树的基本概念:
- 树的定义:树是一种非线性结构
- 树的基本术语:
结点:结点不仅包含数据元素,而且包含指向子树的分支。
结点的度:结点拥有的子树个数或者分支的个数。
树的度:树中各结点度的最大值。
叶子结点:又叫做终端结点,指度为0的结点。
非终端结点:又叫做分支结点,指度不为0的结点。
孩子:结点的子树的根。 - 树的存储结构:
顺序结构:双亲存储结构——用一维数组就可以实现。
链式存储结构:
孩子存储
孩子兄弟存储结构: - 二叉树

1、 每个结点最多只有两棵子树,即二叉树中结点的度只能为0.1.2;
2、 子树有左右顺序之分,不能颠倒。
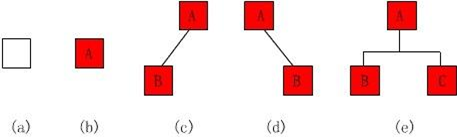
- 二叉树的形态:
1、 空二叉树
2、 只有根节点
3、 只有左子树
4、 只有右子树
5、 左右子树都有。
- 特殊的二叉树:
满二叉树:在一棵二叉树中,如果所有的分支结点都有左右孩子的结点,并且叶子结点都集中在二叉树的最下一层,则这样的二叉树称为满二叉树。
完全二叉树:如果对一棵深度为k、有n个结点的二叉树进行编号后,各结点的编号与深度为k的满二叉树中的相同位置上的结点的编号均相同,那么这棵二叉树就是一棵完全二叉树。

-
二叉树的性质:
1、非空二叉树上叶子结点数等于双分支结点数加1.(由于二叉树除了根结点之外,每个结点都有唯一的一个分支指向它,因此二叉树中有总分支树=总结点数-1)
拓展:在一棵度为m的树中,度为1的结点数为n1,度为2的结点数为n2,…,度为m的结点数位nm,则叶子结点数n0=1+n2+2*n3+…+(m-1)*nm,
推导过程:
总结点数=n0+n1+n2+n3+…+nm;
总分支数=1n1+2n2+3n3+…+mnm;(度为m的结点引出m条分支)
总分支数=总结点数-1; -
例:在一棵度数为4的树T中,若有20个度为4的结点,10个度为3的结点,1个度为2的结点,10个度为1的结点,则树T的叶结点的个数是(B)
A、41
B、82
C、113
D、122
解析:
直接引用上述叶结点的公式n0=1+n2+2n3+(4-1)n4=1+1+210+320=82
不仅仅适用于二叉树。
- 例:在一棵三叉树中,度为3的结点数位2个,度为2的结点数为1个,度为1的结点数为2个,则度为0的结点(叶子)数为(C)
A、4
B、5
C、6
D、7
2、二叉树的第i层上最多有2^(i-1)(i≥1)个结点。

3、深度为k的二叉树最多有2^k-1
个节点.(满二叉树中前k层的结点个数为2^k-1。
4、若i为某个结点a的编号,则:
如果i≠1,则a的双亲结点的编号为 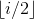
如果2 i≤n,则a的左孩子的编号为2i;如果2i>n,则a无左孩子。
如果2i+1 i≤n,则a的右孩子编号为2i+1;如果2i+1>n,则a无右孩子。
例:如图,n=5,结点B编号为2,22=4<5,则编号为4的结点D为结点B的左孩子;22+1=5,则编号为5的结点E。
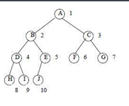
5、给定n个结点,能构成h(n)种不同的二叉树,h(n)=C(n,2*n)/(n+1) .
6、具有n个结点的完全二叉树的高度(或深度)为[logn]+1。
- 二叉树的存储结构
链式存储:
结构类型定义:
typedef struct BTNode
{
char data;//这里默认结点data域为char型
struct BTNode *lchild;//左指针域
struct BTNode *rchild;//右指针域
} BTNode;
-二叉树的遍历(遍历就是全部走遍)。

