前言
在上一篇Redis初探中,我们简单介绍了Redis的特性,单线程架构以及字符串类型,因此本文将继续介绍Redis的其他四种数据结构。
1.1哈希
hash包含若干个key-value,其中key不重复,Redis键值对和哈希类型二者的关系如下图所示
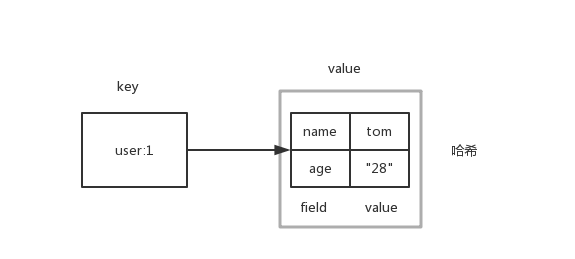
hash内部的key和value不能在嵌套map了,它只能是String型所能表达的内容。
- 常用命令
哈希类型的常用命令
| 命令 | 描述 |
|---|---|
| hset key field value | 将哈希表 key 中的字段 field 的值设为 value |
| hget key field | 获取存储在哈希表中指定字段的值。 |
| hdel key field [field...] | 删除一个或多个哈希表字段,返回结果为成功删除field的个数。 |
| hlen key | 获取哈希表中字段的数量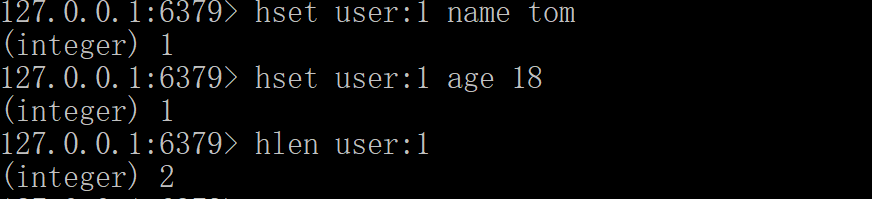 |
| hmget key field hmset key field value |
获取所有给定字段的值,以及同时将多个 field-value (域-值)对设置到哈希表 key 中。 |
| hexists key field | 查看哈希表 key 中,指定的字段是否存在,成功则返回1,否则返回0。 |
| hkeys key | 获取所有哈希表中的字段。 |
| hvals key | 获取哈希表中所有值。 |
| hgetall key | 获取在哈希表中指定 key 的所有字段和值。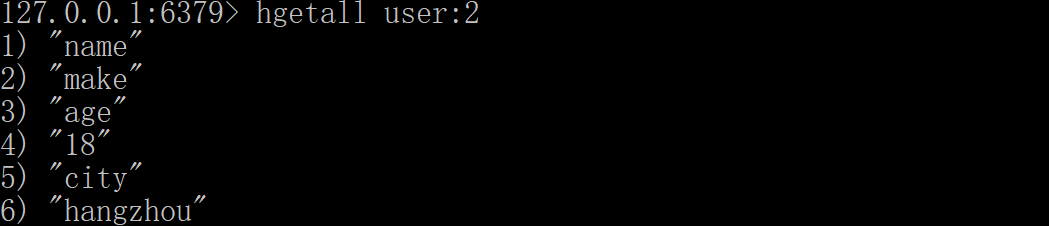 |
- 内部数据结构
哈希类型的内部编码有两种:ziplist和hashtable。其中当field个数比较少且没有大的value时,内部编码为ziplist,当有value大于64字节,内部编码会由ziplist变为hashtable,当field个数超过512个,内部编码也会由ziplist变为hashtable。
ziplist使用更加紧凑的结构实现多个元素的连续存储,在节省内存方面优于hashtable。ziplist的分布结构如下图所示
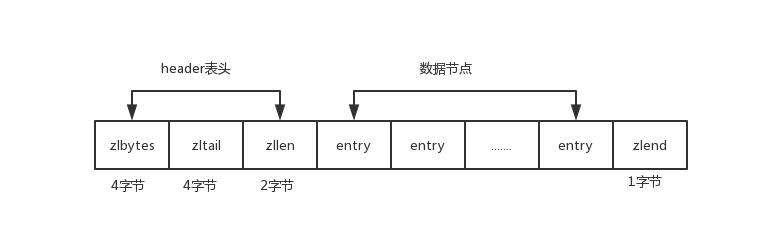

