好久没写博客了,最近有点忙,然后自己也有点懒。。。。。。
最近确定自己要搞计算机视觉方向,然后就开始看斯坦福的cs231n课程,准备写系列博客记录自己的学习过程及心得。
———————————–————以下是正文——————————————————–
KNN(K-邻近算法)
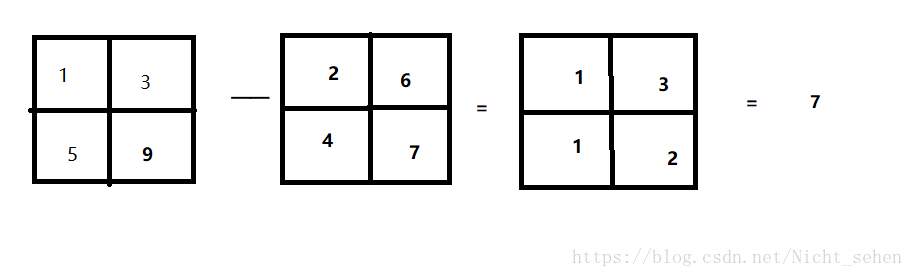
L1 distance: 曼哈顿距离
表达式:
示例:(自己简单画的,略潦草)
python实现:
import numpy as np
class KNN_L1:
def __init__(self):
pass
def train(self, x, y):
self.x_train = x
self.y_train = y
def predict(self, x):
num_test = x.shape[0]
Ypred = np.zeros(num_test, dtype=self.y_train.dtype)
# 求和
distances = np.sum(np.abs(self.x_train-x[i, :]), axis=1)
# 求最小索引
min_index = np.argmin(distances)
# 排序
Ypred[i] = self.y_train[min_index]
return Ypred
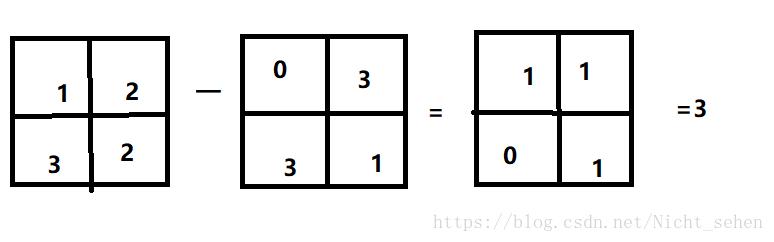
L2 distance: 欧式距离
表达式:
示例:
python代码实现
import numpy as np
class KNN_L2:
def __init__(self):
pass
def train(self,X,y):
self.X_train=X
self.y_train=y
def predict(self,X,k=1,num_loops=0):
if num_loops==0:
dists=self.compute_distances_no_loops(X)
elif num_loops==1:
dists=self.compute_distances_one_loops(X)
elif num_loops==2:
dists=self.compute_distances_one_loops(X)
return self.predict_labels(dists,k=k)
#双重循环
def compute_distances_two_loops(self,X):
num_test=X.shape[0]
num_train=self.X_train.shape[0]
dists=np.zeros((num_test,num_train))
for i in range(num_test):
for j in range(num_train):
dists[i,j]=np.sqrt(np.sum(X[i,:]-self.X_train[j,:])**2))
return dists
# 一层循环
def compute_distances_one_loop(self, X):
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
for i in range(num_test):
dists[i, :] = np.sqrt(np.sum(np.square(self.X_train - X[i, :]), axis=1))
return dists
#无循环
def compute_distances_no_loops(self, X):
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
test_sum = np.sum(np.square(X), axis=1)
train_sum = np.sum(np.square(self.X_train), axis=1)
inner_product = np.dot(X, self.X_train.T)
dists = np.sqrt(-2 * inner_product + test_sum.reshape(-1, 1) + train_sum)
return dists
def predict_labels(self, dists, k=1): # 2
num_test = dists.shape[0]
y_pred = np.zeros(num_test)
for i in range(num_test):
closest_y = []
y_indicies = np.argsort(dists[i, :], axis=0)
closest_y = self.y_train[y_indicies[: k]]
y_pred[i] = np.argmax(np.bincount(closest_y))
return y_predL1与L2区别
1.L1与坐标轴有关,会随着坐标轴改变而改变,L2不会随着坐标轴的改变而改变
2.L1适用于某个有重要意义的特征向量,L2适用于某个空间通用量,不知道其实际意义