用urllib,requests写过一些小爬虫,最近学习了scrapy框架,因此有了下文。
概要知识:理解scrapy框架的整体架构,如图
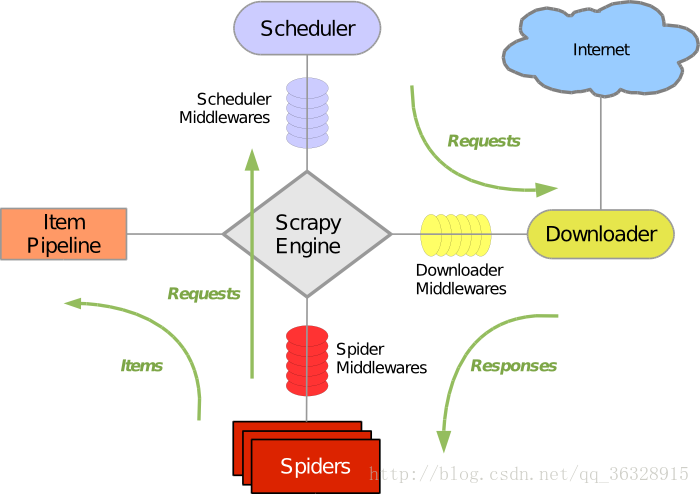
箭头指明了工作流程,Scheduler接受来自Scrapy Engine的请求将其入队列,然后将请求转发给Downloader,Downloader下载内容并将其返回给Spiders,Spiders会根据需求过滤我们需要的数据然后将其转发给Item Pipeline或者继续转发给Scrapy Engine再次处理,Item Pipeline有多种工作方式,如存储为json格式的文件,存到数据库等...
正文:
目标
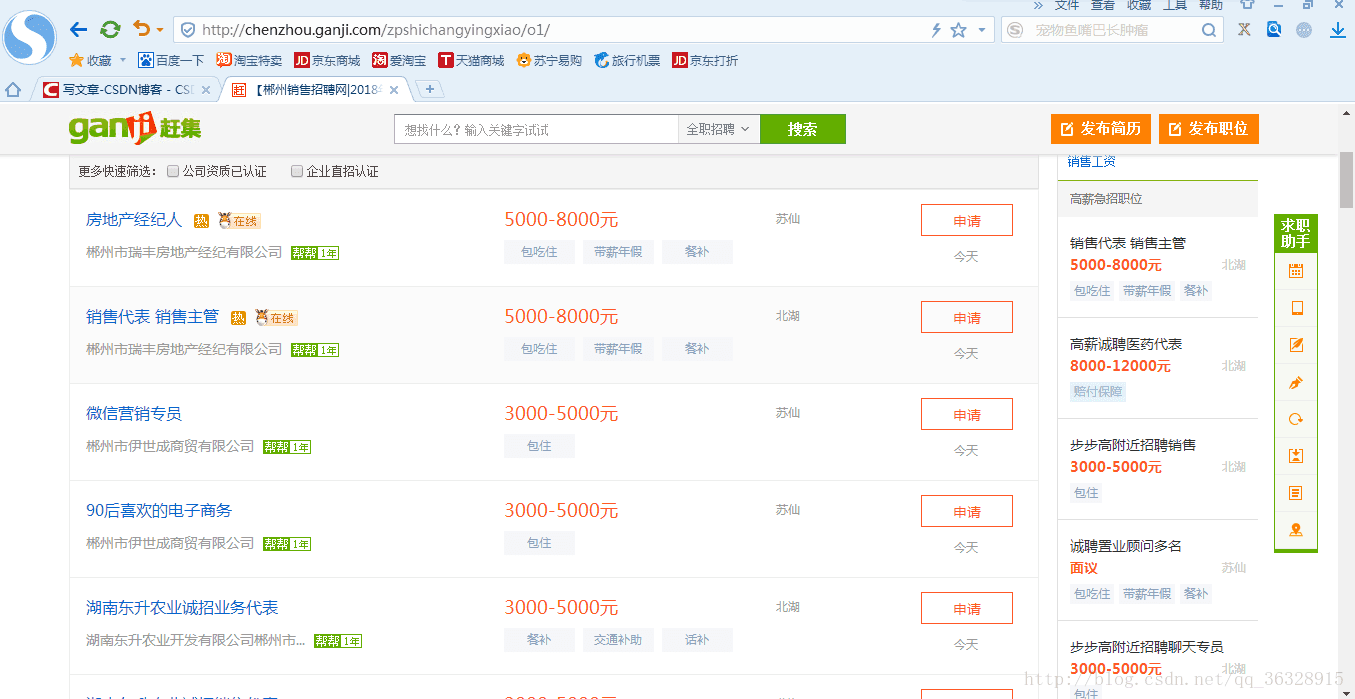
我希望爬取的内容有职位名,薪水,地点,日期,先观察一下页数
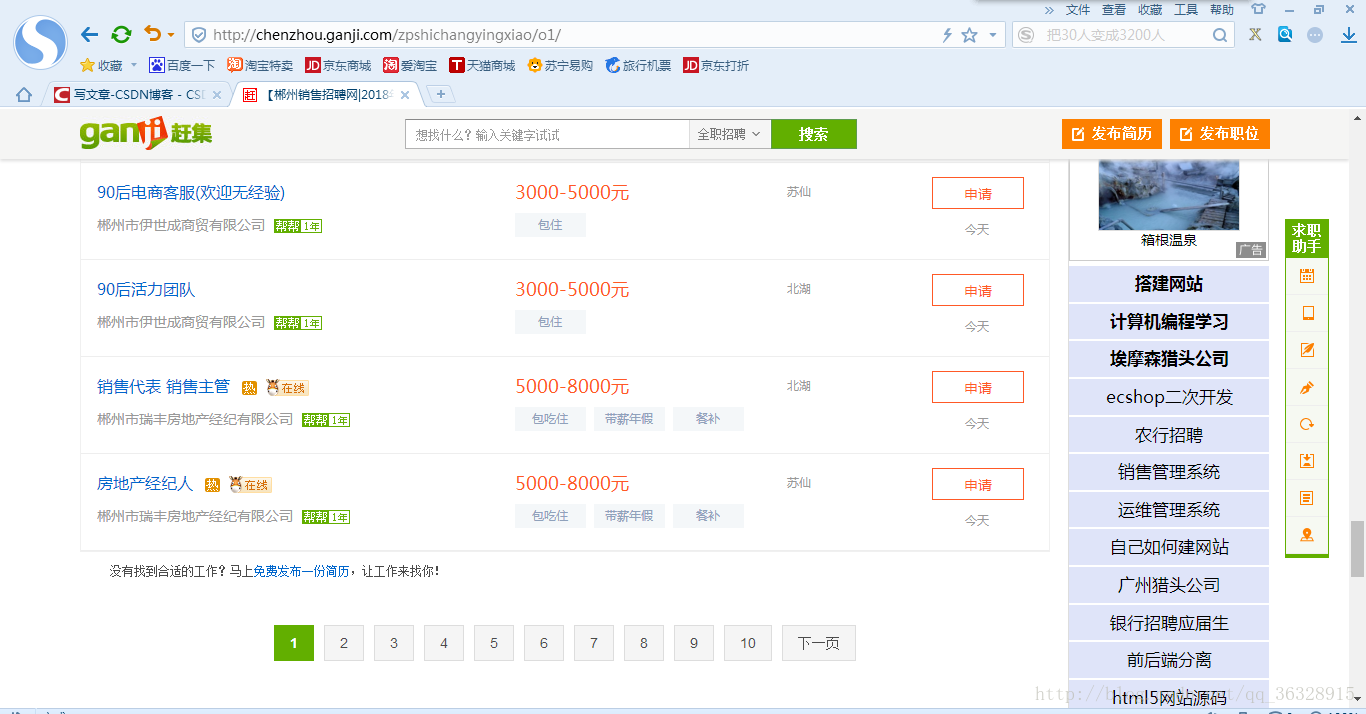
这里不得不说一下这个分页功能,没有首尾页 ,话不多说,我们使用折半查找法,根据url我们可以很明显的看出o1后面这个唯一的数字肯定是代表页数的,接下来我构造数字300然后折半猜测150...好了答案就是o90(一般最多也就几百页)。
,话不多说,我们使用折半查找法,根据url我们可以很明显的看出o1后面这个唯一的数字肯定是代表页数的,接下来我构造数字300然后折半猜测150...好了答案就是o90(一般最多也就几百页)。
首先我们创建一个scrapy项目

在sublime打开项目,首先我们编写items,进而确定我们要保存的数据

接着我们在pipelines中实现对数据操作的逻辑,此出我只将其存为json文件

