文章目录
一、数据库的介绍
1.数据库简介





从以上几幅图可以看到,数据存储经历了从口口相传、结绳记事、用龟片或贝壳、用竹简、青铜器、纸(莎纸、羊皮)到软盘、光盘、硬盘文件等漫长的发展,存储的内容越来越多,便捷性和持久性也越来越高。
传统数据记录和存储的缺点:
- 不便于保存,易丢失;
- 备份困难;
- 查找不便。
现代文件存储方式虽然在很大程度上克服了上面的困难,但还是存在一定缺陷:
- 文件较大时,查询、写入、修改等方面的性能会大大降低;
- 不易扩展
不同编程语言操作文件的方式不同,如果切换语言操作文件会很不方便,扩展性较低。
数据库的特点:
- 持久化存储
数据存储到本地,不易丢失 - 读写速度极高
- 保证数据的有效性
保证各个字段的类型正确,值有意义。 - 对程序支持性非常好,容易扩展
我们在网站或者应用软件是看到的具有美观格式的数据其实都是通过查询后端数据库并使用特定格式渲染出来的。
对数据库简单直白的理解:
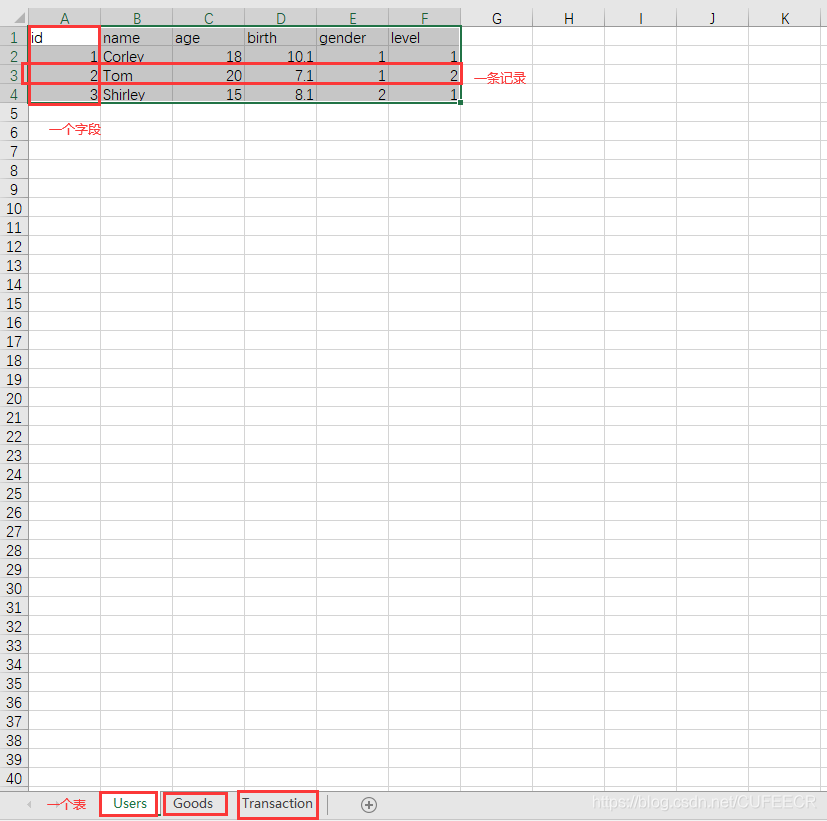
一个Excel可以理解为一个数据库,一个Sheet可以裂解为一个表,一个表的字段可以理解为表头,即一列对应一个字段,一行数据表示一条记录。同时不同的表中的数据还可以产生关系,如外键,如下图:
2.MySQL介绍
MySQL是一个关系型数据库,由瑞典MySQL AB公司开发,后来被Sun公司收购,Sun公司后来又被Oracle公司收购,目前属于Oracle旗下产品。
MySQL的特点
- 使用C和C++编写,并使用了多种编译器进行测试,保证源代码的可移植性
- 支持多种操作系统,如Linux、Windows、AIX、FreeBSD、HP-UX、MacOS、NovellNetware、OpenBSD、OS/2 Wrap、Solaris等
- 为多种编程语言提供了API,如C、C++、Python、Java、Perl、PHP、Eiffel、Ruby等
- 支持多线程,充分利用CPU资源
- 优化的SQL查询算法,有效地提高查询速度
- 提供多语言支持,常见的编码如GB2312、BIG5、UTF8
- 提供TCP/IP、ODBC和JDBC等多种数据库连接途径
- 提供用于管理、检查、优化数据库操作的管理工具
- 大型的数据库
可以处理拥有上千万条记录的大型数据库 - 支持多种存储引擎
- MySQL 软件采用了双授权政策,它分为社区版和商业版,由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型网站的开发都选择MySQL作为网站数据库
- MySQL使用标准的SQL数据语言形式
- Mysql是可以定制的,采用了GPL协议,你可以修改源码来开发自己的Mysql系统
- 在线DDL更改功能
- 复制全局事务标识
- 复制无崩溃从机
- 复制多线程从机
关于MySQL数据库的更多内容可参考Python全栈(三)数据库优化之1.数据库简介。
3.MySQL数据库的安装
服务端安装
服务端用于开启MySQL服务。
- 官网下载安装
访问官网下载,但是可能很慢 - 集成工具安装
通过phpStudy等安装。
可点击https://download.csdn.net/download/CUFEECR/12340408下载phpstudy并安装。
客户端安装使用
- CMD
- 可视化工具
- sqlyog
- navicat
sqlyog可点击https://download.csdn.net/download/CUFEECR/12340815下载,解压后按照说明安装。
在SQLYog中创建数据库、表和插入数据的演示如下:

新版Flask支持的MySQL版本必须大于等于5.5。
关于数据库安装的更多内容可参考Python全栈(三)数据库优化之1.数据库简介。
二、SQLAlchemy介绍和基本使用
1.SQLAlchemy简介
数据库是一个网站的基础,Flask可以使用很多种数据库,如MySQL、MongoDB、SQLite、PostgreSQL等。这里使用MySQL。
在Flask中,如果想要操作数据库,可以使用ORM,使用ORM操作数据库使数据库交互变得非常简单方便。
Flask操作数据库,需要先安装一些所需的库;
安装时,先进入虚拟环境所在目录,如果未切换到虚拟环境需要通过命令pipenv shell进入虚拟环境。
需要安装的库如下:
- pymysql
pymysql是用Python来操作mysql的库,通过命令pip install pymysql进行安装。 - SQLAlchemy
SQLAlchemy是一个数据库的ORM框架,通过命令pip install SQLAlchemy安装。 - mysql-connector
用于通过Python连接数据库,安装命令为pip install mysql-connector和pip install mysql-connector-python。
2.SQLAlchemy的基本使用
使用sqlalchemy执行原生SQL语句示例如下:
from sqlalchemy import create_engine
