文章目录
一、快速排序
1.定义
又称划分交换排序(partition-exchange sort),通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
2.工作原理
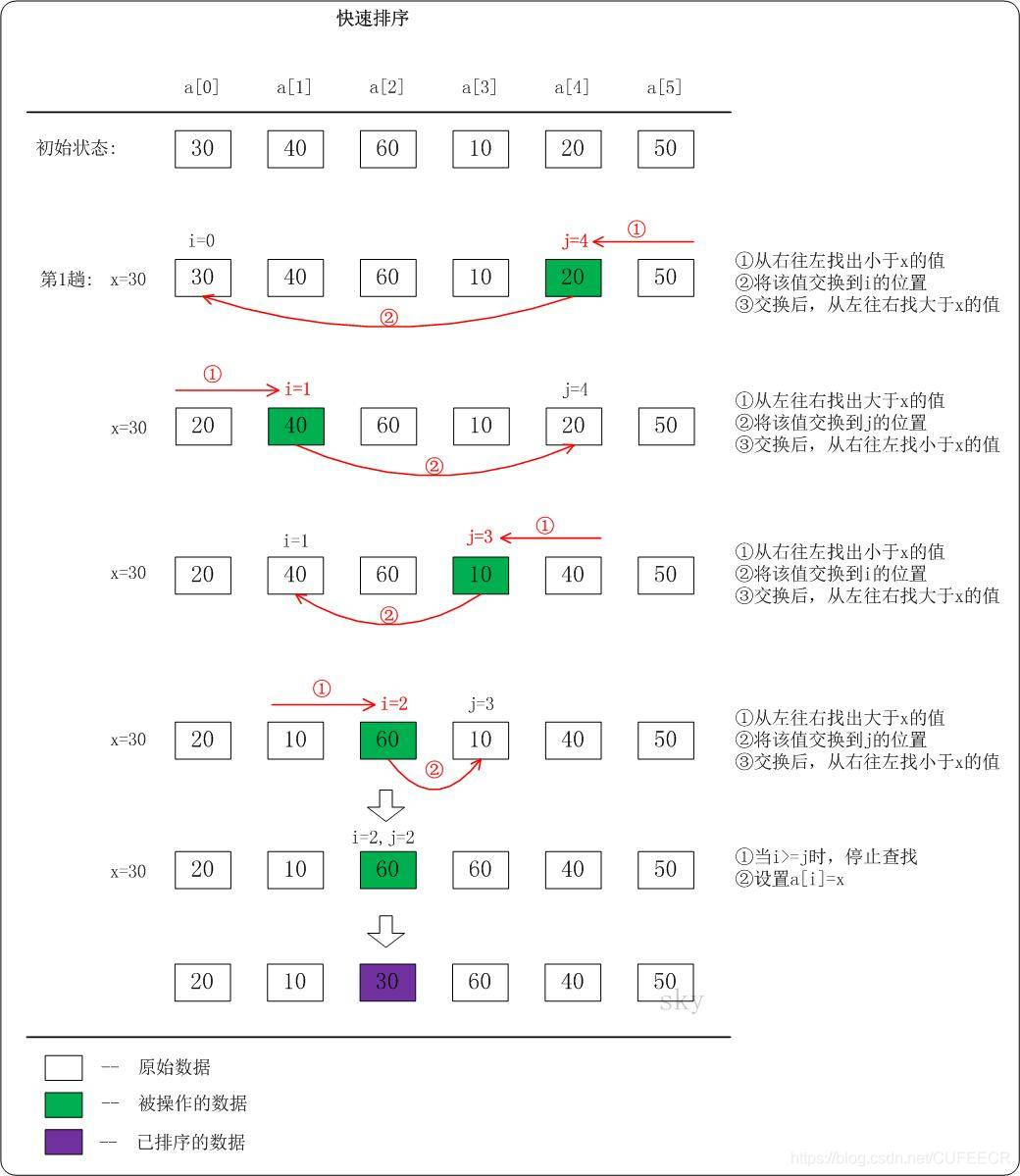
- 从数列中挑出一个元素,称为"基准"(pivot);
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会结束,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
图示分析如图,
动态演示如下,
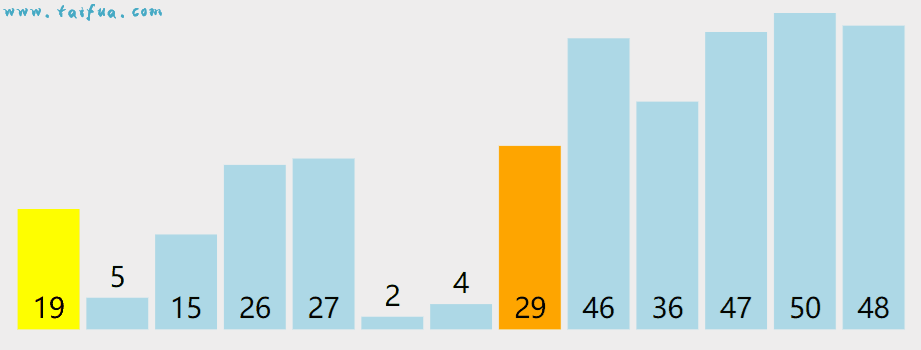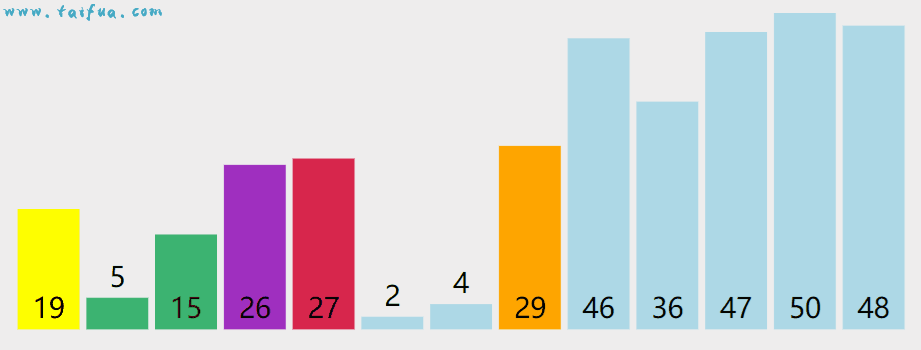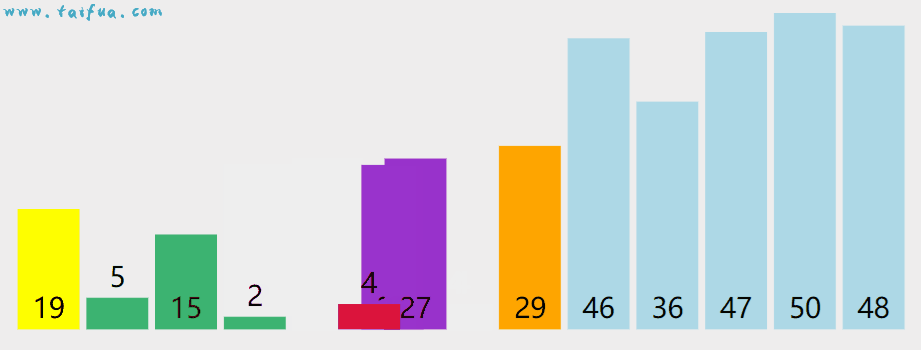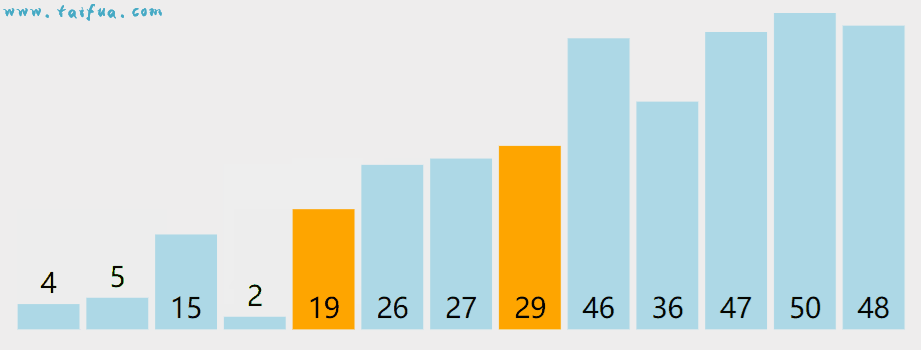
3.算法实现
def quick_sort(li,start,end):
'''快速排序'''
# 递归的退出条件
if start >= end:
return
low = start
high = end
# 设定起始元素为要寻找位置的基准元素
mid = li[low]
while low < high:
# 如果low与high未重合,high指向的元素不比基准元素小,则high向左移动
while low < high and li[high] >= mid:
high -= 1
# 将high指向的元素放到low的位置上
li[low] = li[high]
# 如果low与high未重合,low指向的元素比基准元素小,则low向右移动
while low < high and li[low] <= mid:
low += 1
# 将low指向的元素放到high的位置上
li[high] = li[low]
# 退出循环后,low与high重合,此时所指位置为基准元素的正确位置
# 将基准元素放到该位置
li[low] = mid
#对前面的元素进行快排
quick_sort(li,start,low - 1)
#对后面的元素进行快排
quick_sort(li,low + 1,end)
if __name__ == '__main__':
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
quick_sort(li,0,len(li) - 1)
print(li)
进行测试,结果为[17, 26, 31, 54, 54, 54, 55, 77, 93]。
4.算法分析
时间复杂度:
最优的情况下空间复杂度为:O(logN);
最差的情况下空间复杂度为:O(N^2)。
稳定性:
因为在快速排序的时候,即使待排序元素与基数相等也需要移动待排序元素的位置使得有序,所以快速排序是不稳定的。
二、归并排序
1.定义
归并排序是采用分治法的一个非常典型的应用,即分而治之。归并排序的思想就是先递归分解数组,再合并数组。
2.工作原理
将数组分解最小之后,然后合并两个有序数组,基本思路是比较两个数组的最前面的数,谁小就先取谁,取了后相应的指针就往后移一位。然后再比较,直至一个数组为空,最后把另一个数组的剩余部分复制过来即可。
动态演示为

3.算法实现
方法一:
def merge_sort(li):
'''归并排序'''
