效果:
2.BeautifulSoup+Css Selector方式爬虫tiobe最热门开发语言top20:
目标地址:
https://www.tiobe.com/tiobe-index/
目标内容:
Css Selector路径:
body > section > section > section > article > table.table.table-striped.table-top20 > tbody > tr:nth-child(1)
爬虫代码如下:
#!/usr/bin/python3
import json
import requests
from bs4 import BeautifulSoup
import bs4
import time
url = 'https://www.tiobe.com/tiobe-index/'
def one_to_page(html):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
response = requests.get(url, headers=headers,timeout=30)
body = response.text # 获取网页内容
if response.status_code == 200:
soup = BeautifulSoup(body, 'lxml')
# body > section > section > section > article > table.table.table-striped.table-top20 > tbody > tr:nth-child(1)
# 由唯一节点位置,可以简化为:table.table.table-striped.table-top20 > tbody > tr:nth-child(1)
result = soup.select('table.table.table-striped.table-top20 > tbody > tr > td') # 去掉:nth-child(1)就可以获取整个td列表
print('selector输出:',type(result),result)
# 封装对应元素-便于操作
for i in range(0,len(result)):
datadic = {
'2019年11月排行': result[0].get_text(),
'2018年11排行': result[1].get_text(),
'开发语言': result[3].get_text(), # 中间有个箭头的字段,不要
'使用率': result[4].get_text(),
'增长率': result[5].get_text()
}
#print(result[i].get_text())
return datadic
else:
print('error', response.status_code)
return None
def write_file(datadic): # 将list数据重组成字典写入文件并输出
with open('bs4_selector_lang.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(datadic, ensure_ascii=False) + '\n') # 必须格式化数据
