Python和matlab做语音同态处理
一、同态处理
设语音信号x(n)有
式子中x1(n)和x2(n)分别是声门激励和声道激励,“*”表示卷积。
同态系统分为三个子系统。

第一个子系统:将卷积信号转化为加性信号。
第二个子系统:普通线性系统,满足线性叠加原理。
第三个子系统:将加性信号转化为卷积信号。
2、复倒谱和倒谱
复倒谱
第一步:将时域序列傅里叶变换转化为频域
第二步:对第一步结果取对数
第三步:对第二步结果进行逆变换
第三步的结果就是x(n)的复倒谱,倒谱依然是离散时域,但是跟x(n)的不同。这里叫作复倒谱频域。
倒谱
倒谱就是将上面第一步的结果取实部,再进行下面两步。
1、复倒谱进行复对数运算,倒谱进行实对数运算。
2、倒谱经过同台处理的第一个和第三个子系统之后,不能还原自身,因为计算倒谱时将自身的相位丢失了
3、利用倒谱分离语音的声门激励信号和声道冲击响应序列的信息,可以得到基频和共振峰,
4、复倒谱用来消除语音中的混响和回声,则对语音进行了增强
3、python将语音的声门激励和声道冲击响应分离
这里我用的是“蓝天白云”的一段语音,分成146帧,帧长512,采样频率8000,采样点19000,帧移128.
下面进行分析的是第51帧数据。
import numpy as np
import wave
import matplotlib.pyplot as plt
import xlsxwriter
import xlrd
import math
wlen=512
inc=128
f = wave.open(r"lantian.wav", "rb")
params = f.getparams()
nchannels, sampwidth, framerate, nframes = params[:4]
#print(nchannels,sampwidth,framerate,nframes)
str_data = f.readframes(nframes)
#print(str_data[:10])
wave_data = np.fromstring(str_data, dtype=np.short)
#print(wave_data[:10])
wave_data = wave_data*1.0/(max(abs(wave_data)))
print(wave_data[:10])
signal_length=len(wave_data) #信号总长度
if signal_length<=wlen: #若信号长度小于一个帧的长度,则帧数定义为1
nf=1
else: #否则,计算帧的总长度
nf=int(np.ceil((1.0*signal_length-wlen+inc)/inc))
print(nf)
pad_length=int((nf-1)*inc+wlen) #所有帧加起来总的铺平后的长度
zeros=np.zeros((pad_length-signal_length,)) #不够的长度使用0填补,类似于FFT中的扩充数组操作
pad_signal=np.concatenate((wave_data,zeros)) #填补后的信号记为pad_signal
indices=np.tile(np.arange(0,wlen),(nf,1))+np.tile(np.arange(0,nf*inc,inc),(wlen,1)).T #相当于对所有帧的时间点进行抽取,得到nf*nw长度的矩阵
#print(indices[:2])
indices=np.array(indices,dtype=np.int32) #将indices转化为矩阵
frames=pad_signal[indices] #得到帧信号
aaa=np.zeros(481)
aew=np.zeros(15)
windown=np.hanning(wlen)
a=frames[50:51]
b=a[0]*windown
workbook = xlsxwriter.Workbook('wy.xlsx')
worksheet = workbook.add_worksheet()
for i in range(len(b)):
worksheet.write(2,i,b[i])
workbook.close()