其中zlbytes表示本ziplist的总长度;zltail的值是最末元素距离ziplist头的偏移量;zllen是元素个数;zlend恒为0xFF,标记压缩列表的末端。另外数据节点entry内部结构如下图所示
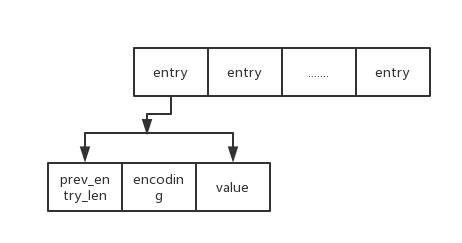
其中,prev_entry_len:记录前驱节点的长度;encoding:记录当前节点的value成员的数据类型以及长度;value:根据encoding来保存字节数组或整数。当前驱节点的长度小于254字节,那么prev_entry_len使用1字节表示。当前驱节点的长度大于等于255字节,那么prev_entry_len使用5个字节表示。并且用5个字节中的最高8位(最高1个字节)用 0xFE 标示prev_entry_len占用了5个字节,后四个字节才是真正保存前驱节点的长度值。encoding对当前节点保存的是字节数组还是整数分别编码,字节数组的长度可以是:1字节,2字节,5字节。编码范围的前两位分别是00,01,10,因此除去最高2位用来区别编码长度,剩下的位则用来表示value成员的长度。整数的编码长度只有1字节。最高2位是11开头的编码格式。value成员负责根据encoding来保存字节数组或整数。
hashtable在Redis中分为三层,分别是dictEntry,dictht,dict。其中dictEntry管理一个key-value对,同时保留同一个桶中相邻元素的指针,一次维护哈希桶的内部链。dictht维护哈希表的所有桶链。dict当dictht需要扩容/缩容时,用于管理dictht的迁移。
哈希表的核心结构是dictht,它的table字段维护者hash桶,它是一个数组,每个元素指向桶的第一个元素(dictEntry),结构如下
typedef struct dictht{
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
}如图所示,当有一个新的key访问时,首先通过MurmurHash算法求出key的hash值,在对桶的个数(即dictht的size字段值)取模,得到key对应的桶,在进入桶中,遍历全部entry,判断是否已有相同的key吗如果没有,则将新key对应的键值对插入到桶头,并且更新dictht的used数量,后者表示当前hash表中已经存了多少元素。

由于桶的个数永远是2的n次方,可以用size-1做位运算快速得到哈希值的摸,所以dictht中引入了sizemask,其值恒为size-1。
Redis引入了负载银子判断是否需要增加桶数,负载因子=哈希表中已有元素和哈希桶数的比值,当小于1时一定不扩容,大于5时一定扩容,介于1到5之间时,Redis如果没有进行bgsave/bdrewrite操作时扩容,Redis同样根据负载因子决定是否缩容,目前的缩容阈值为0.1。
扩容或者缩容都是通过新建哈希表的方式实现,扩容时,并存两个哈希表,一个是原表,一个是目标表,通过将原表的桶逐步迁移到目标表,以数据迁移的方式实现扩容,迁移完成后,目标表覆盖原表。
- 使用场景
下图为关系型数据表记录的两条用户信息,用户的属性作为表的列,每条用户信息作为行。
| id | name | age | city |
| 1 | tom | 18 | hangzhou |
| 2 | mike | 18 | hangzhou |
如果将其用哈希类型存储,相比于使用字符串序列化缓存用户信息,哈希类型变得更加直观,并且再更新操作上会更加便捷。

1.2列表
列表类型是用来存储多个有序的字符串。
- 常用命令
列表常用命令
| 命令 | 描述 |
|---|---|
| rpush key value [value....] | 在列表中从右边添加一个或多个值。 |
| lrange key start stop | 获取列表指定范围内的元素。lrange key 0 -1可以获取列表所有元素。 |
| lpush key value [value....] | 在列表中从左边添加一个或多个值。 |
| llen key | 获取列表长度。 |
| lpop key | 从列表左侧弹出元素 |
| rpop key | 从列表右侧弹出元素 |
| lset key index newValue | 修改指定索引下标的元素 |
- 内存数据结构
list类型的value对象内部有linkedlist和ziplist两种编码。其中ziplist编码在介绍hash类型时已经详细介绍,这里就不再多说。我们着重说一下linkedlist编码。
linkedlist内部实现是双向链表,双向链表的每个数据节点都有两个指针,分别指向后继与前驱节点,因此从双向链表中的任意一个节点开始都可以很方便地访问其前驱与后继节点。结构如下所示
typedef struct listNode {
struct listNode *prev;//前驱指针
struct listNode *next;//后继指针
void *value; //节点的值
} listNode;
typedef struct listIter {//链表迭代器
listNode *next;
int direction;//遍历方向
} listIter;
typedef struct list {//链表
listNode *head;//链表头
listNode *tail;//链表尾
void *(*dup)(void *ptr); //复制函数指针
void (*free)(void *ptr); //释放内存函数指针
int (*match)(void *ptr, void *key); //比较函数指针
unsigned long len; //链表长度
} list;
listNode拥有prev前驱指针和next后继指针,因此通过迭代器可以很方便的对链表从从头至尾或从尾至头遍历;list拥有header头指针和tail为指针,对于在链表的头部或尾部进行插入节点的时间复杂度全部为O(1),高效地实现了Redis中一些指令的操作;list自带保存链表长度的字段len,使得计算链表长度的时间复杂度为O(1)。
- 使用场景
可以作为文章列表,每个用户有属于自己的文章列表,现需要分页展示文章列表。此时可以考虑使用列表,因为列表不仅有序,而且支持按照索引范围获取元素。

将每篇文章使用哈希存储,向用户文章列表添加文章。最后分页获取用户文章的列表
acticles =lrange user:1:acticles 0 9
for acticle in acticles
hgetall acticle1.3总结
本篇文章分析了Redis支持的哈希和列表两种数据结构,下一篇文章在继续详细介绍其他几种数据结构。