这里别忘了在settings文件中去掉67-69行的注释才能使我们实现的pipelines生效
接下来我实现spiders文件夹下主文件spider_ganji的编写,这里我们先分析一下要爬取的数据
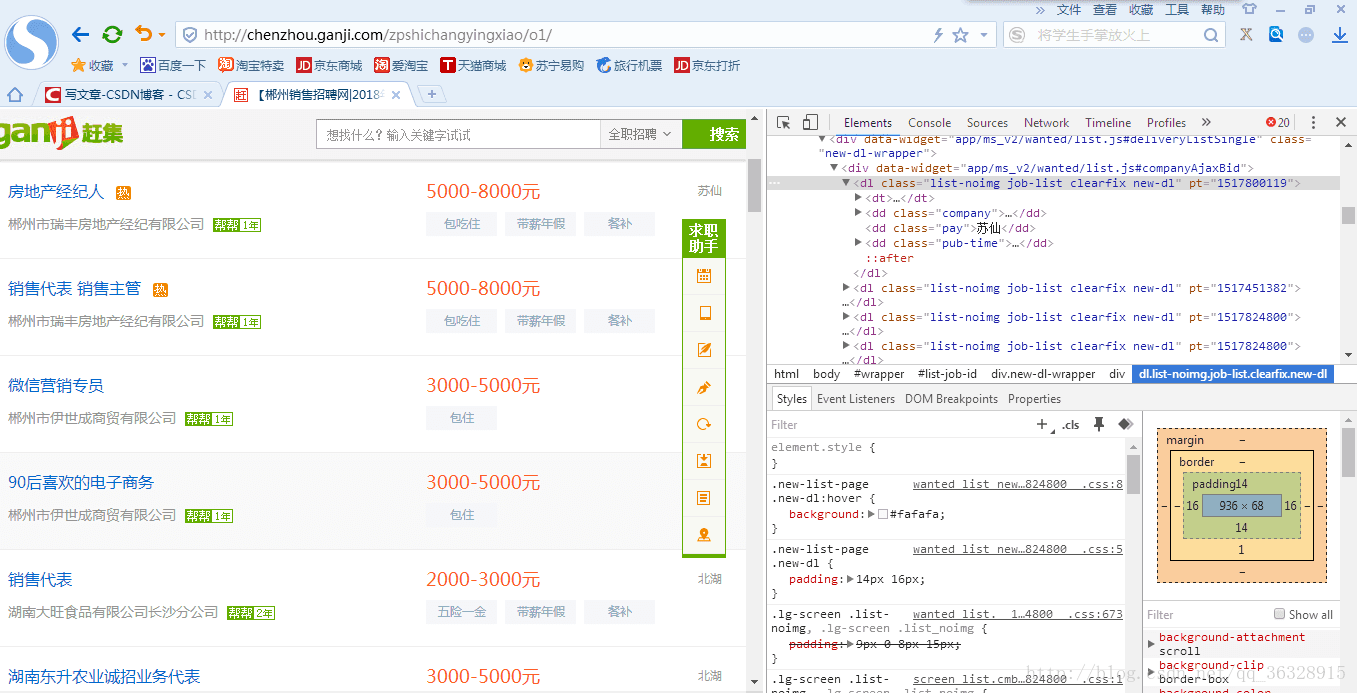
可以看出每一项待爬取的数据都是一个dl,里面分别是我们需要的数据,分析完毕,可以通过xpath来选中我们需要的数据
实现代码如下:
# -*- coding: utf-8 -*-
import scrapy
from www_ganji.items import WwwGanjiItem
import datetime
class SpiderGanjiSpider(scrapy.Spider):
name = 'spider_ganji'
#我们允许爬取的域范围
allowed_domains = ['chenzhou.ganji.com']
#构造一个utl等下用来进行动态拼接
baseUrl='http://chenzhou.ganji.com/zpshichangyingxiao/o'
#初始化页数
offset=1
#拼接url
start_urls = [baseUrl+str(offset)]
def parse(self, response):
#通过xpath获得所有dl
node_list=response.xpath("//dl[@class='list-noimg job-list clearfix new-dl']")
#遍历每一个dl,一次循环处理一个dl中的数据