# 主机地址
HOSTNAME = '127.0.0.1'
# 数据库
DATABASE = 'flask_demo'
# 端口号,一般固定,默认为3306
PORT = 3306
# 用户名和密码
USERNMAE = 'root'
PASSWORD = 'root'
# 创建数据库引擎
DB_URL = 'mysql+pymysql://{}:{}@{}:{}/{}'.format(USERNMAE, PASSWORD, HOSTNAME, PORT, DATABASE)
engine = create_engine(DB_URL)
# 创建连接
with engine.connect() as conn:
# 执行原生SQL语句
result = conn.execute("select * from users")
print(result.fetchone())
首先用sqlalchemy导入的函数create_engine()创建引擎实例,其中传入该函数的参数形式为:
dialect+driver://username:password@host:port/database?charset=utf8
其中,dialect是数据库的类型,比如MySQL、PostgreSQL、SQLite等,并且转换成小写;
driver是Python中操作对应数据库的驱动,如果不指定,会选择默认的驱动,比如MySQL的默认驱动是MySQLdb;
username是连接数据库的用户名;
password是该用户的密码;
host是连接数据库的域名;
port是数据库监听的端口号;
database是需要连接的数据库的名字。
再调用该实例的connect()方法连接数据库,使用with语句连接数据库,如果发生异常会被捕获。
运行结果如下:
XXX\Python\Python37\lib\site-packages\pymysql\cursors.py:170: Warning: (1366, "Incorrect string value: '\\xD6\\xD0\\xB9\\xFA\\xB1\\xEA...' for column 'VARIABLE_VALUE' at row 485")
result = self._query(query)
(1, 'cl', 'corley', '123')
查询到了第一条数据,但是同时有一条警告消息,这是创建数据库引擎时使用的DB_URL产生的问题,猜测可能是MySQL驱动的问题,可以将pymysql连接数据库换成官方的连接引擎,即使用之前安装的mysql-connector来解决这个问题,如下:
from sqlalchemy import create_engine
# 主机地址
HOSTNAME = '127.0.0.1'
# 数据库
DATABASE = 'flask_demo'
# 端口号,一般固定,默认为3306
PORT = 3306
# 用户名和密码
USERNMAE = 'root'
PASSWORD = 'root'
# 创建数据库引擎
DB_URL = 'mysql+mysqlconnector://{}:{}@{}:{}/{}'.format(USERNMAE, PASSWORD, HOSTNAME, PORT, DATABASE)
engine = create_engine(DB_URL)
# 创建连接
with engine.connect() as conn:
# 执行原生SQL语句
result = conn.execute("select * from users")
for r in result:
print(r)
打印:
(1, 'cl', 'corley', '123')
(2, 'tn', 'tony', '12345')
显然,此时未出现警告信息。
执行更多原生SQL语句测试如下:
先在Python文件同级目录下创建文件constants.py,将之前文件中数据库配置选项的常量都放入该文件中,如下:
# 主机地址
HOSTNAME = '127.0.0.1'
# 数据库
DATABASE = 'flask_demo'
# 端口号,一般固定,默认为3306
PORT = 3306
# 用户名和密码
USERNMAE = 'root'
PASSWORD = 'root'
DB_URL = 'mysql+mysqlconnector://{}:{}@{}:{}/{}'.format(USERNMAE, PASSWORD, HOSTNAME, PORT, DATABASE)
同时编辑执行原生SQL语句的Python文件如下:
from sqlalchemy import create_engine
from constants import DB_URL
# 创建数据库引擎
engine = create_engine(DB_URL)
# 创建连接
with engine.connect() as conn:
# 判断表存在则删除
conn.execute("drop table if exists staffs")
