1. 索引干啥的
加快查询效率!!
帮助mysql高效获取数据结构
2. 索引怎么用
-- 添加索引
ALTER TABLE `test` ADD INDEX `n_uid_title` (`uid`, `title`) USING BTREE ;
-- 删除索引
ALTER TABLE `test` DROP INDEX `n_uid_title` ;
3. 索引存在哪儿
磁盘 ? 内存 ? 当然是磁盘了~
sql查询的时候 会把磁盘中索引加载到内存。
4. Mysql 简单架构
客户端->服务端
服务端:连接器-》分析器-》优化器-》执行器
存储引擎:InnoDB MyISAM memory

5. 知识点
不同的存储引擎,数据文件与索引文件存储的位置不同,因此有了分类:
- 聚簇索引
数据和索引放在一起
*.frm 存放的是表结构
*.idb 存放的是数据文件和索引文件
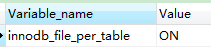
show VARIABLES like '%per_table%'
mysql innodb 默认情况下会把所有数据放到表空间中(表空间就是一个数据库的概念)
不会为每一个表保存一份数据文件 ,如果需要单独使用文件保存
需要设置innodb_file_per_table=ON
- 非聚簇索引
数据和索引单独一个文件
*.frm 存放表结构
*.MYI 存放索引数据
*.MYD 存放实际数据
6. 哈希表做索引?

- 每一个块对应着一条记录
- 每次添加索引的时候需要计算指定hash值,取模运算后计算出下标
将元素插入指定位置即可 - 适合场景 : 等值查询
- 不适合:范围查询 因为企业大部分都是范围查询 所以…
- hash使用的时候 要全部加载到内存中 比较耗费内存 所以…
7. 树 做索引?
在树的结构中,左子树小于根节点,右子树大于根节点,如果是多叉树,从左到右是有序的
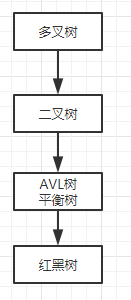
1. AVL树是一棵严格意义上的平衡树,
最高子树根最低子树高度指差不能超过1,
因此在进行元素插入的时候,会进行1到N此旋转
严重影响插入性能
2. 红黑树 是基于AVL数的一个升级 损失了部分查询的性能 来提升插入的性能
- 在红黑树中最低子树与最高子树之差小于**2倍**即可
- 最低子树是5层 最高子树是10层 不能再高
- 这样的话 在插入的时候 不会进行多次旋转
- 还采用了变色的特性,来满足插入和查询性能的权衡
- 2倍 还是有可能一个腿长 一个腿短
3. 二叉树及其变种 无法支撑索引 原因是深度无法控制 或者是 插入性能低
4. B树 本质是多叉树
- 所有节点分布在整棵树中
- 搜索有可能在非子节点结束,在关键字全局内做一次查找,性能逼近二分查找
- 每个非叶子节点最多拥有m个子树 M>2
- 根节点儿子数[2,m]
- 分支节点儿子数为[M/2, M];
- 所有叶子节点 都在同一层
- 每个节点最多有m-1个key 并且以升序排序
- 自动层次控制;
- 由于M/2的限制,在插入结点时,
如果结点已满,需要将结点分裂为两个各占M/2的结点;
删除结点时,需将两个不足M/2的兄弟结点合并;

查询过程:
-- 比如上图 这里只是示意图 不一定实时是这样 可能格子更多或更少
-- 我要查27这个索引对应的数据
1. 读取磁盘1 27大于16 且 小于34
2. 根据p2 找到磁盘3 27 大于24 且 小于 33
3. 根据p2 找到磁盘8 找到27
4. 三次IO 读事件
缺点:
1. 每个节点都包含key 和 与之对应的data值 而每个存储节点大小是有限的
如果data比较大的话 会导致每个节点存储的条数变小
2. 当存储量越来越大时。书的深度就会越来越深 增大查询时IO次数,影响查询性能
4. **B+树 **
4.1 基础
- 非叶子节点 只存储指针+主键
- 叶子节点存储数据

查找过程:
--查找 24
1. 磁盘1
2. p2 找到磁盘2
3. p2 找到磁盘8
4. 查找成功
5. 三次IO读操作
之前一个磁盘块能存储10个键值的话,现在就能存储100个
甚至更多 这样数的深度就不会很大
注意: B+Tree 有两个头指针 ,一个指向根节点,一个指向关键字最小的叶子节点
而且所有叶子节点(既数据节点)之间是一种链式结构
因此B+Tree进行2中查找方式 :
1. 对主键范围查找和分页查找
2. 从根节点开始 进行随机查找
4.2 Innodb 回表
-- ----------------------------
-- Table structure for t_hh
-- ----------------------------
DROP TABLE IF EXISTS `t_hh`;
CREATE TABLE `t_hh` (
`id` bigint(20) NOT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of t_hh
-- ----------------------------
INSERT INTO `t_hh` VALUES ('1', '马化腾');
INSERT INTO `t_hh` VALUES ('2', '马云');
INSERT INTO `t_hh` VALUES ('3', '许家印');
INSERT INTO `t_hh` VALUES ('4', '李兆基');
INSERT INTO `t_hh` VALUES ('5', '李嘉诚');
INSERT INTO `t_hh` VALUES ('6', '杨惠妍');
如果只有主键:结构是这样的

MyISAM 与InnoDB唯一的不同是,MyISAM的数据文件与索引文件不是放在一起
MyISAM 索引到数据之后 还需要根据数据地址去查找数据
MyISAM没有听说过回表。

我要搜索主键为4的人
1. 磁盘1 找到p2
2. 根据p2 找到磁盘3
3. 找到4 李兆基 返回数据 --2次IO
如果name是索引列:结构是这样的

我要搜索杨惠妍
1. 磁盘1 找到p2
2. 根据p2找到 磁盘3
3. 找到杨惠妍 拿到对应的主键(可能是唯一索引 也可能是数据库偷偷生成的row_id)
4. 拿着id=6 去走一次 只有主键的那个流程
5. 磁盘1 找到p3
6. 根据p3 找到磁盘4
7. 找到6 杨惠妍 返回数据 --4次IO
很难理解 为什么需要回表
因为:索引对应的数据 只能找到主键(或者是唯一索引) ,
没有具体或者说实际的行对象数据,
而主键对应的那个结构中的数据 就是行数据
这样可能只是为了数据存储一次吧 不复制多份存储
解释:
1. 在InnoDB中,通过B+Tree结构对主键创建索引,
然后叶子节点存储记录,
如果没有主键,会选择唯一键,
如果没有唯一键,那么会生成一个6位的row_id来作为主键
2. 如果创建索引的键是其他字段,那么在叶子节点中存储的记录就是主键
搜索到主键之后,再根据主键搜索实际的数据 (回表)
4.3 推荐学习数据结构网站
https://www.geeksforgeeks.org
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
https://visualgo.net/zh
4.4 b树 跟b+树 还不是很明白 准备下去好好看看 写个笔记记一下
待续…