for list in node_list:
#生成一个WwwGanjiItem对象用来保存数据
item=WwwGanjiItem()
'''
通过xpath获得职位名称 ./表示接着上一个xpath表达式 text()表示取文本内容
extract()返回一个list存有所有匹配extract()[0]表示取所有数据的第一个
'''
item['name']=list.xpath("./dt/a[@class='list_title gj_tongji']/text()").extract()[0].encode("utf-8")
#通过xpath获得薪水,此处注意薪水可以为空,所以进行一个逻辑判断,不然会报错
if len(list.xpath("./dd[@class='company']/div[@class='new-dl-salary']")):
item['money']=list.xpath("./dd[@class='company']/div[@class='new-dl-salary']/text()").extract()[0].encode("utf-8").replace(" ","").strip("\n")
else:
item['money']=""
#通过xpath获得工作地点
item['work_place']=list.xpath("./dd[@class='pay']/text()").extract()[0].encode("utf-8")
#通过xpath获得发布时间
if len(list.xpath("./dd[@class='pub-time']/span")):
item['time']=list.xpath("./dd[@class='pub-time']/span/text()").extract()[0].encode("utf-8")
else:
item['time']=""
'''
这里我们用yield返回item 。yield x:简单来说就是返回x接着执行下面的语句
因为执行一次循环我们只能获得一个dl中的数据
'''
yield item
'''
这里是写死页数的做法,当页数<某个值时我们就构造下一页并发送请求
if offset < 80:
self.offset +=1
url=baseUrl+self.offset
yield scrapy.request(url,callback=self.parse)
'''
'''
这里是没有写死页数的方法,逻辑上来说就是我们只要知道是否有下一页就能知道
是否翻到末尾了
最后我们yield 下一个请求实现翻页效果
'''
if len(response.xpath("//a[@class='next']")):
url=response.xpath("//a[@class='next']/@href").extract()[0]
yield scrapy.Request("http://chenzhou.ganji.com/"+url,callback=self.parse)到此我们要实现的代码都写完了,进入项目目录执行scrapy crawl spider_ganji执行爬虫效果如下

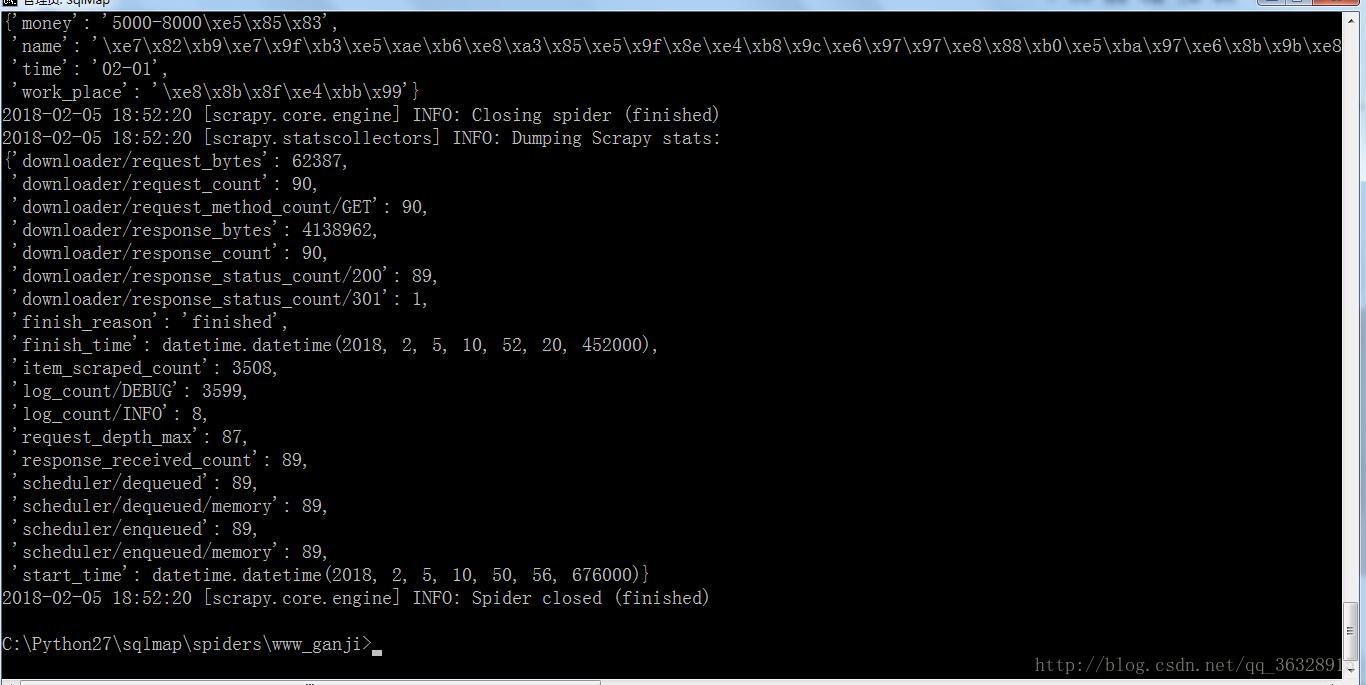
执行完毕,接下来我们看一下保存数据的文本。
一共爬取了约3500条数据。