fft_signal = np.fft.fft(b)
ed=abs(fft_signal)
s=np.log(ed)
e=np.fft.ifft(s)
ess=e.real[0:16]
eaa=ess[1:]
es=np.zeros(15)
esa=e.real[15:497]
esb=np.zeros(15)
wew=eaa[::-1]
wq=np.concatenate((ess,aaa))
wq=np.concatenate((wq,wew))
print(wq)
wq=np.fft.fft(wq)
print(len(wq))
we=np.concatenate((es,esa))
we=np.concatenate((we,esb))
we=np.fft.fft(we)
time=np.arange(0,wlen)*framerate/wlen
time1=np.arange(0,255)/framerate
time2=np.arange(0,255)*framerate/wlen
plt.figure(figsize=(20,10))
plt.subplot(2,2,1)
plt.plot(time1,e[0:255],c="g")
plt.grid()
plt.subplot(2,2,2)
plt.plot(time2,s[0:255],c='g')
plt.grid()
plt.subplot(2,2,3)
print(len(we))
plt.plot(time2,s[0:255],time2,wq.real[0:255],c='g')
plt.grid()
plt.subplot(2,2,4)
plt.plot(time2,we.real[0:255],c="g")
plt.grid()
plt.show()
运行结果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4zWfuQCz-1574605469936)(C:\Users\jh\AppData\Roaming\Typora\typora-user-images\1574604095340.png)]](https://img-blog.csdnimg.cn/20191124222811360.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1lBT0hBSVBJ,size_16,color_FFFFFF,t_70)
图一为倒谱,图二为频率的自然对数,图三为频率的自然对数和包络(声道冲击响应),图四是声门激励信号
4、matlab将语音的声门激励和声道冲击响应分离
clear all;
clc;
clear all;
[x,Fs]=audioread('H:\语音信号处理\speech_signal\bluesky3.wav');
wlen=512;
inc=128;
win=hann(wlen);
%x=abs(x);
x=x / max(x);
N=length(x);
X=enframe(x,win,inc);
fn=size(X,1);
time=(0:N-1)/Fs;
time2=(0:255)/Fs;
%plot(time,x,'k');
ad=X(51,:);
xlswrite('H:\pycharm\wy.xlsx',ad);
aa=fft(ad);
ab=abs(aa);
ac=log(ab);
z=ifft(ac);
time1=(0:255)*Fs/wlen;
figure(1)
plot(time1,ac(1:256),'k');
grid on;
figure(2)
plot(time2,z(1:256),'k');
grid on;
n=15;
zy=z(1:n+1);
zy=[zy zeros(1,wlen-2*n-1) zy(end:-1:2)];
ZY=fft(zy);
figure(3)
plot(time1,ac(1:256),time1,real(ZY(1:256)),'k');
ft=[zeros(1,n+1) z(n+2:end-n) zeros(1,n)];
FT=fft(ft);
grid on;
figure(4)
