什么是.class
Java源文件被编译后被Java虚拟机所执行的代码使用了一种平台中立(不依赖于特定硬件及操作系统)的二进制格式来表示,并且经常(但并非绝对)以文件的形式存储,因此这种格式成为class文件格式。class文件格式中精确地定义了类与接口的表示形式。
每个class文件都由字节流组成,每个字节含有8个二进制位,所有16位,32位和64位长度的数据将通过构造2个、4个和8个连续的8位字节来表示。在Java SDK中,可以使用java.io.DataInput、java.io.DataOutput等接口和java.io.DataInputStream和java.io.DataOutputStream等类来访问这种格式的数据。
ClassFile结构
每个class文件对应一个如下所示的ClassFile结构:
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
}
《Optimizing Java》的作者编了一句顺口溜帮忙记住上面这十部分:“My Very Cute Animal Turns Savage In Full Moon Areas.”

JVM规范专门定义了一组专用的数据类型来表示class文件的内容,它们包括u1、u2和u4,分别代表1、2和4个字节的无符号数。对于其他类型如cp_info、field_info等都是复合结构,介绍到再详细讲。
准备
在本次分析字节码的过程中以下代码将一直陪伴我们,我们将分析它的class文件:
package bytecode;
public class Test1 {
private int a = 1;
public int getA() {
return a;
}
public void setA(int a) {
this.a = a;
}
}
class文件是16进制的数据,需要使用WinHex打开,先下载安装吧!打开class文件如下所示(看不懂没关系,有规则的):
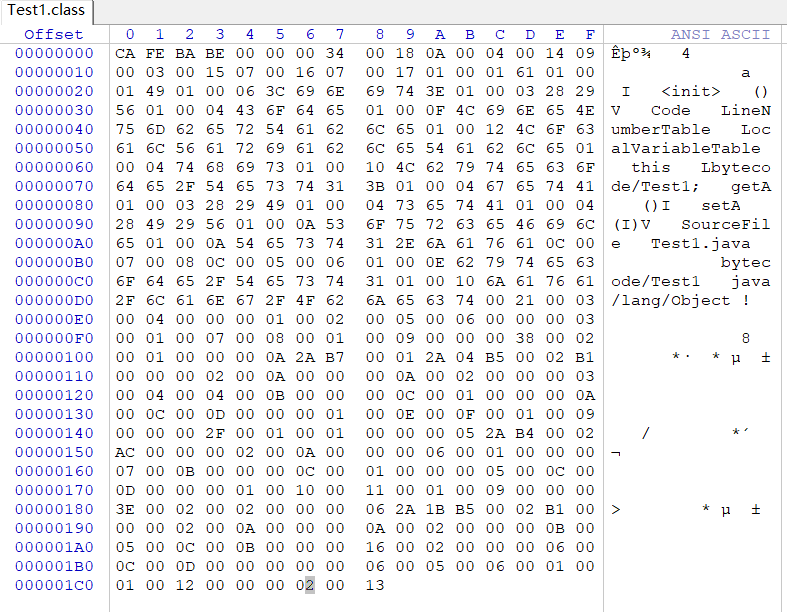
为了判断我们的分析结果我们可以使用javap -verbose <filename>命令让Java告诉我们class文件的详细信息。
魔数
所有的.class字节码文件的前4个字节都是魔数,魔数值为固定值:0xCAFEBABE。它的作用是确定这个文件是否为一个能被虚拟机所接受的class文件。
版本号
继魔数之后的4个字节是版本信息,其中前2个字节为minor_version(副版本号),后2个字节为(主版本号)。如这次使用的Test1.class文件中的版本信息为00 00 00 34,转换为十进制则副版本号为0,主版本号为52。
常量池计数器
紧接着版本号的2个字节为constant_pool_count(常量池计数器),此数值表示常量池中成员的数目。如这次使用的Test1.class文件中的版本信息为00 18,转换为十进制为24,说明常量池数目为24个。但是,我们查看javap给我们的信息可以发现实际上常量池数目为23。
注意:常量池数组中元素的个数 = 常量池数 - 1(其中0暂时不使用),目的是满足某些常量池索引值的数据在特定情况下需要表达【不引用任何一个常量池】的含义;根本原因在于,索引为0也是一个常量(保留常量),只不过它不位于常量表中,这个常量就对应null值,所以常量池的索引从1而非0开始。
常量池
一个Java类中定义的很多信息都是由常量池来维护和描述的,可以将常量池看作是Class文件的资源仓库,比如说Java类中定义的方法与变量信息,都是存储在常量池中。常量池中主要存储两类常量:字面量与符号引用。字面量如文本字符串,Java中声明为final的常量值等,而符号引用如类和接口的全限定名,字段的名称和描述符,方法的名称和描述符等。
常量池中的每一项都具备相同的特征——第1个字节作为类型标记,用于确定该项的格式,这个字节成为tag byte(标记字节、标签字节)。
常量池表中的所有项都具有如下通用格式。
cp_info {
u1 tag;
u1 info[];
}
在常量池表中,每个cp_info项都必须表示cp_info类型的单字节"tag"项开头。后面info[]数组的内容由tag的值所决定。有效的tag和对应的值如下表所示。每个tag字节之后必须有两个或更多的字节,这些字节用于指定这个常量的信息,附加信息的格式由tag的值来决定。
| 名称 | 项目 | 类型 | 描述 |
