EAST-model.py
前言
因为一些学习需要最近正在学习EAST算法,前期学习只有TensorFlow搭建卷积神经网络的经验,所以学习比较吃力,于是决定一步步学习EAST-master代码,下面是自己对代码的学习,及各个函数的解析。本文主要是对代码中的model部分进行解释。下图是model结构。
import
import tensorflow as tf
import numpy as np
from tensorflow.contrib import slim
tf.app.flags.DEFINE_integer('text_scale', 512, '')
from nets import resnet_v1
此处是对基本库的调用,代码编写用到TensorFlow和numpy的函数需要引入,slim涉及到对图片的处理后面会谈到,rensent-v1是我们用来提取特征的神经网络。为model图片的左边部分。
unpool
def unpool(inputs):
return tf.image.resize_bilinear(inputs, size=[tf.shape(inputs)[1]*2, tf.shape(inputs)[2]*2])
此处部分为反卷积操作,和池化操作相反反卷积实现的是将样本大小翻倍。此处用tf.image.resize_bilinear函数实现,下面介绍一下这个函数。
tf.image.resize_bilinear(
images,
size,
align_corners=False,
name=None
)
images:一个Tensor,必须是下列类型之一:int8,uint8,int16,uint16,int32,int64,bfloat16,half,float32,float64;4维的并且具有形状[batch, height, width, channels].
size:2个元素(new_height, new_width)的1维int32张量,用来表示图像的新大小.应该注意的是,**这块应该是代码设置的重点,这块将图片扩大“tf.shape(inputs)[1]2, tf.shape(inputs)[2]2]”,可看出将宽和高都翻倍。
align_corners:可选的bool,默认为False;如果为True,则输入和输出张量的4个角像素的中心对齐,并且保留角落像素处的值.
name:操作的名称(可选).
返回值:
该函数返回float32类型的Tensor.
mean_image_subtraction`
def mean_image_subtraction(images, means=[123.68, 116.78, 103.94]):
'''
image normalization
:param images:
:param means:
:return:
'''
num_channels = images.get_shape().as_list()[-1]
if len(means) != num_channels:
raise ValueError('len(means) must match the number of channels')
channels = tf.split(axis=3, num_or_size_splits=num_channels, value=images)
for i in range(num_channels):
channels[i] -= means[i]
return tf.concat(axis=3, values=channels)
这里是对样本的一些调整里面主要用到两个函数tf.split和tf.concat。以下对他进行详细介绍。
1)tf.split函数
tf.split(
value,
num_or_size_splits,
axis=0,
num=None,
name='split'
)
引用根据官方文档的说法这个函数的用途简单说就是把一个张量划分成几个子张量。
value:准备切分的张量
num_or_size_splits:准备切成几份
axis : 准备在第几个维度上进行切割
2) tf.concat
tf.concat([tensor1, tensor2, tensor3,...], axis)
axis=3 代表在第3个维度拼接
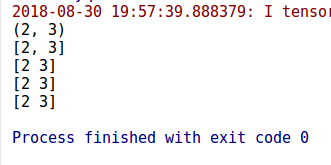
3)x.get_shape().as_list()
这个简单说明一下,x.get_shape(),只有tensor才可以使用这种方法,返回的是一个元组。
import tensorflow as tf
import numpy as np
a_array=np.array([[1,2,3],[4,5,6]])
b_list=[[1,2,3],[3,4,5]]
c_tensor=tf.constant([[1,2,3],[4,5,6]])
print(c_tensor.get_shape())
print(c_tensor.get_shape().as_list())
with tf.Session() as sess:
print(sess.run(tf.shape(a_array)))
print(sess.run(tf.shape(b_list)))
print(sess.run(tf.shape(c_tensor)))
model
下面就是对主要的model定义部分
def model(images, weight_decay=1e-5, is_training=True):
'''
define the model, we use slim's implemention of resnet
'''
images = mean_image_subtraction(images)
with slim.arg_scope(resnet_v1.resnet_arg_scope(weight_decay=weight_decay)):#用 slim.arg_scope()为目标函数设置默认参数.
