一、队列和队列的实现
1.定义
特点:先进者先出。
操作:
入队enqueue:放一个数据到队列尾部;
出队dequeue:从队列头部取一个元素。
队列也是一种操作受限制的线性表数据结构。
包括一些额外特性的队列,比如循环队列、阻塞队列、并发队列等,在很多偏底层系统、框架、中间件的开发中起着关键作用。
2.队列的实现
队列的实现也是用顺序表list来实现,相关操作与list的操作相关,实现如下,
class Queue(object):
def __init__(self):
'''初始化'''
self.__items = []
def enqueue(self,item):
'''
:param item:向队列中添加一个item元素
:return: None
'''
self.__items.append(item)
def dequeue(self):
'''
:param item
:return:第一个元素
'''
self.__items.pop(0)
def is_empty(self):
'''
判断一个队列是否为空
:return: True or False
'''
return self.__items == []
def size(self):
'''
:return:队列中的元素个数
'''
return len(self.__items)
def travel(self):
'''
遍历
:return:
'''
for item in self.__items:
print(item)
q = Queue()
print(q.is_empty())
q.enqueue(1)
q.enqueue(2)
q.enqueue(3)
q.travel()
q.dequeue()
q.dequeue()
q.travel()
print(q.size())
并进行测试,打印结果为,
1
2
3
3
1
3.双端队列及其实现
全名double-ended queue,一种具有队列和栈的性质的数据结构。
结构如图,
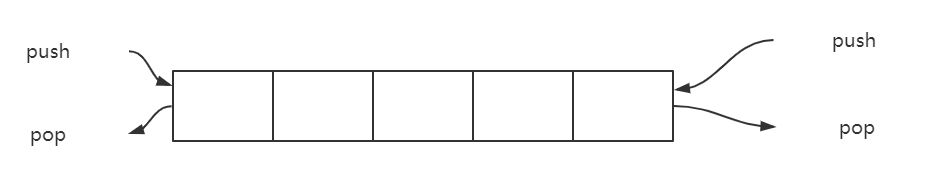
元素可以从两端弹出,其限定插入和删除操作在队列的两端进行,可以在队列任意一端入队和出队。
实现与队列类似,
class Deque(object):
'''双端队列'''
def __init__(self):
self.__items = []
def is_empty(self):
'''判断双端队列是否为空'''
return self.__items == []
def size(self):
'''
返回队列中的元素个数
:return:
'''
return len(self.__items)
def add_front(self,item):
'''从队头添加一个item元素'''
self.__items.insert(0,item)
def add_rear(self,item):
'''从队尾添加一个元素'''
self.__items.append(item)
def remove_front(self):
'''从队尾删除一个元素'''
return self.__items.pop(0)
def remove_rear(self):
'''从队尾删除一个元素'''
return self.__items.pop()
def travel(self):
'''
遍历
:return:
'''
for item in self.__items:
print(item)
if __name__ == '__main__':
d = Deque()
print(d.is_empty())
d.add_front(1)
d.add_rear(2)
d.travel()