| CONSTANT_Utf8_info | |||
| tag | u1 | 值为1 | |
| length | u2 | UTF-8编码的字符串长度 | |
| bytes | u1 | 长度为length的UTF-8编码的字符串 | |
| CONSTANT_Integer_info | |||
| tag | u1 | 值为3 | |
| bytes | u4 | 按照高位在前存储的int值 | |
| CONSTANT_Float_info | |||
| tag | u1 | 值为4 | |
| bytes | u4 | 按照高位在前存储的float值 | |
| CONSTANT_Float_info | |||
| tag | u1 | 值为5 | |
| bytes | u8 | 按照高位在前存储的long值 | |
| CONSTANT_Double_info | |||
| tag | u1 | 值为6 | |
| bytes | u8 | 按照高位在前存储的double值 | |
| CONSTANT_Class_info | |||
| tag | u1 | 值为7 | |
| index | u2 | 指向全限定名常量项的索引。 | |
| CONSTANT_String_info | |||
| tag | u1 | 值为8 | |
| index | u2 | 指向字符串字面量的索引。 | |
| CONSTANT_Fieldref_info | |||
| tag | u1 | 值为9 | |
| index | u2 | 指向声明字段的类或者接口描述符CONSTANT_Class_info的索引项 | |
| index | u2 | 指向字段描述符CONSTANT_NameAndType_info的索引项 | |
| CONSTANT_Methodref_info | |||
| tag | u1 | 值为10 | |
| index | u2 | 指向声明方法的类描述符CONSTANT_Class_info的索引项 | |
| index | u2 | 指向名称及类型描述符CONSTANT_NameAndType_info的索引项 | |
| CONSTANT_InterfaceMethodref_info | |||
| tag | u1 | 值为11 | |
| index | u2 | 指向声明方法的接口描述符CONSTANT_Class_info的索引项 | |
| index | u2 | 指向名称及类型描述符CONSTANT_NameAndType_info的索引项 | |
| CONSTANT_NameAndType_info | |||
| tag | u1 | 值为12 | |
| index | u2 | 指向改字段或方法名称常量项的索引 | |
| index | u2 | 指向该字段或方法描述符常量项的索引 | |
| CONSTANT_MethodHandle_info | |||
| tag | u1 | 值为15 | |
| kind | u1 | 值必须在1~9之间,表示方法句柄的类型 | |
| index | u2 | 指向该方法 常量项的索引 | |
| CONSTANT_MethodType_info | |||
| tag | u1 | 值为16 | |
| index | u2 | 指向该方法类型描述符常量项的索引 | |
| CONSTANT_InvokeDynamic_info | |||
| tag | u1 | 值为18 | |
| index | u2 | 对当前class文件中引导方法表的bootstrap_methods数组的有效索引 | |
| index | u2 | 对常量项的索引,必须为CONSTANT_NameAndType_info结构 |
上表记不住?没关系,不必要去记,会查就行。看不懂,没关系,马上教!
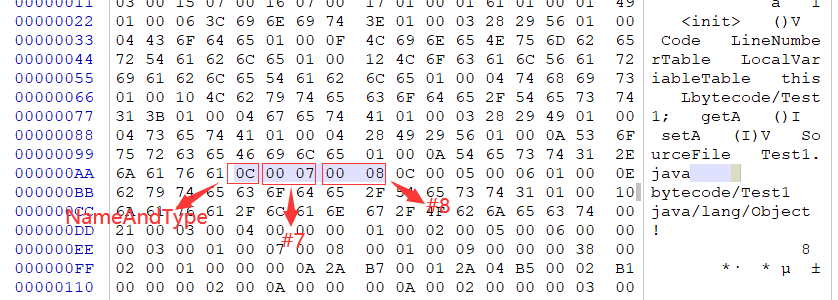
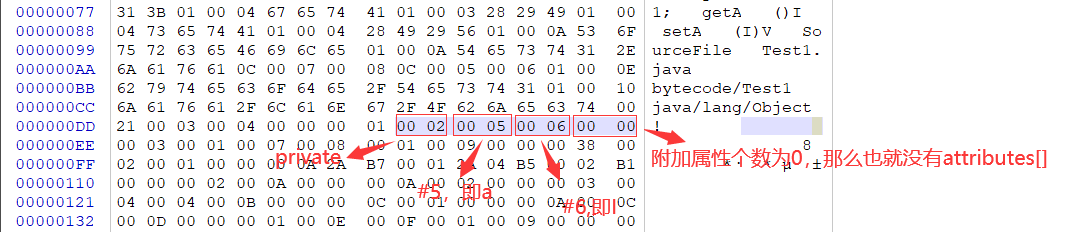
继Constant_pool_count后就是常量池了,我们知道常量池中的每一项都具备相同的特征——第1个字节作为类型标记。查看Test1.class字节码,tag为0x0A,十进制为10,查表得类型为CONSTANT_Methodref_info,该类型除tag外还有两个u2类型的index,所以接着数4个字节,前2个字节(0x0004表示4),后2个字节(0x0014表示20),OK!我们得到了第一个常量:#1=Methodref #4.#20。由于我们还没分析完所以暂时不知道引用的具体常量项含义。
