算法的时间复杂度和空间复杂度计算【转载】
1.算法的时间复杂度定义:
在进行算法分析时,语句总的执行次数是关于问题规模
的函数,可以通过分析
随
的变化情况来确定
的数量级。
算法的时间复杂度,也就是算法的时间量度,记作:,它表示随问题规模n的增大,算法执行时间的增长率和
的增长率相同,其中
是问题规模
的某个函数,用
来体现算法时间复杂度的记法,我们称之为大
记法。
2.推导大阶方法:
(1)用常数1取代运行时间中的所有加法常数;
(2)在修改后的运行次数函数中,只保留最高阶项;
(3)如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大O阶。
3.推导示例:
(1)常数阶:
以下代码利用高斯定理计算1,2,……n个数的和,是顺序结构的时间复杂度。
int sum = 0, n = 100; /*执行一次*/
sum = (1 + n) * n / 2; /*执行一次*/
printf("%d",sum); /*执行一次*/ 这个算法的运行次数函数是,根据推导大
阶的方法,第一步是把常数项3改为1,在保留最高阶项时发现它没有最高阶项,所以这个算法的时间复杂度为
(1)。
另外,如果这个算法当中的语句 “sum = (1+n)*n/2;” 有10 句,则示例给出的代码就是3次和12次的差异,这种与问题的大小(n)无关、执行时间恒定的算法,我们称之为具有(1)的时间复杂度,又叫常数阶。
对于分支结构而言,无论是真或假执行的次数都是恒定的,不会随着n 的变大而发生变化,所以单纯的分支结构(不包含在循环结构中)其时间复杂度也是(1)。
(2)线性阶:
线性阶的循环结构会复杂很多,要确定某个算法的阶次常常需要确定某个特定语句或某个语句集运行的次数。因此要分析算法的复杂度关键是要分析循环结构的运行情况。
下面这段代码的循环时间复杂度为O(n), 因为循环体中的代码须要执行n次。
int i;
for(i = 0; i < n; i++){
/*时间复杂度为O(1)的程序步骤序列*/
}(3)对数阶:
int count = 1;
while (count < n){
count = count * 2;
/*时间复杂度为O(1)的程序步骤序列*/
}while循环每执行一次count乘以2,count就距离n更近一些, 当若干个2相乘后大于n,则会退出while循环。
由2^x=n 得到x=logn, 所以这个循环的时间复杂度为O(logn)。
(4)平方阶:
下面代码是一个循环嵌套,它的内循环时间复杂度如上文所示为O(n)。
int i, j;
for(i = 0; i < n; i++){
for(j = 0; j < n; j++){
/*时间复杂度为O(1)的程序步骤序列*/
}
}而对于外层的循环,不过是内部这个时间复杂度为O(n)的语句,再循环n次,所以这段代码的时间复杂度为O(n^2)。如果外循环的循环次数改为了m,时间复杂度就变为O(mXn)。可以总结得出,循环的时间复杂度等于循环体的复杂度乘以该循环运行的次数。
下面代码中的循环嵌套,由于当i=0时,内循环执行了n次,当i = 1时,执行了n-1次,……当i=n-1时,执行了1次。所以总的执行次数为:
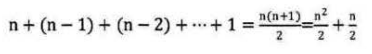
用推导大阶的方法,第一条,没有加法常数不予考虑;第二条,只保留最高阶项,因此保留时(n^2)/2; 第三条,去除这个项相乘的常数,也就是去除1/2,最终这段代码的时间复杂度为
(n2)。
int i, j;
for(i = 0; i < n; i++){
for(j = i; j < n; j++){ /*注意j = i而不是0*/
/*时间复杂度为O(1)的程序步骤序列*/
}
} 从上例可知理解大推导的难点是对数列的一些相关运算。
(5)立方阶:
下面代码是一个三重循环嵌套,循环了(1^2+2^2+3^2+……+n^2) = n(n+1)(2n+1)/6次,按照上述大阶推导方法,时间复杂度为O(n^3)。
