blog简介
本博客是HNUcacheLab的B部分,在此记录以防丢失。
1. 以M32N32矩阵为例,并通过csim ref详细选项(-v)在缓存跟踪 trace.f文件中观察结果。
① 执行指令linux> make linux>./test-trans -M 32 -N 32生成trace.f0和trace.f1文件
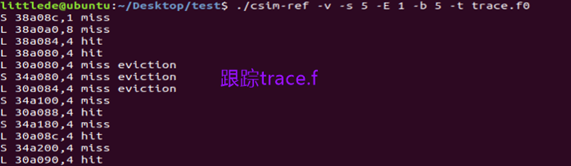
② 执行指令./csim-ref -v -s 5 -E 1 -b 5 -t trace.f0在缓存跟踪 trace.f文件中观察结果
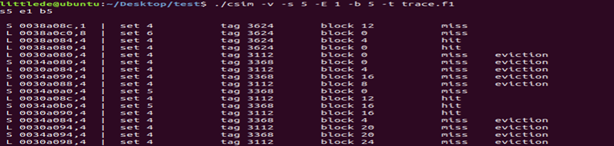
2.编写csim.c处理本条命令行同时输出显示标记位和组号
① 编写命令行输出标记位和组号的函数,将其加在命令解析函数的分支语句中
void dealCommand(int identifier,int address,int size,int setBits,int tagBit){
printf("\n %c %08x,%d",identifier,address,size);
printf(" | set %-8d tag %-8d",setBits,tagBit);
}
② 执行结果图:
3.以M4N4矩阵为例,并分析示例函数miss过多原因。
(1) 利用csim模拟器详细模式输出结果:执行指令 linux>./test-trans -M 4-N 4 ./csim -v -s 5 -E 1 -b 5 -t trace.f1>test.txt在缓存跟踪 trace.f1文件并且将结果导出到txt文件中:
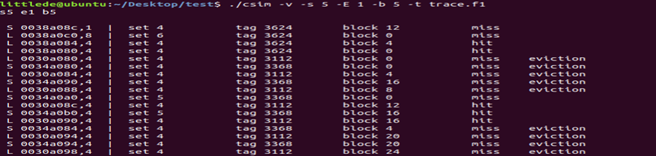
(2) 记录各命令行对应的数组A和B元素标号:
指令的地址拆分为tag,set,block可以定位到16个组,记录各命令行对应的数组A和B元素标号如下表:
L 0030b0e0,4 | set 7 tag 3116 A[0][0]
S 0034b0e0,4 | set 7 tag 3372 B[0][0]
L 0030b0e4,4 | set 7 tag 3116 A[0][1]
S 0034b0f0,4 | set 7 tag 3372 B[1][0]
L 0030b0e8,4 | set 7 tag 3116 A[0][2]
S 0034b100,4 | set 8 tag 3372 B[2][0]
L 0030b0ec,4 | set 7 tag 3116 A[0][3]
S 0034b110,4 | set 8 tag 3372 B[3][0]
L 0030b0f0,4 | set 7 tag 3116 A[1][0]
S 0034b0e4,4 | set 7 tag 3372 B[0][1]
L 0030b0f4,4 | set 7 tag 3116 A[1][1]
S 0034b0f4,4 | set 7 tag 3372 B[1][1]
L 0030b0f8,4 | set 7 tag 3116 A[1][2]
S 0034b104,4 | set 8 tag 3372 B[2][1]
L 0030b0fc,4 | set 7 tag 3116 A[1][3]
S 0034b114,4 | set 8 tag 3372 B[3][1]
L 0030b100,4 | set 8 tag 3116 A[2][0]
S 0034b0e8,4 | set 7 tag 3372 B[0][2]
L 0030b104,4 | set 8 tag 3116 A[2][1]
S 0034b0f8,4 | set 7 tag 3372 B[1][2]
L 0030b108,4 | set 8 tag 3116 A[2][2]
S 0034b108,4 | set 8 tag 3372 B[2][2]
L 0030b10c,4 | set 8 tag 3116 A[2][3]
S 0034b118,4 | set 8 tag 3372 B[3][2]
L 0030b110,4 | set 8 tag 3116 A[3][0]
S 0034b0ec,4 | set 7 tag 3372 B[0][3]
L 0030b114,4 | set 8 tag 3116 A[3][1]
S 0034b0fc,4 | set 7 tag 3372 B[1][3]
L 0030b118,4 | set 8 tag 3116 A[3][2]
S 0034b10c,4 | set 8 tag 3372 B[2][3]
L 0030b11c,4 | set 8 tag 3116 A[3][3]
S 0034b11c,4 | set 8 tag 3372 B[3][3]
(3)分析conflict miss产生:

综上,我认为miss产生的原因是:每组一行缓存8个int数据,而A和B访问时,会出现相邻使用同一块的情况,这个时候由于A和B的tag不匹配从而导致miss,这种冲突在对角线尤为突出。
4. 实验test- trans以M32N32矩阵为例,并分析示例函数mis过多原因。
① 跟踪结果输出在文件上,执行指令:./csim -v -s 5 -E 1 -b 5 -t trace.f1>test.txt,追踪trace.f1并且导出到txt:
② 结合 trace中一部分命令分析miss产生:

② A按行访问miss产生原因是初次访问冷不命中和被B占据一组后驱逐B导致的miss
③ B按列访问miss产生原因是初次访问冷不命中和被A占据一组后驱逐A导致的miss,以及B间隔一段后B的某个元素写入cache的某一行和其中已有的B的某一行冲突
5.分别按4和8分块编写 transpose_submit
① 4分块和8分块代码:
void transpose_submit1(int M, int N, int A[N][M], int B[M][N])
{
int i, j, k;
for (i = 0; i < N; i+=4) {
for (j = 0; j < M; j+=4) {
for(k=0;k<4;k++){
B[j][i+k] =A[i+k][j];
B[j+1][i+k] = A[i+k][j+1];
B[j+2][i+k] = A[i+k][j+2];
B[j+3][i+k] = A[i+k][j+3];
}
}
}
}
void transpose_submit2(int M, int N, int A[N][M], int B[M][N])
{
int i, j, k;
for (i = 0; i < N; i+=8) {
for (j = 0; j < M; j+=8) {
for(k=0;k<8;k++){
B[j][i+k] = A[i+k][j];
B[j+1][i+k] = A[i+k][j+1];
B[j+2][i+k] = A[i+k][j+2];
B[j+3][i+k] = A[i+k][j+3];
B[j+4][i+k] = A[i+k][j+4];
B[j+5][i+k] = A[i+k][j+5];
B[j+6][i+k] = A[i+k][j+6];
B[j+7][i+k] = A[i+k][j+7];
}} }
② 记录M32N32矩阵下miss数目,44分块miss487次,88分块miss343次数,如图:

③ 对角线优化:为了避免B加载进来之后A又需要重复加载的情况,设置8个变量一次性存储A的一行,这样一来就避免加载B[i][i]后又要加载A[i]这一行导致的驱逐。

void transpose_submit11(int M, int N, int A[N][M], int B[M][N])
{
int i, j, k;
for (i = 0; i < N; i+=4) {
for (j = 0; j < M; j+=4) {
for(k=0;k<4;k++)
{
int temp0= A[i+k][j];
int temp1= A[i+k][j+1];
int temp2= A[i+k][j+2];
int temp3= A[i+k][j+3];
B[j][i+k] = temp0;
B[j+1][i+k] = temp1;
B[j+2][i+k] = temp2;
B[j+3][i+k] = temp3;
}
}
}
}
void transpose_submit22(int M, int N, int A[N][M], int B[M][N]){
int i, j, k;
for (i = 0; i < N; i+=8) {
for (j = 0; j < M; j+=8) {
for(k=0;k<8;k++){
int temp0= A[i+k][j];
int temp1= A[i+k][j+1];
int temp2= A[i+k][j+2];
int temp3= A[i+k][j+3];
int temp4= A[i+k][j+4];
int temp5= A[i+k][j+5];
int temp6= A[i+k][j+6];
int temp7= A[i+k][j+7];
B[j][i+k] = temp0;
B[j+1][i+k] = temp1;
B[j+2][i+k] = temp2;
B[j+3][i+k] = temp3;
B[j+4][i+k] = temp4;
B[j+5][i+k] = temp5;
B[j+6][i+k] = temp6;
B[j+7][i+k] = temp7;
}}}}
④ 列表记录数组B第1个8*8块写操作的命中情况
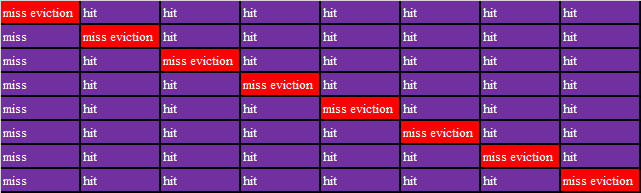
6.分析采用分块技术后miss改善原因。
①按4分块编写 transpose submit0代码
void transpose_submit11(int M, int N, int A[N][M], int B[M][N]){
int i, j, k;
for (i = 0; i < N; i+=4) {
for (j = 0; j < M; j+=4) {
for(k=0;k<4;k++)
{
int temp0= A[i+k][j];
int temp1= A[i+k][j+1];
int temp2= A[i+k][j+2];
int temp3= A[i+k][j+3];
B[j][i+k] = temp0;
B[j+1][i+k] = temp1;
B[j+2][i+k] = temp2;
B[j+3][i+k] = temp3;
}}}}
② 记录test- trans以M32N32矩阵下miss数目结果:44分块miss数目为439

