一、主题式网络爬虫设计方案
1.主题式网络爬虫名称
爬取赶集网招聘信息
2.主题式网络爬虫爬取的内容与数据特征分析
本爬虫主要是爬取职位名称、公司名称、工作地点、工作经验、薪资待遇、招聘人数和职位发布时间。这些数据呈现出丰富的招聘信息。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
本方案是利用requests库对目标页面进行爬取,然后利用BeautifulSoup库对相关信息进行数据清洗。主要难点是数据清洗,由于想要的数据在同级标签上,所以要多几个数据分析函数。
二、主题页面的结构特征分析
1.主题页面的结构与特征分析
以泉州的销售岗位为例,它的url链接为
http://quanzhou.ganji.com/zhaopin/
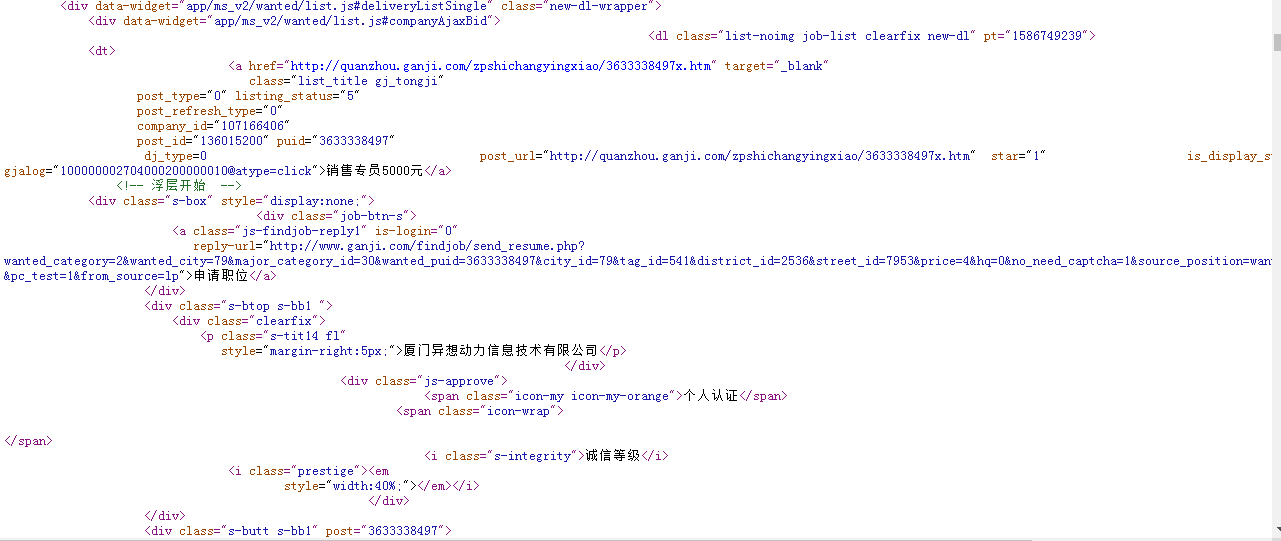
2.Htmls页面解析
页面部分源代码如下图所示


3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
find_all
三、网络爬虫程序设计
数据爬取与采集
import requests from bs4 import BeautifulSoup url='http://quanzhou.ganji.com/zhaopin/' #用requests抓取网页信息 def getHTMLText(url,timeout=30): try: #用requests抓取网页信息 r=requests.get(url,timeout=30) #异常捕捉 r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return'产生异常' #html.parser表示用BeautifulSoup库解析网页 html=getHTMLText(url) soup=BeautifulSoup(html,'html.parser') #按标准缩进格式的结构输出 print(soup.prettify())
对数据进行清洗和处理
#爬取职位名称 def getJobsName(ulist,html): #创建BeautifulSoup对象 soup = BeautifulSoup(html,"html.parser") #遍历所有属性为t1的p标签 for p in soup.find_all("p",attrs = "t1"): #将p标签中的a标签中的内容存放在ulist列表中 ulist.append(str(p.a.string).strip()) #返回列表 return ulist
#爬取公司名称 def getCompanyName(ulist,html): soup = BeautifulSoup(html,"html.parser") #遍历所有属性为t2的span标签 for span in soup.find_all("span",attrs = "t2"): #将span标签中的内容存放在ulist列表中 ulist.append(str(span.string).strip()) #删除列表的第0个元素 ulist.pop(0) return ulist
#爬取工作地点 def getWorkingPlace(ulist,html): soup = BeautifulSoup(html,"html.parser") #遍历所有属性为t3的span标签 for span in soup.find_all("span",attrs = "t3"): #将span标签中的内容存放在ulist列表中 ulist.append(str(span.string).strip()) #删除列表的第0个元素 ulist.pop(0) return ulist
#爬取工作经验 def getWorkingexperience(ulist,html): soup = BeautifulSoup(html,"html.parser") #遍历所有属性为t4的span标签 for span in soup.find_all("span",attrs = "t4"): #将span标签中的内容存放在ulist列表中 ulist.append(str(span.string).strip()) #删除列表的第0个元素 ulist.pop(0) return ulist
#爬取薪资待遇 def getSalary(ulist,html): soup = BeautifulSoup(html,"html.parser") #遍历所有属性为t5的span标签 for span in soup.find_all("span",attrs = "t5"): #将span标签中的内容存放在ulist列表中 ulist.append(str(span.string).strip()) ulist.pop(0) return ulist
#爬取招聘人数 def getHiring(ulist,html): soup = BeautifulSoup(html,"html.parser") #遍历所有属性为t6的span标签 for span in soup.find_all("span",attrs = "t6"): #将span标签中的内容存放在ulist列表中 ulist.append(str(span.string).strip()) ulist.pop(0) return ulist
