前言
这次是针对需要网页分析的爬虫,分析过后往往会获得你需要的每节视频源地址,但是假如一节视频课是有很多节课你就必须要去一个个的去搜寻每个视频的源地址,这样一来非常浪费时间而且也没有打到我们的对于爬虫自动化的需求,于是我们就需要去对整个页面进行分析试图把它连根拔起。
这次我们准备爬取的是mooc里的猴博士电路系列。
初次尝试
打开我们的mooc找到猴博士的电路系列课程点进去第一课,F12后刷新。我分析的数据包的习惯就是先把包按照从大到小的排序

我们挨个从大到小查看,看到第二个的时候我们点击它的链接话会自动给你下载一个.m3u8文件
通过百度我们知道这m3u8文件是存放视频的,视频会被切割成十秒一份的.ts格式的视频.ts格式是日本发明的一种可以每段分段解析的一种视频格式有了这个格式我们的视频才可能实时传输,才能改变分辨率后不会从头开始播。了解了后我们用记事本(这里我用的notepad++)打开该文件。

果然不出所料这个里面确实有链接,但是好像不完整这个,于是我看了一下.m3u8的链接https://jdvodrvfb210d.vod.126.net/jdvodrvfb210d/nos/hls/2018/09/28/1010564160_9ebce033b0414784b00bacb64c0215f6_sd.m3u8?ak=7909bff134372bffca53cdc2c17adc27a4c38c6336120510aea1ae1790819de83648959c0963d7b517df373715a0a62630c89a42b26e6c7c455cd73d745bce253059f726dc7bb86b92adbc3d5b34b13258d0932fcf70014da46f4120a3f55e664426afeac364f76a817da3b2623cd41e
这个链接很长但是仔细看一下就知道.m3u8后面的是参数,使用https://jdvodrvfb210d.vod.126.net/jdvodrvfb210d/nos/hls/2018/09/28/1010564160_9ebce033b0414784b00bacb64c0215f6_sd.m3u8这个链接也能访问下载的到.m3u8的文件。仔细对比一下不难发现1010564160_9ebce033b0414784b00bacb64c0215f6_sd.m3u8这段和我们的视频片段链接很像,不难找到视频链接需要带上https://jdvodrvfb210d.vod.126.net/jdvodrvfb210d/nos/hls/2018/09/28/来凑成整的链接,于是我能不难写出这个视频的爬取代码
import requests
url = "https://jdvodrvfb210d.vod.126.net/jdvodrvfb210d/nos/hls/2018/09/28/"
m3u8 = '1010564160_9ebce033b0414784b00bacb64c0215f6_sd.m3u8'
r = requests.get(url+m3u8)
content = r.text
content = content.split('\n')
ts = []
num = 4
f = open("猴博士电路第一课.ts", 'wb')
while True:
if content[num][:7] == '#EXTINF':
res = requests.get(url+content[num+1])
f.write(res.content)
elif content[num] == '#EXT-X-ENDLIST':
break
num = num+2
f.close()
print('ok')
溯源分析
还是回到前言说说的内容,如果单纯爬取一课这么做可以,但是一系列的爬取你就需要去手动的去找每一个链接了,这样就特别麻烦那么有没有办法呢?当然是有的,我们想找寻每个链接之间的规律,最好的办法就是找到链接的来源。于是在F12里搜索1010564160_9ebce033b0414784b00bacb64c0215f6_sd.m3u8

结果还真给我搜到了https://vod.study.163.com/eds/api/v1/vod/video?videoId=1010574152&signature=45666959594f425950516d3679506e65537539334145562f665130584a4c31362b35572b633632317a5848514d7032314f756333355269334b517a4b733351446d5731704e3341334f4e2f632b67654c70557073713033564947356154724e536b55437131685a486343364b4a46646f6339766e7432544c614573414a62572f682f6d4762762f517873595a754c4b2b304e6b37536d3739344e782b585a6d3175382f38455967574e34633d&clientType=1,在它返回的json中还有两个链接,其中一个就是我们的链接,还有一个是画质更好的
嗯,现在我们可以获取了,但是我们还是没有找到这个链接的源头,通过分析不难看出链接有三个参数一个是videoId,一个是signature,还有一个是clientType,那我们就继续搜索45666959594f425950516d3679506e65537539334145562f665130584a4c31362b35572b633632317a5848514d7032314f756333355269334b517a4b733351446d5731704e3341334f4e2f632b67654c70557073713033564947356154724e536b55437131685a486343364b4a46646f6339766e7432544c614573414a62572f682f6d4762762f517873595a754c4b2b304e6b37536d3739344e782b585a6d3175382f38455967574e34633d来溯源它的上一层是什么

追查着源头我们找到了https://www.icourse163.org/web/j/resourceRpcBean.getResourceToken.rpc?csrfKey=2d65038cf3fb4f1abd72a9fa8b0023e3这个post链接,我们看到了它post的data
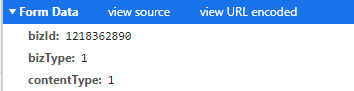
通过requests库里的post我们可以模仿浏览器向服务器的post。(这里需要添加cookies不然会返回跨区域请求)那么问题来了这个1218362890我们从何而来呢?