logits, end_points = resnet_v1.resnet_v1_50(images, is_training=is_training, scope='resnet_v1_50')
# 先将图片经过resnet_v1网络得到resnet_v1的全部stage的输出,存在end_points里面
with tf.variable_scope('feature_fusion', values=[end_points.values]):
batch_norm_params = {
'decay': 0.997,
'epsilon': 1e-5,
'scale': True,
'is_training': is_training
}
with slim.arg_scope([slim.conv2d],
activation_fn=tf.nn.relu,
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params,
weights_regularizer=slim.l2_regularizer(weight_decay)):
# ** ** ** ** ** 下面这部分是FCN结构图中间绿色Fearture_merging的部分,上采样并合并特征图 ** ** ** ** ** **
f = [end_points['pool5'], end_points['pool4'],
end_points['pool3'], end_points['pool2']]
for i in range(4):
print('Shape of f_{} {}'.format(i, f[i].shape))
g = [None, None, None, None]
h = [None, None, None, None]
num_outputs = [None, 128, 64, 32]
for i in range(4):
if i == 0:
h[i] = f[i]
else:
c1_1 = slim.conv2d(tf.concat([g[i-1], f[i]], axis=-1), num_outputs[i], 1)
h[i] = slim.conv2d(c1_1, num_outputs[i], 3)
if i <= 2:
g[i] = unpool(h[i])
else:
g[i] = slim.conv2d(h[i], num_outputs[i], 3)
print('Shape of h_{} {}, g_{} {}'.format(i, h[i].shape, i, g[i].shape))
# **********下面这部分是Output_layer的部分*************
# 这里,我们使用稍微不同的方式进行回归,先使用sigmoid限制回归范围,这也与角度图有关
# 得分
F_score = slim.conv2d(g[3], 1, 1, activation_fn=tf.nn.sigmoid, normalizer_fn=None)
# 文本框坐标
geo_map = slim.conv2d(g[3], 4, 1, activation_fn=tf.nn.sigmoid, normalizer_fn=None) * FLAGS.text_scale
# 文本的旋转角度
angle_map = (slim.conv2d(g[3], 1, 1, activation_fn=tf.nn.sigmoid, normalizer_fn=None) - 0.5) * np.pi/2 # angle is between [-45, 45]
# 这里将坐标与角度信息合并输出
F_geometry = tf.concat([geo_map, angle_map], axis=-1)
首先将样本经过mean_image_subtraction函数处理。
然后将样本通过经过resnet_v1网络得到resnet_v1的全部stage的输出,存在end_points里面。这里用到slim.arg_scope函数这里稍加介绍
slim.arg_scope
slim.arg_scope()可以为目标函数设置默认参数.如下是举例。
import tensorflow as tf
slim =tf.contrib.slim
@slim.add_arg_scope
def fun1(a=0,b=0):
return (a+b)
with slim.arg_scope([fun1],a=10):
x=fun1(b=30)
print(x)
输出结果:40
然后部分是是FCN结构图中间绿色Fearture_merging的部分,上采样并合并特征图,此处用到一个函数slim.conv2d。这是一个卷积操作很简单就不详举例。
接下来部分是是Output_layer的部分也就是图片中最右面部分,最后返回 F_score, F_geometry。
损失
EAST的损失部分包含分类损失和回归损失,具体计算公式如下:

分类损失
classification_loss = dice_coefficient(y_true_cls, y_pred_cls, training_mask)
# scale classification loss to match the iou loss part
classification_loss *= 0.01
其中dice_coefficient定义为
def dice_coefficient(y_true_cls, y_pred_cls,
training_mask):
'''
dice loss
:param y_true_cls:
:param y_pred_cls:
:param training_mask:
:return:
'''
eps = 1e-5