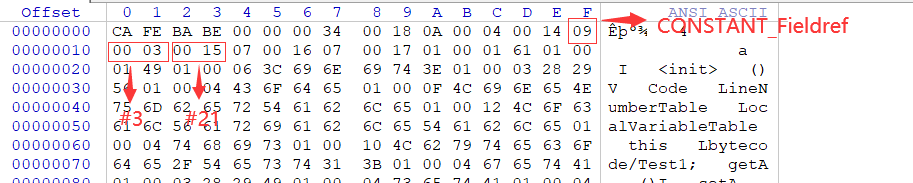
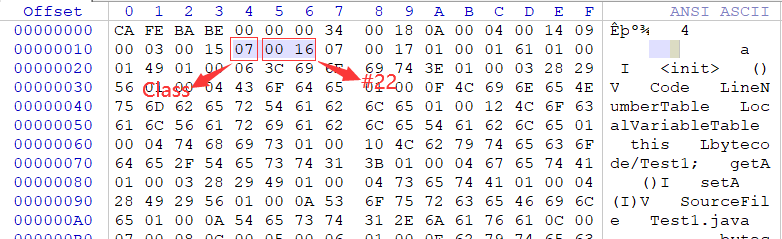
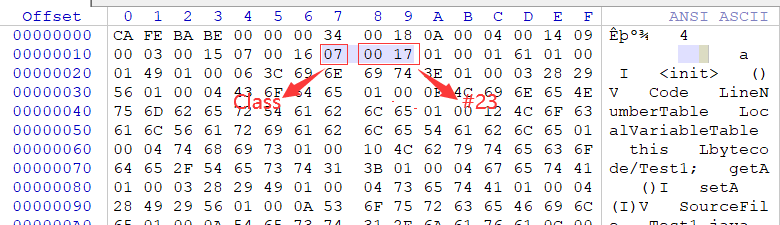
接下来的类型是Constant_Utf8,除tag外length和bytes分别代表不同含义,length表示给Utf8字符串的占多少个字节,比如占5个字节,那么我们往后数5个字节的数据就是该字符串表示的具体内容了(就是bytes)。
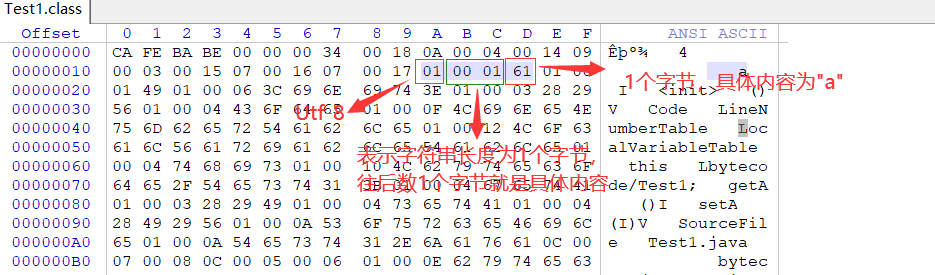
按照上述方法分析出索引5~19之间的Utf8类型的数据如下:
#5 = Utf8 a
#6 = Utf8 I
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code
#10= Utf8 LineNumberTable
#11= Utf8 LocalVariableTable
#12= Utf8 this
#13= Utf8 Lbytecode/Test1;
#14= Utf8 getA
#15= Utf8 ()I
#16= Utf8 setA
#17= Utf8 (I)V
#18= Utf8 SourceFile
#19= Utf8 Test1.java
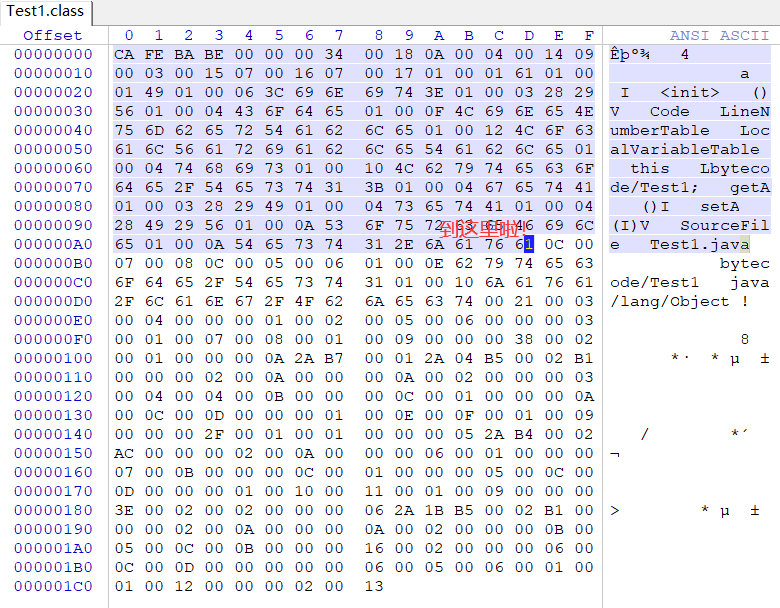
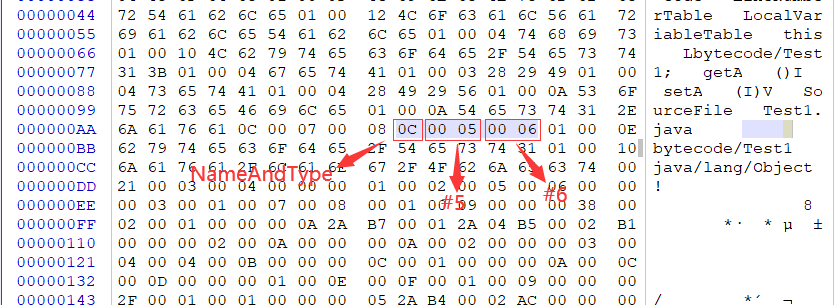
最后的两个常量项都是Utf8类型,值为:
#22= Utf8 bytecode/Test1
#23= Utf8 java/lang/Object
至此常量池中的所有项都分析完了,我们可以根据引用的索引项写上注释,结果如下所示:
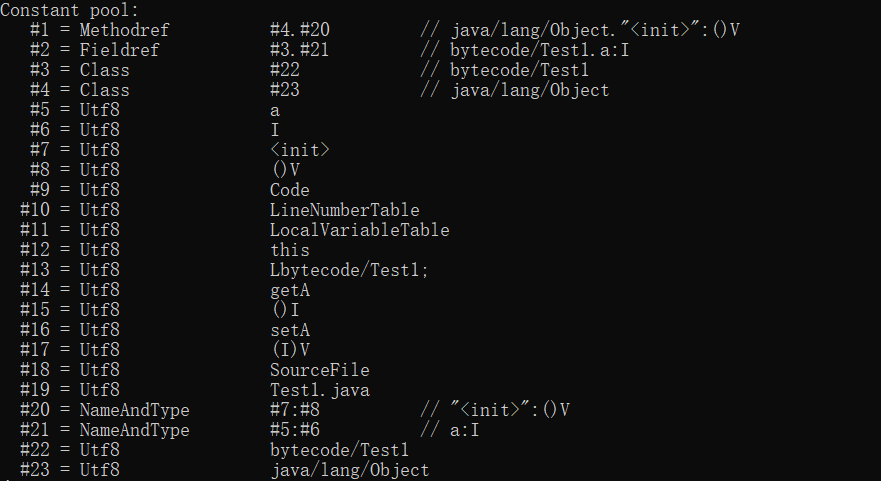
Constant_pool:
#1 = Methodref #4.#20 //java/lang/Object.<init>:()V
#2 = Fieldref #3.#21 //bytecode/Test1.a:I
#3 = Class #22 //bytecode/Test1
#4 = Class #23 //java/lang/Object
#5 = Utf8 a
#6 = Utf8 I
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code
#10= Utf8 LineNumberTable
#11= Utf8 LocalVariableTable
#12= Utf8 this
#13= Utf8 Lbytecode/Test1;
#14= Utf8 getA
#15= Utf8 ()I
#16= Utf8 setA
#17= Utf8 (I)V
#18= Utf8 SourceFile
#19= Utf8 Test1.java
#20= NameAndType #7:#8 //<init>:()V
#21= NameAndType #5:#6 //a:I
#22= Utf8 bytecode/Test1
#23= Utf8 java/lang/Object
也许您会疑惑诸如()V,Lbytecode/Test1;等书写方式,读完下面这三段就知道了:
-
在JVM规范中,每个变量/字段都有描述信息,描述信息主要的作用是描述字段的数据类型、方法的参数列表(包括数量、类型与顺序)与返回值。根据描述符规则,基本数据类型和代表无返回值的void类型都用一个大写字符来表示,对象类型则使用字符L加对象的全限定名来表示。为了压缩字节码文件的体积,对于基本数据类型,JVM都只使用一个大写字母来表示,B - byte,C - char,D - double,F - float,I - int,J - long,S - short,Z - boolean,V - void,L - 对象类型,如Ljava/lang/String;
-
对于数组类型来说,每一个维度使用一个前置的[来表示,如int[]被记录为[I,String[][]被记录为[[Ljava/lang/String;
-
用描述符描述方法时,按照先参数列表,后返回值的顺序来描述。参数列表按照参数的严格顺序放在一组()之内,如方法String