d.remove_front()
print(d.remove_rear())
print(d.size())
进行测试,打印结果为,
True
1
2
2
0
4.阻塞队列:
input()函数调用时等待输入,即为阻塞。
阻塞队列在队列基础上增加了阻塞操作:
在队列为空的的时候,从队头取数据会被阻塞,因为此时还没有数据可取,直到队列中有了数据才能返回;
如果队列已经满了,那么插入数据的操作就会被阻塞,直到队列中有空闲位置后再插入数据,然后再返回。
应用:CPU资源分配:
CPU资源是有限的,任务的处理速度与线程个数并不是线性正相关。相反,过多的线程反而会导致CPU频繁切换,处理性能下降。所以,线程池的大小一般都是综合考虑要处理任务的特点和硬件环境,来事先设置的。
如果采用链表:无限排队的无界队列 响应时间,比较敏感不合适;
如果采用顺序表:有界的队列 如果超过 直接拒绝 响应时间 敏感比较合适。
二、排序算法的分析
1.排序算法简介
最经典的排序算法:
冒泡排序
插入排序
选择排序
归并排序
快速排序
希尔排序
分析排序算法的角度:
※算法的执行效率:
▲时间复杂度;
▲比较次数和交换(移动)次数。
※排序算法的内存消耗:
原地排序算法:特指时间复杂度为O(1)的排序算法。
※排序算法的稳定性:
稳定性是指,如果待排序的序列中存在值相等的元素,经过排序之后,相等元素之间原有的先后顺序不变。
2.递归回顾
递归是一种算法,很对数据结构和算法的实现都要用到算法,如DFS深度优先搜索、前中后序二叉树遍历等。
递归的三个条件:
- 一个问题的解可以分成几个子问题的解;
- 这个问题与分解之后的子问题,除了数据规模,求解思路完全一样;
- 存在递归终止条件。
在Python中,递归最大深度为1000,超过1000会抛出异常。
简单举例:
def f(n):
if n == 1:
return 1
else:
return f(n - 1) + 1
print(f(5))
打印5
再如
def factorial(n):
'''阶乘'''
if n == 1:
return 1
else:
return factorial(n - 1) * n
print(factorial(20))
打印2432902008176640000。
用递归的方式输出l=[‘jack’,(‘tom’,23),27,‘rose’,(14,55,67)]列表中内的每一个元素输出:
def list_p(l):
if isinstance(l,(str,int)):
print(l)
else:
for item in l:
list_p(item)
l=['jack',('tom',23),27,'rose',(14,55,67)]
list_p(l)
会打印
jack
tom
23
27
rose
14
55
67
3.冒泡排序:
冒泡排序(Bubble Sort),重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
实现思路:
- 比较相邻的元素,如果第一个比第二个大(升序),就交换他们两个;
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数;
- 针对所有的元素重复以上的步骤,除了最后一个;
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
用直观的图形分析如下,

进行一次循环后,会对除了最后一个元素的其他元素进行第二次循环,再比较,直到完全有序。
用更形象的动图分析,
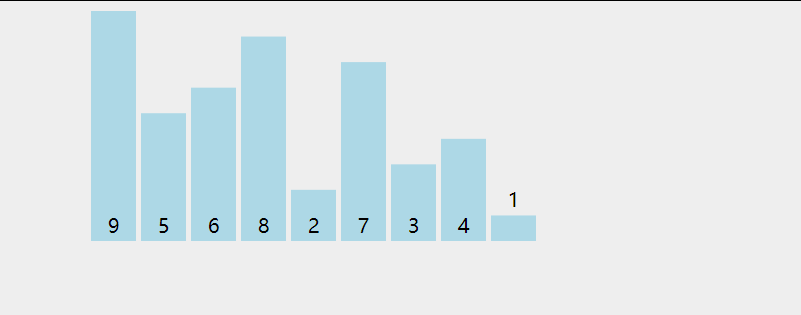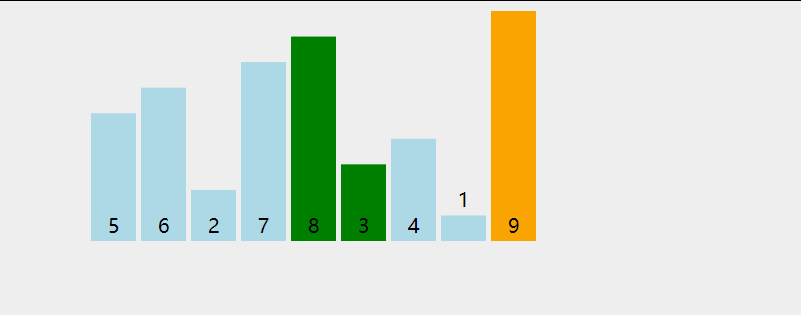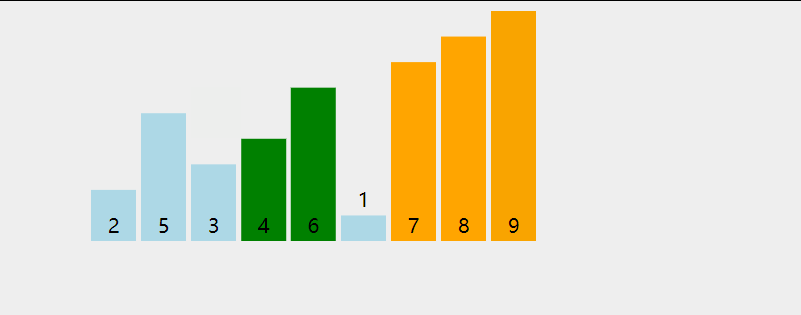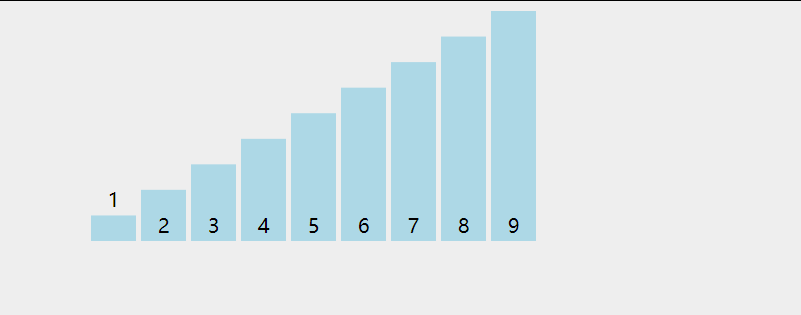