# 如果列表长度小于1,不在继续拆分,返回列表
if len(li) <= 1:
return li
#二分分解
mid_index = len(li) // 2
left_li = merge_sort(li[:mid_index])
right_li = merge_sort(li[mid_index:])
l_index = 0
r_index = 0
result = []
#循环条件
while l_index < len(left_li) and r_index < len(right_li):
#left_li和right_li的当前元素进行比较,根据情况分别插入result,索引加1
if left_li[l_index] < right_li[r_index]:
result.append(left_li[l_index])
l_index += 1
else:
result.append(right_li[r_index])
r_index += 1
#将left_li剩余部分加入数组
result += left_li[l_index:]
#将right_li剩余部分加入数组
result += right_li[r_index:]
#返回结果
return result
if __name__ == '__main__':
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
result = merge_sort(li)
print(result)
进行测试,打印结果为[17, 20, 26, 31, 44, 54, 55, 77, 93]。
方法二:
def merge_sort(li):
# 如果列表长度小于1,不在继续拆分
if len(li) <= 1:
return li
# 二分分解
mid_index = len(li) // 2
left = merge_sort(li[:mid_index])
right = merge_sort(li[mid_index:])
# 合并
return merge(left,right)
def merge(left, right):
'''合并操作,将两个有序数组left[]和right[]合并成一个大的有序数组'''
# left与right的下标指针
l_index, r_index = 0, 0
result = []
while l_index < len(left) and r_index < len(right):
if left[l_index] < right[r_index]:
result.append(left[l_index])
l_index += 1
else:
result.append(right[r_index])
r_index += 1
result += left[l_index:]
result += right[r_index:]
return result
if __name__ == '__main__':
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
result = merge_sort(li)
print(result)
结果与方法一相同,但是此方法是分成两个子方法来实现,第一个函数进行分解,第二个函数进行合并,实质和方法一一样,只是形式不同。
4.算法分析
时间复杂度:
每次合并操作的时间复杂度是O(N),而递归的深度是log2N,所以总的时间复杂度是O(N*lgN)。
稳定性:
因为交换元素时,可以在相等的情况下做出不移动的限制,所以归并排序是稳定的。
5.常见排序算法效率比较
如下所示,

三、二分查找
1.搜索定义
搜索是在一个项目集合中找到一个特定项目的算法过程。搜索通常的答案是真的或假的,因为该项目是否存在。 搜索的几种常见方法:顺序查找、二分法查找、二叉树查找、哈希查找。
2.二分查找定义
二分查找又称折半查找,优点是比较次数少,查找速度快,平均性能好;其缺点是要求待查表为有序表,且插入删除困难。因此,折半查找方法适用于不经常变动而查找频繁的有序列表。
3.工作原理
- 首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;
- 否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表;
- 重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
图示如下,

4.算法实现
方法一,
def binary_search_1(li,item):
'''普通二分查找'''
first = 0
last = len(li) - 1
while first <= last:
mid = (first + last) // 2
if li[mid] == item:
return True
elif item < li[mid]:
last = mid - 1
else:
first = mid + 1
return False
if __name__ == '__main__':
#li为有序列表
li = [17, 20, 26, 31, 44, 54, 55, 77, 93]
result1 = binary_search_1(li, 17)
result2 = binary_search_1(li, 54)
result3 = binary_search_1(li, 100)
print(result1,result2,result3)
打印结果为True True False。
方法二,
def binary_search_2(li,item):
'''递归实现二分查找'''
if len(li) == 0:
return False
else:
mid = len(li) // 2
if li[mid] == item:
return True
else:
if item < li[mid]:
return binary_search_2(li[:mid],item)
else:
return binary_search_2(li[mid+1:],item)
if __name__ == '__main__':
#li为有序列表
li = [17, 20, 26, 31, 44, 54, 55, 77, 93]
result1 = binary_search_2(li, 17)
result2 = binary_search_2(li, 54)
result3 = binary_search_2(li, 100)
print(result1,result2,result3)
此方法为递归方法实现,结果与方法一相同。
5.算法分析
二分查找算法,在n个元素的数组中查找一个数,情况最遭时,需要(log2n)步,所以二分查找的时间复杂度是O(log2n)。

大家也可以关注我的公众号:Python极客社区,在我的公众号里,经常会分享很多Python的文章,而且也分享了很多工具、学习资源等。另外回复“电子书”还可以获取十本我精心收集的Python电子书。