setNameAndAge(String name,int
age)的描述符为:(Ljava/lang/String;,I)Ljava/lang/String;
对比javap命令分析的结果,完美!OK,分析常量池就结束了,接下来文章将分析余下的结构。
访问权限
紧接着常量池的2个字节是access_flags,它的值表示某个类或者接口的访问权限及属性。每个标志的取值及其含义如下表所示:
| 标志名 | 值 | 含义 |
| ACC_PUBLIC | 0x0001 | 声明为public,可以包外访问 |
| ACC_FINAL | 0x0010 | 声明为final,不允许有子类 |
| ACC_SUPER | 0x0020 | 当用到invokespecial指令时,需要对父类方法做特殊处理 |
| ACC_INTERFACE | 0x0200 | 该class文件定义的是接口而不是类 |
| ACC_ABSTRACT | 0x0400 | 声明为abstract,不能被实例化 |
| ACC_SYNTHETIC | 0x1000 | 声明为synthetic,表示该class文件并非由java源代码所生成 |
| ACC_ANNOTATION | 0x2000 | 标识注解类型 |
| ACC_ENUM | 0x4000 | 标识枚举类型 |
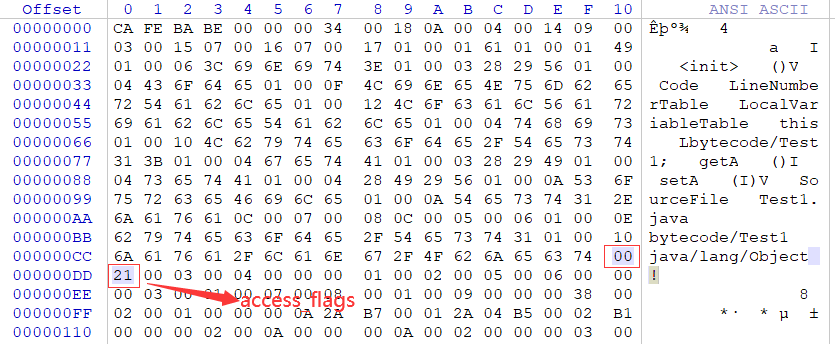
示例代码的字节码显示access_flags为0x0021,可是表中没有这个值呀??这是因为JVM将不同的值进行加法运算得到不同的组合,这里就是ACC_SUPER和ACC_PUBLIC。ACC_SUPER可以不用管它,只需要知道ACC_PUBLIC,即这个类使用public修饰,确实如此。
类和父类
继access_flags后的4个字节表当前类名索引和父类名索引,具体的值在常量池中。如图所示,this_class值为3,super_class值为4,分别对应常量池中的bytecode/Test1和java/lang/Object。如果这个class文件的super_class值为0,那么这个class文件只可能用来表示Object类,因为它是唯一没有父类的类。
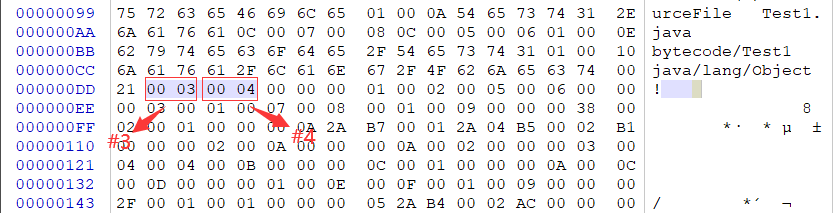
接口
接下来的4个字节与接口有关(如果有父接口的话是4个字节,无父接口则仅为2个字节)。前2个字节的interfaces_count(接口计数器)表示当前类或接口的直接超接口量。后2个字节的interfaces[](接口表)中的每个成员的值必须是对常量池表中某项的有效索引,它的长度为interfaces_count。每个interfaces[i]必须为CONSTANT_Class_info结构,其中0<=i<interfaces_count。在interfaces[]中,各成员所表示的接口顺序和对应的源代码中给定的接口顺序(从左至右)一样,即interfaces[0]对应的是源代码中最左边的接口。如果interfaces_count为0,那么在字节码中是不存在interfaces[]的。
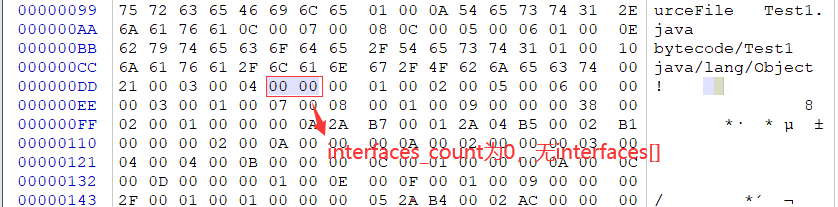
成员字段
接下来的2个字节表示fields_count(字段计数器),它的值表示当前class文件fields表的成员个数。当前字节码中的值为0x0001(十进制为1),我只声明了一个实例字段a。fields表中每个成员都是一个field_info结构(如下所示),用于表示该类或接口所声明的类字段(static修饰)或者实例字段。
field_info {
u2 access_flags;
u2 name_index;
u2 descriptor_index;
u2 attributes_count;
attribute_info attributes[attributes_count];
}
field_info结构各项的说明如下:
- access_flags:它的值用来表示字段的访问权限和基本属性。具体如下表所示:
| 标志名 | 值 | 含义 |
| ACC_PUBLIC | 0x0001 | 声明为public,可以包外访问 |
| ACC_PRIVATE | 0x0002 | 声明为private,只能在定义该字段的类中访问 |
| ACC_PROTECTED | 0x0004 | 声明为protected,子类可以访问 |