plot(time1,real(FT(1:256)),'k');
grid on;
输出结果:
图一:倒谱
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bvKyRdXp-1574605469936)(C:\Users\jh\AppData\Roaming\Typora\typora-user-images\1574604414344.png)]](https://img-blog.csdnimg.cn/20191124222824955.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1lBT0hBSVBJ,size_16,color_FFFFFF,t_70)
图二:频率的自然对数
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TQ5ee7XJ-1574605469937)(C:\Users\jh\AppData\Roaming\Typora\typora-user-images\1574604445543.png)]](https://img-blog.csdnimg.cn/2019112422283342.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1lBT0hBSVBJ,size_16,color_FFFFFF,t_70)
图三:频率的自然对数和包络(声道冲击响应)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BfPirskC-1574605469937)(C:\Users\jh\AppData\Roaming\Typora\typora-user-images\1574604475959.png)]](https://img-blog.csdnimg.cn/2019112422284431.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1lBT0hBSVBJ,size_16,color_FFFFFF,t_70)
图四:声门激励信号
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pLgByd4v-1574605469938)(C:\Users\jh\AppData\Roaming\Typora\typora-user-images\1574604534763.png)]](https://img-blog.csdnimg.cn/20191124222849435.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1lBT0hBSVBJ,size_16,color_FFFFFF,t_70)
5、算法分析
包络(声道冲击响应)是倒谱的低频部分,声门激励信号是倒谱的高频。
参考:
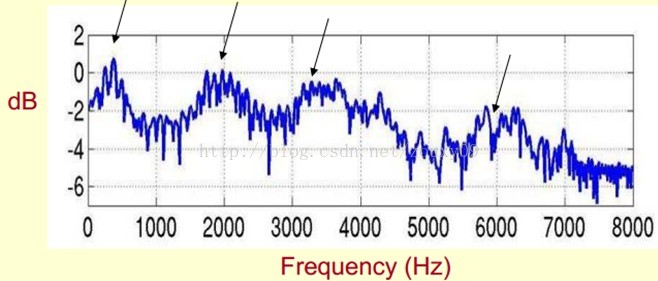
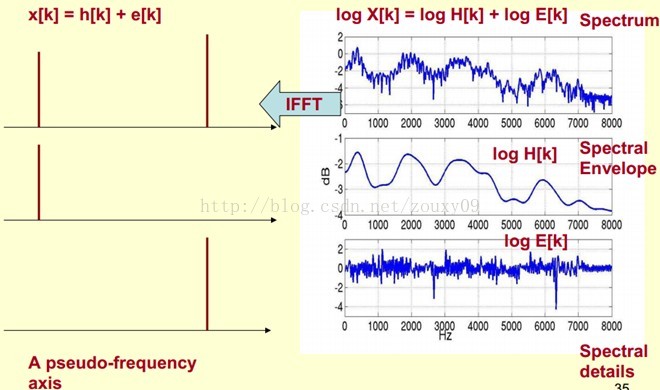
下面是一个语音的频谱图。峰值就表示语音的主要频率成分,我们把这些峰值称为共振峰(formants),而共振峰就是携带了声音的辨识属性(就是个人身份证一样)。所以它特别重要。用它就可以识别不同的声音。
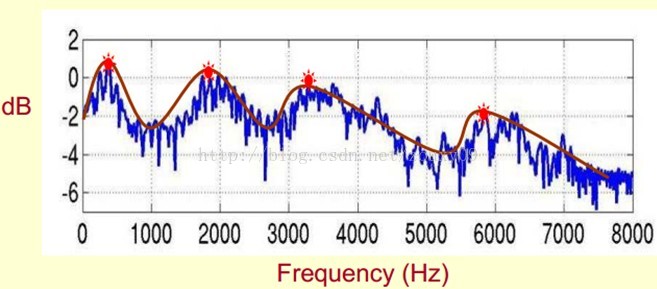
既然它那么重要,那我们就是需要把它提取出来!我们要提取的不仅仅是共振峰的位置,还得提取它们转变的过程。所以我们提取的是频谱的包络(Spectral Envelope)。这包络就是一条连接这些共振峰点的平滑曲线。
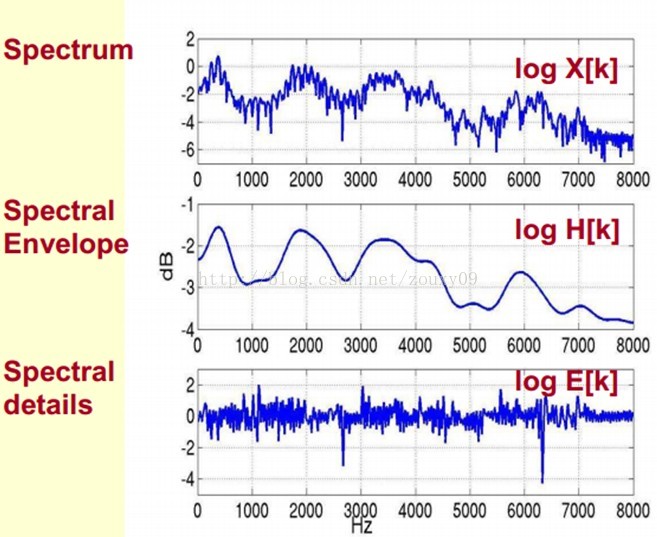
我们可以这么理解,将原始的频谱由两部分组成:包络和频谱的细节。这里用到的是对数频谱,所以单位是dB。那现在我们需要把这两部分分离开,这样我们就可以得到包络了。
那怎么把他们分离开呢?也就是,怎么在给定log X[k]的基础上,求得log H[k] 和 log E[k]以满足log X[k] = log H[k] + log E[k]呢?