实现:
方法一:
def bubble_sort_1(alist):
'''用循环控制,冒泡排序'''
for o in range(len(alist)-1,0,-1):
for i in range(o):
if alist[i] > alist[i+1]:
alist[i],alist[i+1]=alist[i+1],alist[i]
if __name__ == '__main__':
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
bubble_sort_1(li)
print(li)
打印[17, 20, 26, 31, 44, 54, 55, 77, 93]。
方法二:
def bubble_sort_2(alist):
n = len(alist)
#外层循环控制循环的次数
for o in range(len(alist)-1):
#内层循环为当前循环,i为所需比较的次数
for i in range(n - 1 - o):
if alist[i] > alist[i+1]:
alist[i],alist[i+1]=alist[i+1],alist[i]
if __name__ == '__main__':
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
bubble_sort_2(li)
print(li)
结果与方法一相同。
方法三:用递归实现
def bubble_sort_3(alist):
'''递归实现'''
n = len(alist)
flag = True
for i in range(n - 1):
if alist[i] > alist[i + 1]:
flag = False
break
else:
continue
if flag:
return alist
else:
for i in range(n - 1):
if alist[i] > alist[i+1]:
alist[i],alist[i+1]=alist[i+1],alist[i]
return bubble_sort_3(alist[:-1]) + [alist[-1]]
if __name__ == '__main__':
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
new_list = bubble_sort_3(li)
print(new_list)
打印结果为[17, 20, 26, 31, 44, 54, 55, 77, 93],与前两种方法相同,但是前两种方法是直接对原列表进行操作,使列表成为有序,原列表被改变,不带返回值,用递归实现的方法使被操作后的列表返回,返回有序的列表,是带有返回值的。
冒泡排序的分析:
- 冒泡排序是稳定的:
在冒泡排序中,只有交换才可以改变两个元素的前后顺序。为了保证冒泡排序算法的稳定性,当有相邻的两个元素大小相等的时候,我们不做交换,相同大小的数据在排序前后不会改变顺序,所以冒泡排序是稳定的排序算法。 - 时间复杂度:
最好情况下,要排序的数据已经是有序的了,只需要进行一次冒泡操作进行比较,就结束了,所以最好情况时间复杂度是O(n);而最坏的情况是,要排序的数据刚好是倒序排列的,我们需要进行n次冒泡操作,所以最坏情况时间复杂度为O(n2)。

大家也可以关注我的公众号:Python极客社区,在我的公众号里,经常会分享很多Python的文章,而且也分享了很多工具、学习资源等。另外回复“电子书”还可以获取十本我精心收集的Python电子书