| ACC_STATIC | 0x0008 | 声明为static |
| ACC_FINAL | 0x0010 | 声明为final,对象构造好之后就不能直接设置该字段了 |
| ACC_VOLATILE | 0x0040 | 声明为volatile,被标识的字段无法缓存 |
| ACC_TRANSIENT | 0x0080 | 声明为transient,被标识的字段不会为持久化对象管理器所写入或读取 |
| ACC_SYNTHETIC | 0x1000 | 被表示的字段由编译器产生,而没有写在源代码中 |
| ACC_ENUM | 0x4000 | 该字段声明为某个枚举类型(enum)的成员 |
-
name_index:顾名思义,这是表示字段名称的索引。它的值必须是常量池中的一个有效索引,且必须为CONSTANT_Utf8_info结构。
-
descriptor_index:它的值也必须是常量池中的一个有效索引,且必须是CONSTANT_Utf8_info结构。
-
attributes_count:它的值表示当前字段的附加属性(attribute_info)的数量。
-
attributes[]:属性表(attributes[])中的每个成员,其值必须是attribute_info结构(如下表示的是一个通用属性结构)。一个字段可以管理任意多个属性。
attribute_info {
u2 attribute_name_index;
u4 attribute_length;
u1 info[attribute_length];
}
示例class文件的分析如下:
方法
接下来的2个字节表示methods_count(方法计数器),表示当前class文件methods表的成员个数。methods表中的每个成员都是一个method_info结构。methods[](方法表)中的每个成员都必须是一个method_info结构,用于表示当前类或接口中某个方法的完整描述。
method_info {
u2 access_flags;
u2 name_index;
u2 descriptor_index;
u2 attributes_count;
attribute_info attributes[attributes_count];
}
method_info结构各项的说明如下:
- access_flags:它的值用来表示字段的访问权限和基本属性。具体如下表所示:
| 标志名 | 值 | 含义 |
| ACC_PUBLIC | 0x0001 | 声明为public,可以包外访问 |
| ACC_PRIVATE | 0x0002 | 声明为private,只能在定义该方法的类中访问 |
| ACC_PROTECTED | 0x0004 | 声明为protected,子类可以访问 |
| ACC_STATIC | 0x0008 | 声明为static |
| ACC_FINAL | 0x0010 | 声明为final,不能被覆盖 |
| ACC_SYNCHRONIZED | 0x0020 | 声明为synchronized,对该方法的调用,将包装在同步锁(monitor)里 |
| ACC_BRIDGE | 0x0040 | 声明为bridge方法,由编译器产生 |
| ACC_TRANSIENT | 0x0080 | 声明为transient,被标识的字段不会为持久化对象管理器所写入或读取 |
| ACC_VARARGS | 0x0080 | 表示方法带有变长参数 |
| ACC_NATIVE | 0x0100 | 声明为native,该方法不是用Java语言实现 |
| ACC_ABSTRACT | 0x0400 | 声明为abstract,该方法没有实现代码 |
| ACC_STRICT | 0x0800 | 声明为strictfp,使用FP-strict浮点模式 |
| ACC_SYNTHETIC | 0x1000 | 该方法是由编译器合成的,而不是由源代码编译 |
-
name_index:顾名思义,这是表示字段名称的索引。它的值必须是常量池中的一个有效索引,且必须为CONSTANT_Utf8_info结构。
-
descriptor_index:它的值也必须是常量池中的一个有效索引,且必须是CONSTANT_Utf8_info结构。
-
attributes_count:它的值表示当前字段的附加属性(attribute_info)的数量。
-