#爬取职位发布时间 def getReleaseTime(ulist,html): soup = BeautifulSoup(html,"html.parser") #遍历所有属性为t7的span标签 for span in soup.find_all("span",attrs = "t7"): #将span标签中的内容存放在ulist列表中 ulist.append(str(span.string).strip()) ulist.pop(0) return ulist
数据持久化
#使用pandas进行数据存储、读取 def pdSaveRead(JobName,comnayName,WorkingPlace,Workingexperience,Salary,Hiring,ReleaseTime): try: #创建文件夹 os.mkdir("D:\招聘信息") except: #如果文件夹存在则什么也不做 "" #创建numpy数组 r = np.array([JobName,comnayName,WorkingPlace,Workingexperience,Salary,Hiring,ReleaseTime]) #columns(列)名 columns_title = ['职位名称','公司名称','工作经验','工作地点','薪资待遇','招聘人数','职位发布时间'] #创建DataFrame数据帧 df = pd.DataFrame(r.T,columns = columns_title) #将数据存在Excel表中 df.to_excel('D:\招聘信息\职位信息.xls',columns = columns_title) #读取表中职位信息 dfr = pd.read_excel('D:\招聘信息\职位信息.xls') print(dfr.head())
完整程序代码
import requests from bs4 import BeautifulSoup import pandas as pd import numpy as np import os url='http://quanzhou.ganji.com/zhaopin/' #用requests抓取网页信息 def getHTMLText(url,timeout=30): try: #用requests抓取网页信息 r=requests.get(url,timeout=30) #异常捕捉 r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return'产生异常' #html.parser表示用BeautifulSoup库解析网页 html=getHTMLText(url) soup=BeautifulSoup(html,'html.parser') #按标准缩进格式的结构输出 print(soup.prettify()) #爬取职位名称 def getJobsName(ulist,html): #创建BeautifulSoup对象 soup = BeautifulSoup(html,"html.parser") #遍历所有属性为t1的p标签 for p in soup.find_all("p",attrs = "t1"): #将p标签中的a标签中的内容存放在ulist列表中 ulist.append(str(p.a.string).strip()) #返回列表 return ulist #爬取公司名称 def getCompanyName(ulist,html): soup = BeautifulSoup(html,"html.parser") #遍历所有属性为t2的span标签 for span in soup.find_all("span",attrs = "t2"): #将span标签中的内容存放在ulist列表中 ulist.append(str(span.string).strip()) #删除列表的第0个元素 ulist.pop(0) return ulist #爬取工作地点 def getWorkingPlace(ulist,html): soup = BeautifulSoup(html,"html.parser") #遍历所有属性为t3的span标签 for span in soup.find_all("span",attrs = "t3"): #将span标签中的内容存放在ulist列表中 ulist.append(str(span.string).strip()) #删除列表的第0个元素 ulist.pop(0) return ulist #爬取工作经验 def getWorkingexperience(ulist,html): soup = BeautifulSoup(html,"html.parser") #遍历所有属性为t4的span标签 for span in soup.find_all("span",attrs = "t4"): #将span标签中的内容存放在ulist列表中 ulist.append(str(span.string).strip()) #删除列表的第0个元素 