① 以两个44为例分析hit增多原因,以下为矩阵AB的命中情况:

过程:访问A[0][0]miss,将A[0][0]到A[0][8]以一行加载到cache第8行,而写B[0][0]优惠访问cache第8行,此时会miss,继续转置A[0][1]A[0][3]由于已经将这些数据加载到临时变量对应寄存器中,所以直接hit。而对于B[1][0]B[3][0]由于第一次访问,所以miss。对于A[0][4]由于set8已经被B[0][]这一行占据所以发生驱逐,对于以后的A[0][5]A[0][7]则会连续命中。B[5][0]B[7][0] 由于第一次访问,所以miss。接下来的数据于此类似。得到如下结论:
① A矩阵的第一列将会不命中,其余部分命中 ②B矩阵的第一列和每个44规模的对角线将会不命中,其余部分命中
② 分块技术使hit增多的原因是增加了空间按局部性,具体的,分块处理44规模的数据,当B的一列访问完后已经缓存到cache中,这个时候因为分块,程序没有继续写入B接下来的列,而是处理上面处理过的行,这些行恰好已经缓存到cache中,所以可以命中。于此相反如果没有分块,程序就会继续处理B接下来的列,由于某些行比如说第2行和第10行都访问cache的第16组,他们的tag是不匹配的,所以会发生驱逐。
一.以M64N64矩阵为例,编写代码优化 trans.c中转置函数,采用8分块处理过程和记录miss结果。
(1)首先我的分块方法是直接88分块,然后进行6464规模的测试:
void transpose_submit22(int M, int N, int A[N][M], int B[M][N]){
int i, j, k;
for (i = 0; i < N; i+=8) {
for (j = 0; j < M; j+=8) {
for(k=0;k<8;k++){
int temp0= A[i+k][j]; B[j][i+k] = temp0;
int temp1= A[i+k][j+1]; B[j+1][i+k] = temp1;
int temp2= A[i+k][j+2]; B[j+2][i+k] = temp2;
int temp3= A[i+k][j+3]; B[j+3][i+k] = temp3;
int temp4= A[i+k][j+4]; B[j+4][i+k] = temp4;
int temp5= A[i+k][j+5]; B[j+5][i+k] = temp5;
int temp6= A[i+k][j+6]; B[j+6][i+k] = temp6;
int temp7= A[i+k][j+7]; B[j+7][i+k] = temp7;
}}}}