intersection = tf.reduce_sum(y_true_cls * y_pred_cls * training_mask)
union = tf.reduce_sum(y_true_cls * training_mask) + tf.reduce_sum(y_pred_cls * training_mask) + eps
loss = 1. - (2 * intersection / union)
tf.summary.scalar('classification_dice_loss', loss)
return loss
值得注意的是在east论文中应该使用交叉熵函数作为分类损失函数,但是这里用的是dice损失,如果想使用交叉熵函数tf库中可以调用。
回归损失
# d1 -> top, d2->right, d3->bottom, d4->left
d1_gt, d2_gt, d3_gt, d4_gt, theta_gt = tf.split(value=y_true_geo, num_or_size_splits=5, axis=3)
d1_pred, d2_pred, d3_pred, d4_pred, theta_pred = tf.split(value=y_pred_geo, num_or_size_splits=5, axis=3)
area_gt = (d1_gt + d3_gt) * (d2_gt + d4_gt) # gt面积
area_pred = (d1_pred + d3_pred) * (d2_pred + d4_pred) # 预测面积
w_union = tf.minimum(d2_gt, d2_pred) + tf.minimum(d4_gt, d4_pred) # w交集
h_union = tf.minimum(d1_gt, d1_pred) + tf.minimum(d3_gt, d3_pred) # h交集
area_intersect = w_union * h_union # 交集面积
area_union = area_gt + area_pred - area_intersect # 并集面积
L_AABB = -tf.log((area_intersect + 1.0)/(area_union + 1.0)) # (交集面积+1)/(并集面积+1)取对数
# 角度误差函数
L_theta = 1 - tf.cos(theta_pred - theta_gt)
tf.summary.scalar('geometry_AABB', tf.reduce_mean(L_AABB * y_true_cls * training_mask))
tf.summary.scalar('geometry_theta', tf.reduce_mean(L_theta * y_true_cls * training_mask))
# 加权和得到geo los
L_g = L_AABB + 20 * L_theta
最终损失
# 考虑training_mask,较小的文本和难易识别的文本不参与损失计算
return tf.reduce_mean(L_g * y_true_cls * training_mask) + classification_loss
这就是我所介绍的EAST-master源码的model.py部分理解可能比较浅显,还望不喜勿喷,毕竟本人还在学习。后面附上完整程序。
完整代码
import tensorflow as tf
import numpy as np
from tensorflow.contrib import slim
tf.app.flags.DEFINE_integer('text_scale', 512, '')
from nets import resnet_v1
FLAGS = tf.app.flags.FLAGS
def unpool(inputs):
return tf.image.resize_bilinear(inputs, size=[tf.shape(inputs)[1]*2, tf.shape(inputs)[2]*2])
def mean_image_subtraction(images, means=[123.68, 116.78, 103.94]):
'''
image normalization
:param images:
:param means:
:return:
'''
num_channels = images.get_shape().as_list()[-1]
if len(means) != num_channels:
raise ValueError('len(means) must match the number of channels')
channels = tf.split(axis=3, num_or_size_splits=num_channels, value=images)
for i in range(num_channels):
channels[i] -= means[i]
return tf.concat(axis=3, values=channels)
def model(images, weight_decay=1e-5, is_training=True):
'''
define the model, we use slim's implemention of resnet
'''
images = mean_image_subtraction(images)
with slim.arg_scope(resnet_v1.resnet_arg_scope(weight_decay=weight_decay)):#用 slim.arg_scope()为目标函数设置默认参数.