ulist.pop(0) return ulist #爬取薪资待遇 def getSalary(ulist,html): soup = BeautifulSoup(html,"html.parser") #遍历所有属性为t5的span标签 for span in soup.find_all("span",attrs = "t5"): #将span标签中的内容存放在ulist列表中 ulist.append(str(span.string).strip()) ulist.pop(0) return ulist #爬取招聘人数 def getHiring(ulist,html): soup = BeautifulSoup(html,"html.parser") #遍历所有属性为t6的span标签 for span in soup.find_all("span",attrs = "t6"): #将span标签中的内容存放在ulist列表中 ulist.append(str(span.string).strip()) ulist.pop(0) return ulist #爬取职位发布时间 def getReleaseTime(ulist,html): soup = BeautifulSoup(html,"html.parser") #遍历所有属性为t7的span标签 for span in soup.find_all("span",attrs = "t7"): #将span标签中的内容存放在ulist列表中 ulist.append(str(span.string).strip()) ulist.pop(0) return ulist #使用pandas进行数据存储、读取 def pdSaveRead(JobName,comnayName,WorkingPlace,Workingexperience,Salary,Hiring,ReleaseTime): try: #创建文件夹 os.mkdir("D:\招聘信息") except: #如果文件夹存在则什么也不做 "" #创建numpy数组 r =np.array([JobName,comnayName,WorkingPlace,Workingexperience,Salary,Hiring,ReleaseTime]) #columns(列)名 columns_title = ['职位名称','公司名称','工作经验','工作地点','薪资待遇','招聘人数','职位发布时间'] #创建DataFrame数据帧 df = pd.DataFrame(r.T,columns = columns_title) #将数据存在Excel表中 df.to_excel('D:\招聘信息\职位信息.xls',columns = columns_title) #读取表中职位信息 dfr = pd.read_excel('D:\招聘信息\职位信息.xls') print(dfr.head()) #主函数 def main(): #赶集网招聘信息 url = 'http://quanzhou.ganji.com/' #用来存放职位名称 jobName = [] #用来存放公司名称 comnayName = [] #用来存放工作地点 workingPlace = [] #用来存放工作经验 worjingexperience=[] #用来存放薪资待遇 salary = [] #用来存放招聘人数 hiring=[] #用来存放职位发布时间 releaseTime = [] #打印的页数加1 num = 11 #把第一页到第十页的招聘信息存放在相关的列表中 for page in range(1,num): url='http://quanzhou.ganji.com/zhaopin/' #获取目标链接的html页面 html = getHTMLText(url) #获取职位名称并存放在相关的列表中 getJobsName(jobName,html) #获取公司名称并存放在相关的列表中 getCompanyName(comnayName,html) #获取工作地点并存放在相关的列表中 getWorkingPlace(workingPlace,html) #获取工作经验并存放在相关的列表中 getWorkingexperience(workingexperience,html) #获取薪资待遇并存放在相关的列表中 getSalary(salary,html) #获取招聘人数并存放在相关的列表中 getHiring(hiring,html) #获取职位发布时间并存放在相关的列表中 getReleaseTime(releaseTime,html) #数据存储 pdSaveRead(jobName,comnayName,workingPlace,workingexperience,salary,hiring,releaseTime) #程序入口 if __name__ == "__main__": main()
四、结论
1.经过对主题数据的分析与可视化,可以得到哪些结论?
经过对主题数据的分析与可视化,使本来的数据呈现在图表上,更直观的展示出来。
2.对本次程序设计任务完成的情况做一个简单的小结。
本次程序设计任务完成情况一般,程序代码基本上完成,可结果没有输出,不知道是何原因。