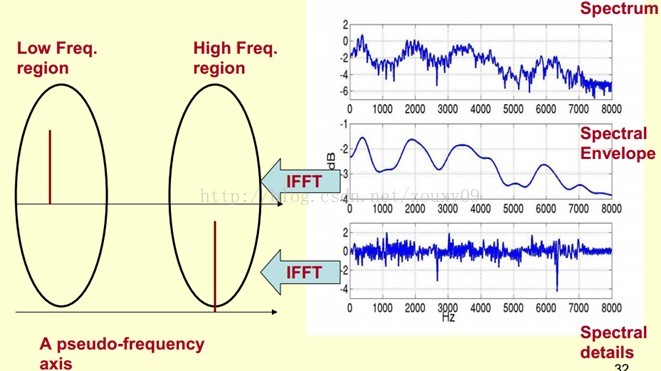
为了达到这个目标,我们需要Play a Mathematical Trick。这个Trick是什么呢?就是对频谱做FFT。在频谱上做傅里叶变换就相当于逆傅里叶变换Inverse FFT (IFFT)。需要注意的一点是,我们是在频谱的对数域上面处理的,这也属于Trick的一部分。这时候,在对数频谱上面做IFFT就相当于在一个伪频率(pseudo-frequency)坐标轴上面描述信号。
由上面这个图我们可以看到,包络是主要是低频成分(这时候需要转变思维,这时候的横轴就不要看成是频率了,咱们可以看成时间),我们把它看成是一个每秒4个周期的正弦信号。这样我们在伪坐标轴上面的4Hz的地方给它一个峰值。而频谱的细节部分主要是高频。我们把它看成是一个每秒100个周期的正弦信号。这样我们在伪坐标轴上面的100Hz的地方给它一个峰值。
把它俩叠加起来就是原来的频谱信号了。
在实际中咱们已经知道log X[k],所以我们可以得到了x[k]。那么由图可以知道,h[k]是x[k]的低频部分,那么我们将x[k]通过一个低通滤波器就可以得到h[k]了!没错,到这里咱们就可以将它们分离开了,得到了我们想要的h[k],也就是频谱的包络。
x[k]实际上就是倒谱Cepstrum(这个是一个新造出来的词,把频谱的单词spectrum的前面四个字母顺序倒过来就是倒谱的单词了)。而我们所关心的h[k]就是倒谱的低频部分。h[k]描述了频谱的包络,它在语音识别中被广泛用于描述特征。
那现在总结下倒谱分析,它实际上是这样一个过程:
1)将原语音信号经过傅里叶变换得到频谱:X[k]=H[k]E[k];
只考虑幅度就是:|X[k] |=|H[k]||E[k] |;
2)我们在两边取对数:log||X[k] ||= log ||H[k] ||+ log ||E[k] ||。
3)再在两边取逆傅里叶变换得到:x[k]=h[k]+e[k]。
这实际上有个专业的名字叫做同态信号处理。它的目的是将非线性问题转化为线性问题的处理方法。对应上面,原来的语音信号实际上是一个卷性信号(声道相当于一个线性时不变系统,声音的产生可以理解为一个激励通过这个系统),第一步通过卷积将其变成了乘性信号(时域的卷积相当于频域的乘积)。第二步通过取对数将乘性信号转化为加性信号,第三步进行逆变换,使其恢复为卷性信号。这时候,虽然前后均是时域序列,但它们所处的离散时域显然不同,所以后者称为倒谱频域。
总结下,倒谱(cepstrum)就是一种信号的傅里叶变换经对数运算后再进行傅里叶反变换得到的谱。它的计算过程如下:

关于滤波的分界点我百度别人是这样说的:(先贴过来,反正不懂)
采样频率为16000HZ,认为基音频率都应低于500HZ,为了留有余量,取16000/550=29,即在倒谱域中第29条谱线之前是反映了包络的系数。所以取29就是这样得来的。
倒谱中横坐标不是频率,而是倒频率(quefrency,量纲是时间),它的刻度同时间序列中x对应的刻度相同,在FFT(x)以后包络的起伏比较缓,就是它的倒频率低。倒频谱中的横轴也反映了在采样频率16000下不同频率的周期,550Hz的周期为29,即第29条谱线。在大于第29条谱线以后的谱线,对应的信号分量的频率都要小于550Hz,即在基频的区间中。在倒频率范围中我们取小于550Hz的倒频谱来求包络。
“时间轴是不是也应该像FFT频率轴一样对称,中间是0点”,这说法不完全正确。fft(x)后第1条谱线对应的频率为0,要经过fftshift后才把对应的频率为0的谱线转换到中间。同样在求倒谱后第1条谱线对应时间为0。
刻度相同,在FFT(x)以后包络的起伏比较缓,就是它的倒频率低。倒频谱中的横轴也反映了在采样频率16000下不同频率的周期,550Hz的周期为29,即第29条谱线。在大于第29条谱线以后的谱线,对应的信号分量的频率都要小于550Hz,即在基频的区间中。在倒频率范围中我们取小于550Hz的倒频谱来求包络。
“时间轴是不是也应该像FFT频率轴一样对称,中间是0点”,这说法不完全正确。fft(x)后第1条谱线对应的频率为0,要经过fftshift后才把对应的频率为0的谱线转换到中间。同样在求倒谱后第1条谱线对应时间为0。
我这里的抽样频率是8000,所以取15