logits, end_points = resnet_v1.resnet_v1_50(images, is_training=is_training, scope='resnet_v1_50')
# 先将图片经过resnet_v1网络得到resnet_v1的全部stage的输出,存在end_points里面
with tf.variable_scope('feature_fusion', values=[end_points.values]):
batch_norm_params = {
'decay': 0.997,
'epsilon': 1e-5,
'scale': True,
'is_training': is_training
}
with slim.arg_scope([slim.conv2d],
activation_fn=tf.nn.relu,
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params,
weights_regularizer=slim.l2_regularizer(weight_decay)):
# ** ** ** ** ** 下面这部分是FCN结构图中间绿色Fearture_merging的部分,上采样并合并特征图 ** ** ** ** ** **
f = [end_points['pool5'], end_points['pool4'],
end_points['pool3'], end_points['pool2']]
for i in range(4):
print('Shape of f_{} {}'.format(i, f[i].shape))
g = [None, None, None, None]
h = [None, None, None, None]
num_outputs = [None, 128, 64, 32]
for i in range(4):
if i == 0:
h[i] = f[i]
else:
c1_1 = slim.conv2d(tf.concat([g[i-1], f[i]], axis=-1), num_outputs[i], 1)
h[i] = slim.conv2d(c1_1, num_outputs[i], 3)
if i <= 2:
g[i] = unpool(h[i])
else:
g[i] = slim.conv2d(h[i], num_outputs[i], 3)
print('Shape of h_{} {}, g_{} {}'.format(i, h[i].shape, i, g[i].shape))
# here we use a slightly different way for regression part,
# we first use a sigmoid to limit the regression range, and also
# this is do with the angle map
F_score = slim.conv2d(g[3], 1, 1, activation_fn=tf.nn.sigmoid, normalizer_fn=None)
# 4 channel of axis aligned bbox and 1 channel rotation angle
geo_map = slim.conv2d(g[3], 4, 1, activation_fn=tf.nn.sigmoid, normalizer_fn=None) * FLAGS.text_scale
angle_map = (slim.conv2d(g[3], 1, 1, activation_fn=tf.nn.sigmoid, normalizer_fn=None) - 0.5) * np.pi/2 # angle is between [-45, 45]
F_geometry = tf.concat([geo_map, angle_map], axis=-1)
return F_score, F_geometry#分类图(是否有文本框),(坐标+角度)
def dice_coefficient(y_true_cls, y_pred_cls,
training_mask):
'''
dice loss
:param y_true_cls:
:param y_pred_cls:
:param training_mask:
:return:
'''
eps = 1e-5
intersection = tf.reduce_sum(y_true_cls * y_pred_cls * training_mask)
union = tf.reduce_sum(y_true_cls * training_mask) + tf.reduce_sum(y_pred_cls * training_mask) + eps
loss = 1. - (2 * intersection / union)
tf.summary.scalar('classification_dice_loss', loss)
return loss
def loss(y_true_cls, y_pred_cls,
y_true_geo, y_pred_geo,
training_mask):
'''
define the loss used for training, contraning two part,
the first part we use dice loss instead of weighted logloss,
the second part is the iou loss defined in the paper
:param y_true_cls: ground truth of text
:param y_pred_cls: prediction os text
:param y_true_geo: ground truth of geometry
:param y_pred_geo: prediction of geometry
:param training_mask: mask used in training, to ignore some text annotated by ###
:return:
'''
#分类损失
classification_loss = dice_coefficient(y_true_cls, y_pred_cls, training_mask)
# scale classification loss to match the iou loss part
classification_loss *= 0.01
#回归损失
# d1 -> top, d2->right, d3->bottom, d4->left
d1_gt, d2_gt, d3_gt, d4_gt, theta_gt = tf.split(value=y_true_geo, num_or_size_splits=5, axis=3)
d1_pred, d2_pred, d3_pred, d4_pred, theta_pred = tf.split(value=y_pred_geo, num_or_size_splits=5, axis=3)
area_gt = (d1_gt + d3_gt) * (d2_gt + d4_gt)
area_pred = (d1_pred + d3_pred) * (d2_pred + d4_pred)
w_union = tf.minimum(d2_gt, d2_pred) + tf.minimum(d4_gt, d4_pred)
h_union = tf.minimum(d1_gt, d1_pred) + tf.minimum(d3_gt, d3_pred)
area_intersect = w_union * h_union
area_union = area_gt + area_pred - area_intersect
L_AABB = -tf.log((area_intersect + 1.0)/(area_union + 1.0))
L_theta = 1 - tf.cos(theta_pred - theta_gt)
tf.summary.scalar('geometry_AABB', tf.reduce_mean(L_AABB * y_true_cls * training_mask))
tf.summary.scalar('geometry_theta', tf.reduce_mean(L_theta * y_true_cls * training_mask))
L_g = L_AABB + 20 * L_theta
return tf.reduce_mean(L_g * y_true_cls * training_mask) + classification_loss
写在最后
在写这篇文章时好多函数是查询了其他博主的博客但是由于查询过多,所以未能一一记录来源,在这里向各位前辈致上诚挚感谢。