attributes[]:属性表(attributes[])中的每个成员,其值必须是attribute_info结构。一个字段可以管理任意多个属性。方法中重点在于Code属性。有点复杂
在实例代码的class文件中可以看见methods_count值为0x0003,说明代码中有3个方法,虽然我们只是声明了两个方法,可是我们不要忘记了无参构造方法,所以共有3个方法。
接下来开始分析第一个方法。根据method_info结构,第一个access_flag属性为0x0001(public),第二个name_index属性为0x0007(#7),第三个descriptor_index属性为0x0008(#8),第四个attributes_count属性为0x0001(十进制为1),说明附加属性数量为1。不难发现第一个方法就是自动生成的无参构造方法了。

根据attribute_info结构,第一个属性的name_index为0x0009,对应常量池中的Code。紧接着是4个字节的属性长度0x00000038(十进制为56),说明Code属性长度为56字节。接下来是分析这56个字节的内容了,前提是我们需要了解Code这个属性,这是JVM预定义的一个属性。其结构如下:
Code_attribute {
u2 attribute_name_index;
u4 attribute_length;
u2 max_stack;
u2 max_locals;
u4 code_length;
u1 code[code_length];
u2 exception_table_length;
{
u2 start_pc;
u2 end_pc;
u2 handler_pc;
u2 catch_type;
} exception_table[exceptionn_table_length];
u2 attributes_count;
attribute_info attributes[attributes_count];
}
Code_attribute结构各项的说明如下:
- attribute_name_index:其值必须是对常量池的一个有效索引。常量池表在该索引处的成员必须是CONSTANT_Utf8_info结构,用以表示字符串"Code"。
- attribute_length:表示当前属性的长度,不包括初始的6个字节(attribute_name_index和attribute_length)
- max_stack:当前方法的操作数栈在方法执行的任何时间点的最大深度
- max_locals:分配在当前方法引用的局部变量表中的局部变量个数,其中也包括调用此方法时用于传递参数的局部变量。
- code_length:当前方法code[]数组的字节数,值必须大于0,即code[]数组不能为空
- code[]:实现当前方法的Java虚拟机代码的实际字节内容
- exception_table_length:exception_table表的成员个数
- exception_table[]:数组每个成员表示code[]数组中的一个异常处理器。同时exception_table[]的每个成员包含如下4项:
- start_pc和end_pc:表明了异常处理器在code[]中的有效范围。start_pc的值必须是对当前code[]中某一指令操作码的有效索引,end_pc的值要么是对当前code[]中某一指令操作码的有效索引,要么等于code_length的值。start_pc的值必须比end_pc小。当程序计数器在范围[start_pc,end_p)内时,异常处理器就将生效。
- handler_pc:表示一个异常处理器的起点。handler_pc的值必须同时是对当前code[]和其中某一指令操作码的有效索引。
- catch_type:如果catch_type的值不为0,那么它必须是对常量池表的一个有效索引。常量池表在该索引处的成员必须是CONSTANT_Class_info结构,用以表示当前异常处理器需要捕捉的异常类型。只有当抛出的异常是指定的类或者其子类的实例时,才会调用异常处理器。
- attributes_count:表示Code属性中attributes[]数组中成员的个数。
- attribute[]:属性表中的每个值都必须是attribute_info结构体,Code属性可以关联任意多个属性。
接下来数56个字节,开始从max_stack开始分析(切勿从attribute_name_index开始分析,已经分析过了)。