int i, j;
for(i = 1; i < n; i++)
for(j = 1; j < n; j++)
for(j = 1; j < n; j++){
/*时间复杂度为O(1)的程序步骤序列*/
}4.推导示例:
常见的时问复杂度如下表所示:
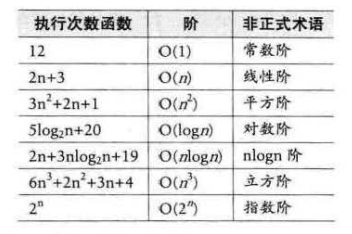
常用的时间复杂度所耗费的时间从小到大依次是:
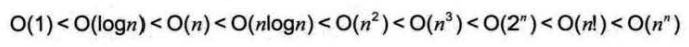
上面提到O(1)常数阶、O(logn)对数阶、O(n)线性阶、 O(n^2)平方阶等,像O(n^3),过大的n都会使得结果变得不现实,同样指数阶O(2^n)和阶乘阶O(n!)等除非是很小的n值,否则哪怕n 只是100,都会使运行时间大幅增长,所以这种不切实际的算法时间复杂度一般都不去讨论。
5.最坏情况与平均情况:
查找一个有n 个随机数字数组中的某个数字,最好的情况是数组中第一个数字就是,那么算法的时间复杂度为O(1),但也有可能这个数字在数组的最后一个位置,那么算法的时间复杂度就是O(n),这是最坏的情况。
最坏情况运行时间是一种保证,是运行时间的底线。 在应用中,这是一种最重要的需求, 通常除非特别指定, 我们提到的运行时间都是最坏情况的运行时间。
而平均运行时间是从概率的角度计算, 这个数字在每一个位置的可能性是相同的,所以发现目标元素的平均查找时间为n/2次。平均运行时间是所有情况中最有意义的,因为它是期望的运行时间,也就是当运行一段程序代码时是希望看到平均运行时间的。
但是在现实中,平均运行时间很难通过分析得到,一般都是通过运行一定数量的实验数据后估算出来的,因此一般在没有特殊说明的情况下,时间复杂度都是指最坏的时间复杂度。
6.算法空间复杂度:
写代码时完全可以用空间来换取时间,举例判断某年是不是闰年的算法,每次给一个年份都是要通过计算得到是否是闰年的结果。 另一个办法是事先建立一个有2050个元素的数组(年数略比现实多一点),然后把所有的年份按下标的数字对应,如果是闰年,此数组项的值就是1,如果不是值为0。这样,所谓的判断某一年是否是闰年,就变成了查找这个数组的某一项的值是多少的问题。
此时运算量达到了最小化,但是硬盘上或者内存中需要存储这2050个0和1,这是通过空间上的开销来换取计算时间的小技巧。
算法的空间复杂度通过计算算法所需的存储空间实现,算法空间复杂度的计算公式记作:S(n)= O(f(n)),其中,n为问题的规模,f(n)为语句关于n所占存储空间的函数。一般情况下,一个程序在机器上执行时,除了需要存储程序本身的指令、常数、变量和输入数据外,还需要存储对数据操作的存储单元,若输入数据所占空间只取决于问题本身,和算法无关,这样只需要分析该算法在实现时所需的辅助单元即可。若算法执行时所需的辅助空间相对于输入数据量而言是个常数,则称此算法为原地工作,空间复杂度为O(1)。
通常使用"时间复杂度"来指运行时间的需求,使用"空间复杂度"指空间需求,当不用限定词地使用"复杂度'时,通常都是指时间复杂度。
7.一些计算的规则:
(1)加法规则:
(2)乘法规则:
(3)一个经验:
复杂度与时间效率的关系:
c(常数) < logn < n < n*logn < n^2 < n^3 < 2^n < 3^n < n!
l------------------------------l--------------------------l--------------l
较好 一般 较差
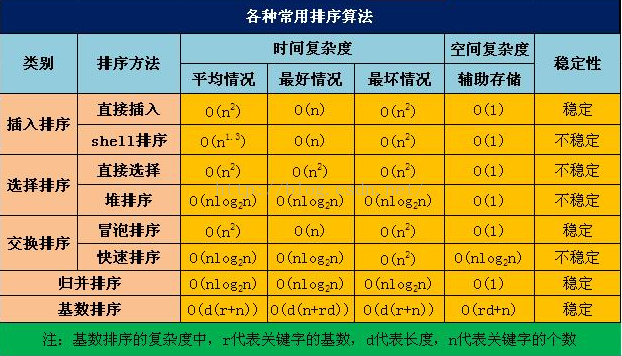
8.常用算法的时间复杂度和空间复杂度:
版权声明:本文为CSDN博主「键盘上的钢琴师_v5」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/daijin888888/article/details/66970902
