1. 摘要
Empirical Analysis of Predictive Algorithms for Collaborative Filtering是一篇非常经典的综述性论文。这篇论文非常“古老”,里面介绍的算法并不多,因此非常适合新手入门。这篇论文通过采用四种实验策略,两种实验标准来对比协同过滤(Collaborative Filtering,CF)中常用的两类常用算法:Memory-basd,Model-based,并对实验结果进行分析,总结。文章介绍的算法分类如下图所示:

2. Memory-based method
2.1 基础
协同过滤的核心目标在于预测目标用户(active user)对某一个物品的评分。Memory-based method的思路一般是通过参考与目标用户兴趣相似的用户(臭味相投者)对该物品的评分来预测目标用户的评分。说白了就是,跟你兴趣相投的人,对一个物品的评价应该也差不多。文章提出了两个计算评分的基础公式:
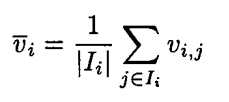
表示用户
对物品
的投票值(这里的投票是一个很宽泛的概念,评分就是其中一种形式),
表示用户感兴趣的物品集合,
就是一个用户
的投票均值。

可以看出,
是自身的投票均值,用户关系权重
以及用户
对应的投票值,投票均值所决定。该算法把所有用户对物品
的投票值都计算一遍,然后通过
调控用户
的贡献力度,这也能很能体现“协同”这一概念。
2.2 Correlation and Vector Similarity
代表用户
与用户
的某种联系,一般用相关性表示。根据
形式的不同。算法可分为Correlation与Vector Similarity两种。
对于Correlation,
一般采用皮尔森系数来作为相关性表示:
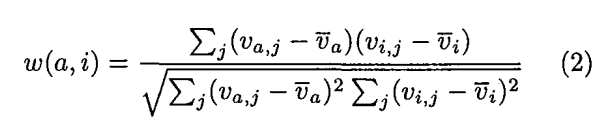
对于Vector Similarity,
同样采用皮尔森系数来作为相关性表示,只是采用向量的形式。
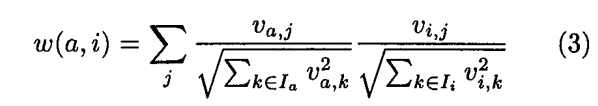
2.3 Extention
这一部分主要介绍能有效提升Memory-based算法性能的一些技巧。
2.3.1 Default Voting
建立用户-目标矩阵时无可避免地会有很多缺失值,因此在缺失部分填充一定的默认值可以有效提高算法性能。至于在哪里填充,怎么填充,论文也没有给出具体的方法,只是提了一句:
If we assume some default value as a vote for titles for which we do not have explicit votes, then we can form the match over the union of voted items,(I, U Ij), where the default vote value is inserted into the formula for the appropriate unobserved items.
2.3.2 Inverse User Frequency
Inverse User Frequency 基于一种“低频具有更高代表性”的理念,将
进行了调整。算法首先定义了一个热门因子
=
,其中
表示用户总数,
表示对物品
感兴趣的用户数。因此,当所有用户都对物品
感兴趣。
= 0,即越热门,因子值越小。
调整为:

说白了,这个公式就是通过热门因子调整每个物品的权重。
2.3.3 Case Amplification
这也是一种权重调节方式,加重投票值接近1的相关性(高相关),而惩罚低相关性的项
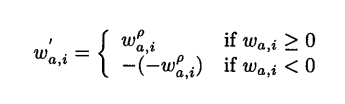
3. Model-based method
Model-based method主要分为聚类模型和贝叶斯网(这是当年的研究现状,目前当然有很多深度学习的方法被应用于推荐系统)。聚类模型一般采用朴素贝叶斯来挖掘用户,物品中的“隐类”,这个隐类的数目在论文中使用EM算法估计而来,而隐类的内容一般则由聚类模型自行挖掘,具有不可解释性(这种思想倒有点类似于矩阵分解中嵌入隐类的做法。)贝叶斯网应该能称得上是深度学习用于推荐系统的开山鼻祖,在训练贝叶斯网的过程中,贝叶斯网根据物品的依赖关系生成一棵树,使得这棵树可以准确地预测目标用户对一个物品感兴趣的概率。
4.实验
4.1 实验方案
数据库:
| 数据库 | 说明 |
|---|---|
| MS WEB | Microsoft corporate web site 的访问记录 |
| Television | Neilsen Network 的电视购买访问记录(二进制) |
| Each Moive | 用户对电影的评分数据 |
两种推荐任务:
| 任务 | 评价标准 |
|---|---|
| 推荐一个物品 | 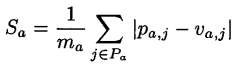 |
| 推荐一个列表 | 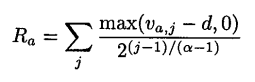 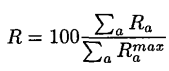 |
推荐算法通常有两种推荐形式,一是推荐一个具体的物品,二是推荐一个有序列表。推荐一个物品方法用误差即可表达算法的预测性能。
对于推荐一个有序列表,论文采用了 来作为评价标准。其中max( -d,0)表示:出用户 感兴趣的物品(如果投票制大于中性投票值d,则取其差值,否则为0)。2(j-1)/(a-1)为指数衰减因子,
实验方法:
| Given2 | Given5 | Given10 | AllBut1 |
|---|---|---|---|
| 在测试集中抽取两个值 | 在测试集中抽取5个值 | 在测试集中抽取十个值 | 在测试集中抽取一个值 |
在实验方法中,Allbut1 用于测试当给算法投喂大量数据时算法的性能,而其他的 目的在于测试给与算法不同数量的数据集,观察算法的性能走向。
4.2 实验结果
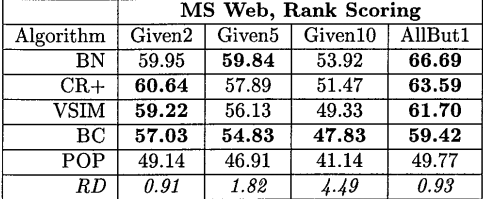
情况一:推荐列表情况下,算法在三个数据库上的得分如下三表:


情况二:评分条件在EachMoive数据集上的表现
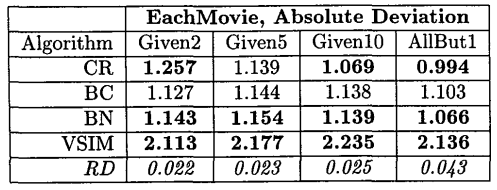
其中:
| CR+ | 协同过滤+extension |
|---|---|
| BC | 贝叶斯聚类模型 |
| BN | 贝叶斯网络 |
| VSIM | 使用向量相似度的协同过滤 |
| POP | 零阶写过滤 |
4.3 结果分析
从以上实验结果,可得出以下结论:
- 在有充足数据的前提下,贝叶斯网络的性能更佳,协同过滤+extension技巧算法其次。但数据量不足的时候,算法性能有所下降
- 在EachMoive的评分实验中,贝叶斯聚类方法的性能最好,说明隐分类对评分任务有积极意义
- 不同的数据库,算法的性能不尽相同,例如贝叶斯聚类方法在Nelison数据集上表现非常糟糕,在EachMoive的评分任务上表现却很好。
5 总结
读完这篇论文,对协同过滤应该有一定的了解,包括协同过滤的思想,挑战,解决思路,提升性能的小技巧等等,正如开头所说,这是一篇年份久远的论文,只能帮助笔者了解协同过滤一些非常基本的知识。下一步笔者将会阅读最新的关于深度学习在推荐系统中应用的综述论文。