maxstack 2
maxlocals 1
code_length 10
也许大家会有疑惑了,无参构造方法是没有参数的呀!怎么maxlocals的值是1呢?那不是说明有一个局部变量吗?如果您学习过pyhton就知道python的方法中第一个参数必须是self,表示当前对象。Java在方法内部我们经常使用
this.xxx获取对象中的属性,方法。所以这个隐藏的局部变量就是this。
知道的code_length为10我们可以很简单的查看code具体的内容了,注意,这里说的内容不是Java代码,而是指令集对应的十六进制编号:

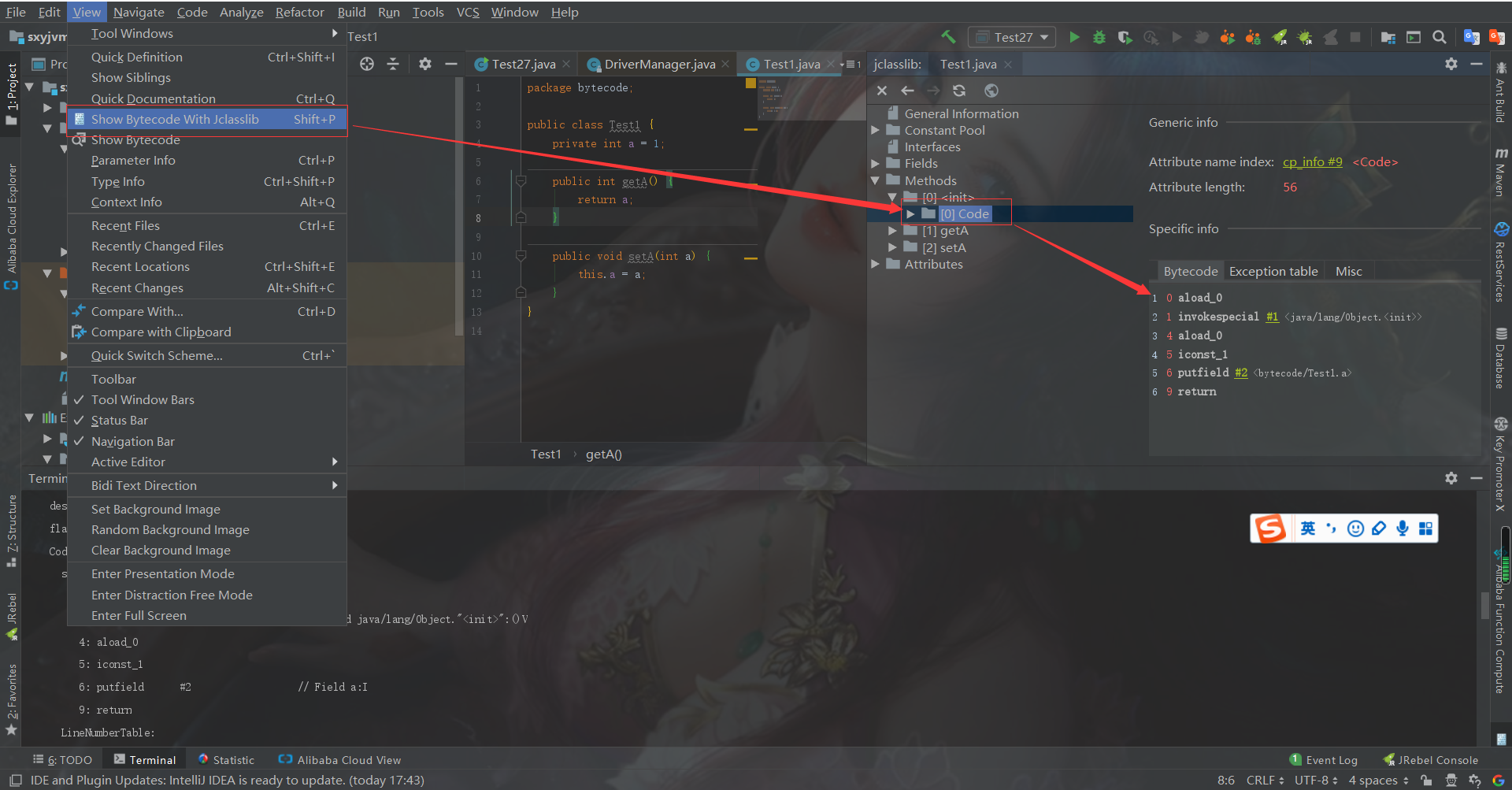
我们通过这10个字节的16进制是很难得到下面的指令集的,这时候我们就可以开始使用插件来帮助我们了。
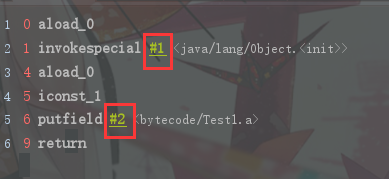
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: aload_0
5: iconst_1
6: putfield #2 // Field a:I
9: return
IDEA为我们提供了名为jclasslib的插件,通过它也提供非插件版供我们下载使用。https://github.com/ingokegel/jclasslib
我们点击具体的助记符还会自动打开对应的官方文档,帮助我们更清楚的了解助记符的含义。以上助记符对应的十六进制编号如下所示:
aload_0 0x2a
invokespecial 0xb7
iconst_1 0x4
putfield 0xb5
return 0xb1

注意:红色框部分表示的是额外的参数。
接下来分析exception_table_length,值为0x0000,说明异常表成员数量为0。
LineNumberTable
紧接着是attributes_count,值为0x0002,说明有两个附件属性。根据attribute_info结构,第一个属性的name_index为0x000A,对应常量池中的LineNumberTable。
LineNumberTable属性是可选的变长属性,位于Code结构的属性中。它被调试器用于确定源文件中由给定的行号所表示的内容,对应于Java虚拟机cod[]数组中的哪一部分。在Code属性的属性表中,LineNumberTable属性可以按照任意顺序出现。在Code属性attributes表中,可以有不止一个LineNumberTable属性对应于源文件中的同一行。也就是说,多个LineNumberTable属性可以合起来表示源文件中的某行代码,属性与源文件的代码行之间不必有一一对应的关系。
LineNumberTable的结构如下所示:
LineNumberTable_attribute {
u2 attribute_name_index;
u4 attribute_length;
u2 line_number_table_length;
{
u2 start_pc;
u2 line_number;
} line_number_table[line_number_table_length];
}
LineNumberTable结构各项的说明如下:
- attribute_name_index:其值必须是对常量池的一个有效索引。常量池表在该索引处的成员必须是CONSTANT_Utf8_info结构,用以表示字符串"LineNumberTable"。
- attribute_length:表示当前属性的长度,不包括初始的6个字节(attribute_name_index和attribute_length)
- line_number_table_length:表示line_number_table[]数组的成员个数。
- line_number_table[]:数组的每个成员都表明源文件中的行号会在code数组中的哪一条指令处发生变化。line_number_table的每个成员都具有如下两项:
- start_pc:其值必须是code[]数组的一个索引,code[]在该索引处的指令码,表示源文件中新的行的起点。start_pc的值必须小于当前LineNumberTable属性所在的Code属性的code_length的值。
- line_number:其值必须与源文件中对应的行号相匹配。