通过搜索找到了https://www.icourse163.org/dwr/call/plaincall/CourseBean.getLastLearnedMocTermDto.dwr它返回一个貌似是js的代码,并且找到了其它的视频的bizId那么至此我们就可以通过程序将它连根拔起了,我我们通过多线程将它全部爬取下来
import requests
import re
import threading
cookie = {
'EDUWEBDEVICE':'4e11983bda394e54ad6138086e05561b;'
# 这里为了保护自己的隐私我就没有写完自己的cookies,在写的时候需要按照上面的形式本来是等号的改成冒号,把
# 数值用键值对表示不同的用分号隔开
}
def GitID():
heards = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36',
'content-type':'text/plain'
}
data = 'callCount=1\nscriptSessionId=${scriptSessionId}190\nhttpSessionId=2d65038cf3fb4f1abd72a9fa8b0023e3\nc0-scriptName=CourseBean\nc0-methodName=getLastLearnedMocTermDto\nc0-id=0\nc0-param0=number:1450268466\nbatchId=1582376246318'
r = requests.post('https://www.icourse163.org/dwr/call/plaincall/CourseBean.getLastLearnedMocTermDto.dwr',data=data,headers=heards,cookies=cookie)
content = re.findall('id=1218\d*', r.text)
for i in range(len(content)):
content[i] = content[i][3:]
return content
def GetSignature(num):
heards = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36',
'content-type':'application/x-www-form-urlencoded'
}
data = 'bizId=%s&bizType=1&contentType=1'%(num)
r = requests.post('https://www.icourse163.org/web/j/resourceRpcBean.getResourceToken.rpc?csrfKey=2d65038cf3fb4f1abd72a9fa8b0023e3',data=data,headers=heards,cookies=cookie)
return r.json()['result']['videoSignDto']['videoId'],r.json()['result']['videoSignDto']['signature']
def GetUrl(signature):
r = requests.get('https://vod.study.163.com/eds/api/v1/vod/video?videoId=%s&signature=%s&clientType=1'%(signature[0],signature[1]))
return r.json()['result']['videos'][0]['videoUrl']
def GetMp4(Url,name):
r = requests.get(Url)
content = r.text.split('\n')
num = 4
f = open('猴博士电路%d.mp4'%(int(name)-89),'wb')
while True:
if content[num][:7] == '#EXTINF':
res = requests.get(Url[:66]+content[num+1])
f.write(res.content)
elif content[num] == '#EXT-X-ENDLIST':
break
num = num+2
f.close()
def mutilprocess():
Id = GitID()
threads = []
url = []
for i in range(len(Id)):
try:
url.append(GetUrl(GetSignature(Id[i])))
threads.append(threading.Thread(target=GetMp4,args=(url[i],Id[i][-2:])))
except:
pass
for i in range(len(threads)):
threads[i].start()
for i in range(len(threads)):
threads[i].join()
print('"猴博士电路%d.mp4"爬取完成'%(int(Id[i][-2:])-89))
if __name__ == "__main__":
mutilprocess()
print('爬取成功!')
这里对cookies还是要说一下[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4W8rd8qU-1582558032317)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20200224232144234.png)]
if name == “main”:
mutilprocess()
print(‘爬取成功!’)
这里对cookies还是要说一下
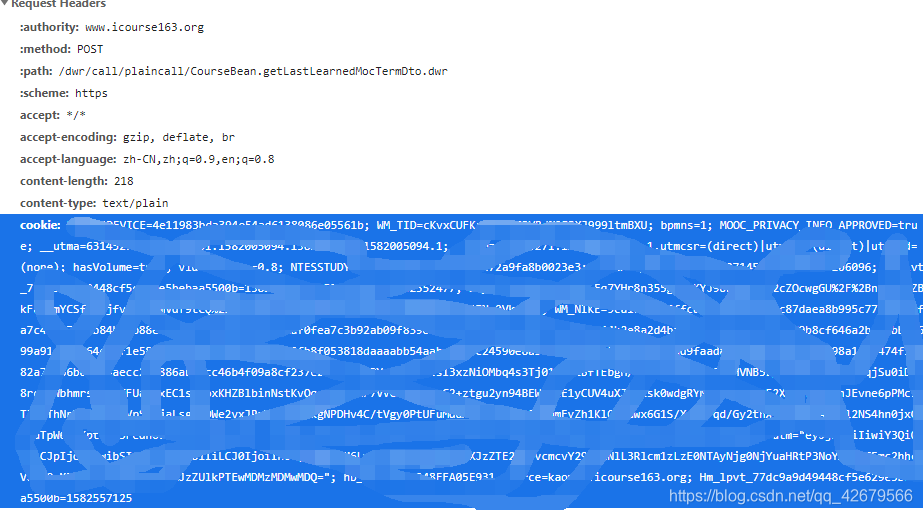
源cookies信息在F12的headers里的Requests Headers 里,但是自己要把它改写字典形式。