这样的优化结果几乎没有改变,究其原因,是因为数组规模扩充为了6464,cache块大小是32字节,组数为32,也就是说cache存满需要3232/4=256个整型,因此256/64=4行就会存满cache 说明每四行数组中的数据就会重复映射到已经映射过的组,8*8分块仍然出现y方向写cache时的驱逐,命中率为0.
(2)继续优化,考虑8块内部分为44的小块。如果直接内部44分块,无法最大化提高命中率,因为一次读取A[i][j]A[i][j]+7,但是使用的只有A[i][j]A[i][j]+3,后四个数据将会被在B访问时候被驱逐,为了避免后四个数据被“浪费”,可以在处理A的第一个分块时,将A的第二个4*4分块转置后暂存在B的第二块上,然后在处理A的第二个块的时候将B的第二块平移到B的第三块,从而避免冲突,实现如下:
for (i = 0; i < N; i+=8)//8*8分块
for (j = 0; j < M; j+=8){
for(k=i;k<i+4;k++){//转置第一个块,将A第二个块转置到B的第二个块
a0=A[k][j];a1=A[k][j+1];a2=A[k][j+2];a3=A[k][j+3];
a4=A[k][j+4];a5=A[k][j+5];a6=A[k][j+6];a7=A[k][j+7];
B[j][k]=a0;B[j+1][k]=a1;B[j+2][k]=a2;B[j+3][k]=a3;
B[j][k+4]=a4;B[j+1][k+4]=a5;B[j+2][k+4]=a6;B[j+3][k+4]=a7;}
for(k=j;k<j+4;k++){//将第三块转置到B的第二块,B的第二块平移到第三块
a0=A[i+4][k];a1=A[i+5][k];a2=A[i+6][k];a3=A[i+7][k];
a4=B[k][i+4];a5=B[k][i+5];a6=B[k][i+6];a7=B[k][i+7];
B[k][i+4]=a0;B[k][i+5]=a1;B[k][i+6]=a2;B[k][i+7]=a3;
B[k+4][i]=a4;B[k+4][i+1]=a5;B[k+4][i+2]=a6;B[k+4][i+3]=a7;
}
for(k=i+4;k<i+8;k++){//处理最后一块,将A的第四块转置到B的第四块
a0=A[k][j+4];a1=A[k][j+5];a2=A[k][j+6];a3=A[k][j+7];
B[j+4][k]=a0;B[j+5][k]=a1;B[j+6][k]=a2;B[j+7][k]=a3;
}}
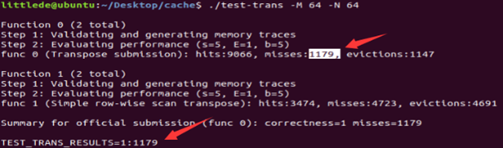
经过验证,不命中次数降到了1179次
二.追踪分析M64N64的组索引,分析8分块优化处理过程
考察如图所示的块,处理途中染色部分的88块转置,组索引将会每4行重复映射一次,我们的分块代码处理策略是:①将A的第一个44分块转置到B的第一个4*4分块,同时将A的第二块转置暂存到B的第二分块②将B的第三块转置到B的第二分块,并将B的第二分块转置到B的第三分块③将A的第四分块转置到B的第四分块。

① 处理紫色部分的第一个44分块,将其转置到B的第一个44分块。读取A的时候,访问cache第8行,第一列将会冷不命中;写B的时候将会将会访问cache的7~31列,此时只有第一次冷不命中,一行中其余的部分缓存在cache中,发生命中
② 将黄色部分转置到B的黄色部分,由于在处理第一个44分块的时候已经缓存在cache中,所以100%命中

① 将A的第三个44分块的转置到B的第二块,注意:在此之前已经用临时变量将B的第二块的一行存储。此时A的第一列将会发生冷不命中,并且B的第二个4*4分块也会发生驱逐,但是他们有一个共同点,就是除了第一列,数据都会缓存,因此该行后续的访问,将会命中
② 在处理完A第三块的某一列的同时,将B的第2块平移到B的第三块,这时访问cache会因为缓存第二块的第一行被占据,所以处理B的第三块的第一列都会发生驱逐不命中,其余部分则会命中

① 处理最后一个块,如紫色部分所示,访问A的时候,由于该行已经在前一次处理中缓存到了cache,所以将会命中;
② 写B的时候,由于在平移第二块到第三块的时候已经将同一行缓存,所以命中
结论:按照88分块内部44分块并且利用暂存的方式处理,只会在读取A和写B第一次取这一块的数据发生不命中,和在对角线上的元素发生不命中,不命中率接近12.5%
三.编写代码优化M61N67的 trans.c
对于61×67规模的矩阵,各个元素所在块的规律就不一样了。由于每一行的元素个数不为8的倍数,所以每一行不会占满整数个块。比如说第一行的最后面5个元素和第二最前面3个元素是在同一个块的。因此,61×67规模的矩阵分块要根据以往分块的经验,对数据进行统计分析。
① 设置分块规模从11~3232梯度为1共32组分块规模,运行后数据如左下,根据左下角的数据绘制折线图像:

② 数据分析:根据数据统计,可以看到在1~23区间内,miss次数随着分块规模增大而逐渐减小;随着分块规模N继续增大,miss次数开始上升。因此,最佳分块点是N=23,此时不命中数达到最小为1928
③ 结论:根据据数据统计,最佳分块点是N=23,其分块处理代码如下:
char test23_23_des[] = "test23_23";
void test23_23(int M, int N, int A[N][M], int B[M][N])
{
int i, j, k,r;
for(i=0;i<N;i+=23){
for(j=0;j<M;j+=23){
for(k=i;k<N&&k<i+23;k++){
for(r=j;r<M&&r<j+23;r++){
B[r][k]=A[k][r];
}
}
}
}
}
四.整理实验信息。
实验目标:
①PartA:目标是设计一个自制模拟器,读入trace指令,完成解析,并且根据cache的命中规则和LRU替换规则模拟cahce的缓存过程正确计算出hit,miss,eviction数据,最后和标准模拟器对比打分。
②PartB:目标是针对三个规模矩阵,规定cache的规模是<s=5,E=1,b=1>,优化转置代码trans.c,根据不同规模,合理利用分块技术,减少不命中率,探寻最佳的分块方法并实现之,对miss的大小都有一个限制。
实验资源:
① 实验环境:Ubuntu18.04.1(64位)
② 实验工具:valgrind
③ 其他软件:我用到了VsCode编辑器,Excel,Origin数据分析
④ 文档资源:cachelab.pdf手册,cachelab.ppt,Moodle上老师的录频
实验步骤:
(1) 搭建环境与分析脚本:完成valgrind 安装,熟悉csim-ref 的指令形式
(2)PartA:自制模拟器
① 理解cache的结构,编写cache容器,并且设计缓存的创建与释放函数
② 认识csim.ref使用指令,编写解析输入参数 get_Opt()函数
③ 理解LRU替换规则,编写Lru 计数值的函数代码
④ 理解 yi.trace 中各项(I,L,S,M)操作含义,利用fscanf ()函数读取 trace 文件并分支处理 LSM命令
⑤ 理解cache的读写修改访问规则,编写读写访问共三个cache缓存函数
⑥ 测试模拟器
(3)PartB
① 在缓存跟踪 trace.f文件中观察结果,理解cache的映像规则,做出思考。分析44矩阵的不命中情况
② 对3232规模矩阵进行44和88分块,对比结果,优化对角线,分析cache的映像和命中情况
③ 对6464规模进行88分块内部进行小分块,分析cache的映像和命中情况
④ 对61*67规模矩阵进行不同规模的分块处理,得到一个最佳的分块规模。
⑤ 测试分块代码。
五.实验结果

① Part A是./test-csim的结果,自制模拟器和标准模拟器将会运行8个trace文件,模拟器需解析tracec文件中的指令并且正确执行,得到相应8组hit,miss,eviction数据,这5组数据会和参考模拟器运行结果的数据对比,并且按此打分,如果数据相同则表示5组trace样例测试通过,意味着实验正确,截图中看到5组<hit,miss,eviction>和标准模拟器一致,也就表示设计正确了,(27points)。
② Part B是3组矩阵规模3232,6464,61*67的测试结果,测试中会根据trans.c中注册的函数 transpose_submit生成相应trace文件,模拟器会执行这个trace文件,生成相应的3组miss数据,第一组miss1<300得到8points,第二组miss2<1300得到8points,第三组miss3<2000得到10points,实验截图中看到三项分数分别是8,8,10也就说明PartB的设计正确了。
③ 最终得分是27+8+8+10=53,结论:实验设计正确。
六.实验总结。
① partA实验中我学到的最新奇的知识就是分块技术对cache的优化了,虽然说这是一种很常用的技术,但是在此之前我甚至想都没有想过可以通过代码的分块来优化程序。另外我还学到了如何用getopt()函数处理命令行和解析字符串,用fscanf()从文件读取数据。
② partB实验中我对cache的映射方式又有了更深一层的理解,学习到数据如何在cache中填充,以及不同规模下的映射方式会如何改变,如何根据这个变化来设计分块。在网上参考其他人的博客的时候,我见识到了更多的想法,用更多的方法来进行分块处理。
③ 本次实验中在环境搭建的时候因为Ubuntu源不对导致无法下载程序包,通过询问同学得到了解决。在一起讨论的过程中,我们相互帮助,同学们解决了我的很多疑惑,我也积极帮助了他人。很感谢老师和同学。