f.close()
#print(datadic)
return None
def main():
url = 'https://www.tiobe.com/tiobe-index/'
data = one_to_page(url)
revaule = write_file(data)
if revaule == None:
print('ok爬虫完毕。')
# 计算时间
def timeup(function):
start = time.clock()
main() # 执行函数
end = time.clock()
timeuse = end - start
print( '\n[%s()]函数一共使用了%d秒时间。\n' %(function.__name__, timeuse))
return timeuse
if __name__ == '__main__':
timeup(main)
其中注意:
第一,路径可以省略掉一些,只要找到唯一标识的节点开头,前面的body什么的可以省去。
第二,去掉:nth-child(1) 就可以获取整个td列表。
耗时:

效果:
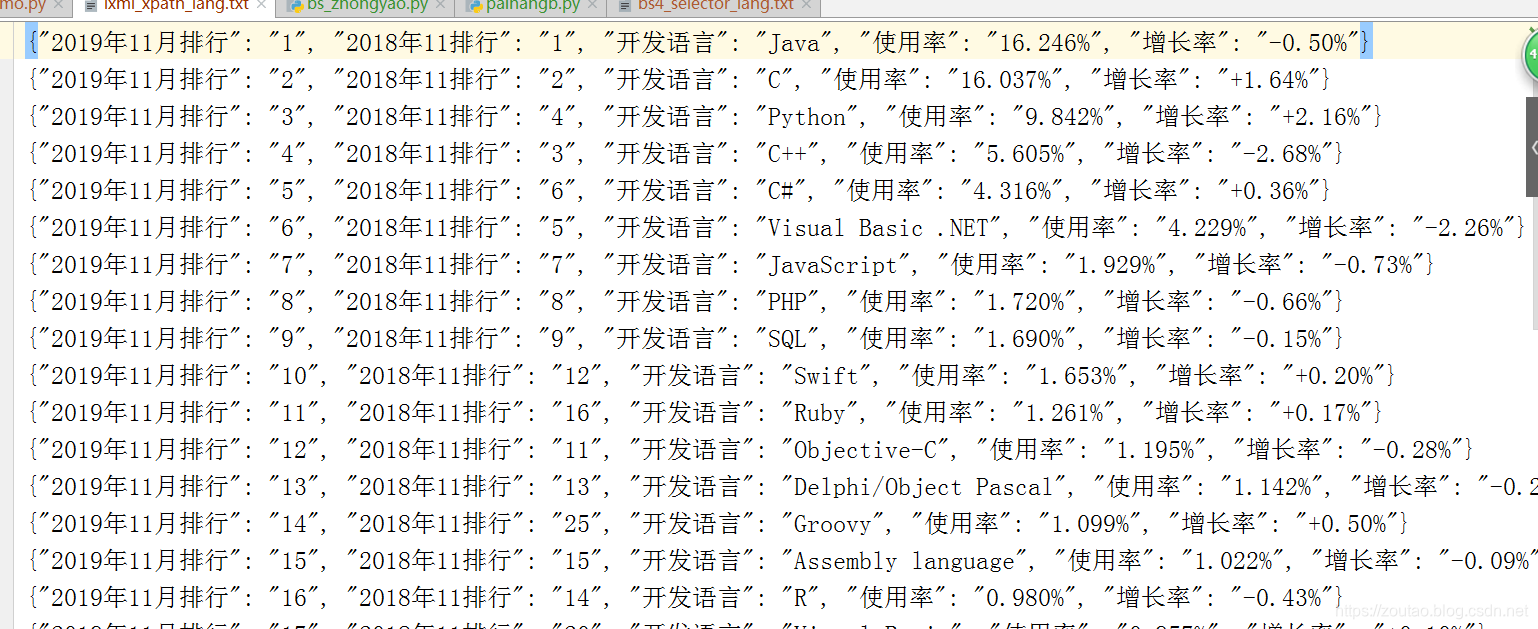
最后爬虫所得 两个文件数据 对比:
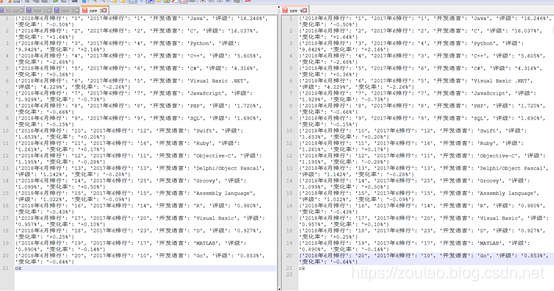
爬虫结果一致。
从结果可以看出,java占据开发语言榜首,但是最近三年内出现了负增长的现象,而反观python语言,增长率超过+2.16%,全民python的时代,怕是要来了。。。。
结论:
-
xpath和css selector方式都可以直接复制,快速得到,但是要注意校验一下,xpath匹配更快些。
-
BeautifulSoup 和lxml 方式的内容提取速度,在很少的数据量下相差无几,大数据量下lxml更快。
3.BeautifulSoup 和 lxml的区别:
Beautifulsoup4 要比Xpath解析数据要慢,因为beautifulsoup4载入的是整个html文档,解析整个DOM树,因此时间和内存开销都会大很多,所以beautifulsoup4 性能要低于 lxml,因为lxml 只会局部遍历,要快好几倍啊,但是如果你是小项目则无所谓。
BeautifulSoup 用来解析 HTML 比较简单,API非常人性化,支持CSS选择器、Python标准库中的HTML解析器,也支持 lxml 的 XML解析器。lxml相对于来说要难一些。
4.各种报错问题:
-
使用bs的时候,报错如下:
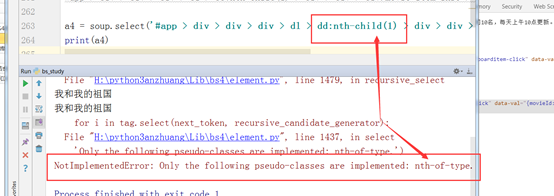 解决方法:将 nth-child更改为 nth-of-type 。
解决方法:将 nth-child更改为 nth-of-type 。 -
lxml解析出来的网页源代码含有转义字符?
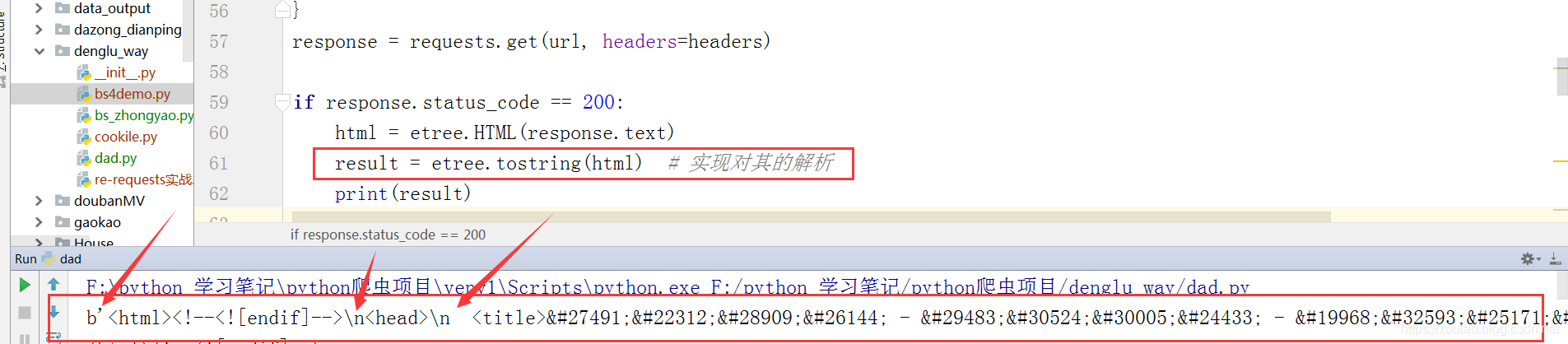
解决方法:
将 result = etree.tostring(html)
改为:
result = etree.tostring(html).decode() -
使用xpath的时候输出遇到这样?

解决:遍历。
xpath函数 返回来的永远是一个列表。
这个列表中的每一个值都是一个字典