# 创建表
conn.execute("create table staffs(id int primary key auto_increment, name varchar(30), salary int)")
# 插入数据
conn.execute("insert into staffs values(default,'Corley', 10000),(default, 'Tony', 8000)")
# 查询数据
results = conn.execute("select * from staffs")
# 显示数据
for result in results:
print(result)
运行之后,打印:
(1, 'Corley', 10000)
(2, 'Tony', 8000)
三、ORM介绍和SQLAlchemy的使用
1.ORM介绍
随着项目规模的增大,采用原生SQL的方式会导致代码中大量的SQL语句,并对项目的进展产生不利影响:
- 代码复用率较低
SQL语句较多,重复率较高,复用性较低,越复杂的SQL语句条件越多,代码会越来越多。 - 修改不方便
很多SQL语句是在业务逻辑中拼出来的,如果数据库需要更改,就要去修改这些代码逻辑,很容易漏掉或增加某些SQL语句的修改 - 安全性受影响
原生的SQL语句SQL注入的风险较大。
此时我们可以选择ORM进行优化。
ORM(Object Relationship Mapping),即对象关系映射,通过ORM,我们可以使用类和对象的方式去操作数据库,而不用写原生的SQL语句。
通过把表映射成类,把字段作为属性,把行作为实例,ORM在执行对象操作时最终把对应的操作转换为数据库的原生语句。
ORM的优点如下:
- 易用性
使用ORM进行数据库开发可以有效减少SQL语句,写出来的模型也更加直观。 - 性能损耗小
- 设计灵活
可以更轻松地写出复杂的查询语句。 - 可移植性
SQLAlchemy封装了底层的数据库实现,支持多个关系型数据库,包括MySQL、SQLite等。
模型通过ORM再转到数据库中操作,执行过程如下:

2.SQLAlchemy的简单使用
要使用ORM来操作数据库,首先需要创建一个类来与对应的表进行映射。
在类中先定义表名,再定义字段,定义字段要用Column实例化后的对象实例。
Column()实例化时的参数中,第一个是数据类型,剩下的是约束;
如果类型是String时,必须指定字符串最大长度。
使用ORM创建表示例如下:
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
# 主机地址
HOSTNAME = '127.0.0.1'
# 数据库
DATABASE = 'flask_demo'
# 端口号,一般固定,默认为3306
PORT = 3306
# 用户名和密码
USERNMAE = 'root'
PASSWORD = 'root'
# 创建数据库引擎
DB_URL = 'mysql+mysqlconnector://{}:{}@{}:{}/{}'.format(USERNMAE, PASSWORD, HOSTNAME, PORT, DATABASE)
engine = create_engine(DB_URL)
# 继承declarative_base函数生成的基类
Base = declarative_base(engine)
# ORM操作数据库
class Students(Base):
# 指定数据库中的表
__tablename__ = 'students'
# 给定字段
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(50), nullable=False)
gender = Column(Integer, default=1,comment='1为男,2为女')
# 格式化打印,打印当前对象时会调用
def __repr__(self):
return "<User(id='%s', name='%s', fullname='%s', password='%s')>" % (self.id, self.name, self.fullname, self.password)
# 模型映射到数据库中
Base.metadata.create_all()
SQLAlchemy会自动为第一个类型为Integer、标记为主键并且没有被标记为外键的字段添加自增长的属性,因此以上例子中定义id字段时使用id = Column(Integer, primary_key=True)语句即不设置autoincrement属性也会自动让id自增;
创建类时,要使所有的类都要继承自declarative_base()函数生成的基类。
创建完和表映射的类后,还没有真正的映射到数据库当中,需要执行代码Base.metadata.create_all()才能将类映射到数据库中。
运行后查看sqlyog,刷新后可以看到:

显然,students表已经创建成功。
