先来看一下希尔排序:
原理概述
希尔排序其实是插入排序的改进版本,性能会有所提升,该算法设置一个gap步长(后续会变化),选取原序列的隔步长的元素组成一个子表,对该子表使用插入排序,其实很明显的就是每设置一个步长该原序列就会被分成gap个子表,对所有子表都分别进行插入排序,也就是在各自的表顺序内进行插入排序,但是操作的元素仍是原表中对应的索引(而不是新的子表中的索引,所以子表中每两个元素之间的间隔为gap)。接下来再让gap减半,这样子表的数目减少,每个子表中的元素变多,然后对这些新的子表仍然进行插入排序,接下来再让gap减半,再对生成的新的子表插入排序,,,以此类推,知道最后gap=1也就是会有一个原序列作为子表(其实只是顺序不一样了,长度还是原序列的长度,因为步长为1嘛)
代码实现
我发现我的智商真的有问题,,,,,想了好久,,,,我,,,
# -*- coding: utf-8 -*-
"""
Created on Sat May 26 13:45:51 2018
@author: Administrator
"""
#**********************************希尔排序**********************************
def Shell_sort(L):
n=len(L)
gap=n//2
while gap>=1:
for i in range(gap): #0,1,2,3
member=int((n-1-i)/gap)+1 #每一组有多少元素 #3,
for j in range(1,member):
for k in range(j,0,-1):
if L[i+k*gap]<L[i+k*gap-gap]:
L[i+k*gap],L[i+k*gap-gap]=L[i+k*gap-gap],L[i+k*gap]
print(L)
gap=int(gap/2)
print(L)
if __name__=="__main__":
Shell_sort([2,6,1,3,0,4,8,5])
结果展示
[0, 4, 1, 3, 2, 6, 8, 5]
[0, 3, 1, 4, 2, 5, 8, 6]
[0, 1, 2, 3, 4, 5, 6, 8]
[0, 1, 2, 3, 4, 5, 6, 8]这里我把初始步长设为4,然后每次减半,把每次结果都打印了(4,2,1对应三个排序结果)最后一个是最终排好的我又打印了一次。
虽然写出来了,可是并不是秒做,,不开心。
嗯,刚才看了一下老师的解决思路,发现又被秒了好嘛,哼
先说一下具体的思路:
解题思路
首先就是把原始的序列分成gap份 也就相当于有gap个子序列,我们需要对当前gap下划分的这gap个子序列进行初步排序,也就是此次gap结束后每一个子序列都必须排好序,然后对于下一次gap划分仍然采取上述步骤进行插入排序
先把数据分为子序列的第一个元素和子序列需要比较(插入)的元素,然后对于后边一部分元素,我们不是把第一个子序列都比较好之后再开始第二个子序列的排序,而是把子序列待排序部分的第一个进行插入排序,因为他们都是gap,gap+1,gap+2,,,n-1 这些值,他们前面的元素都是各自索引-gap即可(说的好啰嗦,直接看代码比较好)
嗯,看懂老师的思路之后自己又写了一个,思路是一样的,如下:
嗯,发现我还是不太喜欢用while,略略略~
#*************************希尔排序(by_teacher)***************************
def Shell_sort2(L):
n=len(L)
gap=n//2 #设置gap步长
print("希尔排序之前:",L)
while gap>=1:
for i in range(gap,n):#插入排序的遍历次数(对于此gap下)
for j in range(i,0,-gap):
if L[j]<L[j-gap]:
L[j],L[j-gap]=L[j-gap],L[j]
gap//=2
print("希尔排序之后:",L)
结果展示
希尔排序之前: [2, 6, 1, 3, 0, 4, 8, 5]
希尔排序之后: [0, 1, 2, 3, 4, 5, 6, 8]时间复杂度
关于希尔排序,其实本质上就是插入排序的升级版,所以当你取gap=1时它就是插入排序,所以最坏的时间复杂度就是O(n^2)
最好的时间复杂度取决于gap的选择
稳定性
虽然插入排序是稳定的,但是希尔排序却不是,因为希尔排序实现对子序列进行排序,也就是对于每一个gap,都是把各个子序列排好序,比如
12,94,77,77,89,1
取gap=2,那么两个子序列:
12,77(前面的77),89
94,77(后边的77),1
对于第二个子序列,插入排序之后,77(后面的)就会跑到第一个位置
而第一个子序列的77(前面的)仍然在原来的位置
这样一来当gap=1插入排序时原序列后面的77就会比原序列前面的77位于更前的位置,所以该算法不稳定
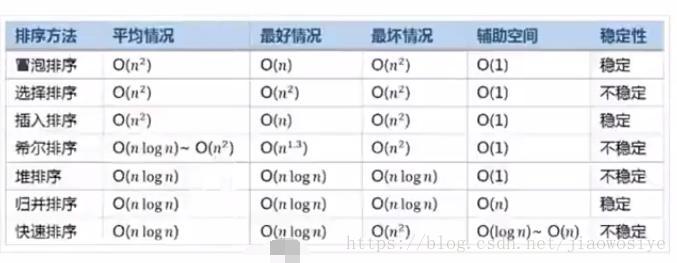
排序算法比较
最后三个(堆排序,归并排序,快速排序)接下来就会有啦