接着分析attribute_length,值为0x0000000A(十进制为10),说明属性的长度为10。后续line_number_table_length的值为0x0002表示line_number_table的个数为2。对应插件生成的结果是一致的。至此,第一个属性分析完成。


LocalVariableTable
开始分析第二个属性。根据attribute_info结构,第一个属性的name_index为0x000B,对应常量池中的LocalVariableTable。
LocalVariableTable属性是可选变长属性,位于Code属性的属性表中,调试器在执行方法的过程中可以用它来确定某个局部变量的值。在Code属性的属性表中,多个LineVariableTable属性可以按照任意顺序出现。Code属性attribute表中的每个局部变量,最多只能有一个LocalVariableTable属性。
LocalVariableTable的结构如下所示:
LocalVariableTable_attribute {
u2 attribute_name_index;
u4 attribute_length;
u2 local_variable_table_length;
{
u2 start_pc;
u2 length;
u2 name_index;
u2 descriptor_index;
u2 index;
} local_variable_table[local_variable_table_length];
}
LocalVariableTable结构各项的说明如下:
- attribute_name_index:其值必须是对常量池的一个有效索引。常量池表在该索引处的成员必须是CONSTANT_Utf8_info结构,用以表示字符串"LocalVariableTable"。
- attribute_length:表示当前属性的长度,不包括初始的6个字节(attribute_name_index和attribute_length)
- local_variable_table_length:表示local_variable_table[]数组中成员的数量。
- local_variable_table:数组中的每一项都以偏移量的形式给出了code数组中的某个范围。当局部变量处在这个范围内的时候,它是有值的。此项还会给出局部变量再当前帧的局部变量表(local variable array)中的索引。local_variable_table[]的每个成员都有如下5个项:
- start_pc和length:当给定的局部变量处在code数组的[start_pc,start_pc + length)范围内,也就是处在由偏移量大于等于start_pc且小于start_pc + length的字节码所构成的范围内时,该局部变量必定具备某个值。start_pc的值必须是对当前Code属性的code[]的一个有效索弓|, code[]在这个索引处必须是一条指令的操作码。start_pc+length要么是当前Code属性的code[]数组的有效索引,且code[]在该索引处必须是一条指令的操作码,要么是刚超过code[]数组末尾的首个索引值。
- name_index:值必须是对常量池表的一个有效索引。常量池在该索引处的成员必须是CONSTANT_Utf8_info结构,用来表示一个有效的非限定名,以指代这个局部变量。
- descriptor_index:值必须是对常量池表的一个有效索引。常量池在该索引处的成员必须是CONSTANT_Utf8_info结构,此结构是个用来表示源程序中局部变量类型的字段描述符。
- index:值为此局部变量在当前栈帧的局部变量表中的索引。如果在index索引处的局部变量是long或double类型,则占用index和index+1两个位置
接下来的local_variable_table_length值为0x0001表示local_variable_table的个数为1。
接着分析attribute_length,值为0x0000000C(十进制为10),说明属性的长度为10。后续local_variable_table_length的值为0x0001表示local_variable_table的个数为1。对应插件生成的结果是一致的。至此,第二个属性分析完成。


查看local_variable_table可以看出无参构造方法中的一个局部变量为this。
至此我们已经完整的分析完了第一个方法,后续方法也是一样的去分析。根据插件结构判断正确与否吧^_^