先序遍历:
遍历过程:根->左->右
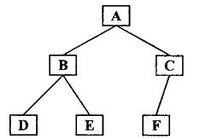
根:A
左:有BDE三个结点
{BDE:
根:B
左:D
右:E
}
右:有CF两个结点
{CF:
根:C
左:空
右:F
}
故先序遍历:ABDECF
设二叉树中元素数目为n,先序遍历算法的空间复杂性均为O (n),时间复杂性为(n)。
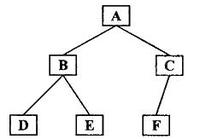
中序遍历(LDR)
遍历过程:左->根->右
左:BDE
{
左:D
根:B
右:E
}
根:A
右:CF
{
左:F
根:C
右:空
}
中序遍历:DBEAFC
设二叉树中元素数目为n,中序遍历算法的空间复杂性均为O (n),时间复杂性为(n)。
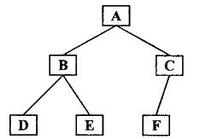
后序遍历:
遍历过程:左->右->根
左:BDE
{
左:D
右:E
根:B
}
右:CF
{
左:F
右:空
根:C
}
根:A
后序遍历:DEBFCA
例:表达式(a-(b+c))*(d/e)存储在图所示的一棵以二叉链表为存储结构的二叉树中(二叉树结点的data域为字符型),编写程序求出改表达式的值。
分析:
可以把二叉树分为三个部分,左子树(a-(b+c))为表达式A,右子树(d/e)为B,先求左子树的值,再求右子树的值,最后两式结果相乘就是整个表达式的数值。
可以用后序遍历来完成:
int comp(BTNode *P)
{
int A,B;
if (P!=NULL)
{
if (P->lchild!=NULL&&P->rchild!=NULL)
{
A=comp(P->lchild);
B=comp(P->rchild);
return op(A,B,P->data);
}
else
return P->data-'0';
}
else return 0;
}
说明:函数int op(int A,int B,char C)返回的是以C为运算符,以A,B为操作数的算式的数值,例如C为“+“,则返回为A+B的值。
例题:一棵二叉树的先序遍历序列为A,B,C,D,E,F,中序遍历序列为C,B,A,E,D,F,则后序遍历为(A)
A、C,B,E,F,D,A
B、F,E,D,C,B,A
C、C,B,E,D,F,A
D、不确定
解析:先序:根左右,根A;中序:左根右,左{CB}右{EDF} 后序:左右根,左{CB},右{EFD},根A
- 线索二叉树:二叉树被线索化后近似于一个线性结构,分支结构的遍历操作就转化为了近似于线性结构的遍历操作,通过线索的辅助使得寻找当前结点前驱或者后继的平均效率大大提高。
指向前驱或后继的指针称为线索。
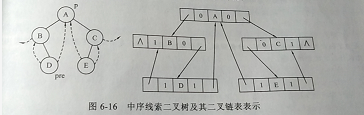
1、 中序线索二叉树

ltag、rtag为标识域。
如果Itag=0,则表示lchild为指针,指向结点的左孩子;
如果Itag=1,则表示lchild为线索,指向结点的直接前驱。
如果rtag=0,则表示rchild为指针,指向结点的右孩子;
如果rtag=1,则表示rchild为线索,指向结点的直接后继
线索二叉树的结点定义:
typedef struct TBTNode{
char data;
int ltag,rtag;
struct TBTNode *lchild;
struct TBTNode *rchild;
}TBTNode;
中序线索化的规则:
左线索指针指向当前结点在中序遍历序列中的前驱结点,右线索指针指向后继结点。因此我们需要一个指针p指向当前正在访问的结点,pre指向p的前驱结点,p的左线索指针如果存在的话直接指向pre(也就是前驱结点),pre的右线索如果存在则指向p(也就是直接后继)。
优势
(1)利用线索二叉树进行中序遍历时,不必采用堆栈处理,速度较一般二叉树的遍历速度快,且节约存储空间。
(2)任意一个结点都能直接找到它的前驱和后继结点。
不足
(1)结点的插入和删除麻烦,且速度也较慢。
(2)线索子树不能共用。