一、实验内容
对输入文件中数据进行排序。输入文件中的每行内容均为一个数字,即一个数据。要求在输出中每行有两个间隔的数字,其中,第一个代表原始数据在原始数据集中的位次,第二个代表原始数据。
输入:
1)file1:
2
32
654
32
15
756
65223
2)file2:
5956
22
650
92
3)file3:
26
54
6
输出:
1 2
2 6
3 15
4 22
5 26
6 32
7 32
8 54
9 92
10 650
11 654
12 756
13 5956
14 65223
二、实验过程
1、在HDFS下创建一个名称为/sort的目录
./bin/hdfs dfs -mkdir /sort

2、编辑filea.txt、fileb.txt、filec.txt文本文件
gedit filea.txt
gedit fileb.txt
gedit filec.txt

3、将filea.txt、fileb.txt、filec.txt文本文件上传到hdfs的/sort目录下
./bin/hdfs dfs -put ./filea.txt /sort
./bin/hdfs dfs -put ./fileb.txt /sort
./bin/hdfs dfs -put ./filec.txt /sort

4、显示hdfs的/sort目录下内容
./bin/hdfs dfs -ls /sort

数据排序"是许多实际任务执行时要完成的第一项工作,比如学生成绩评比、数据建立索引等。这个实例和数据去重类似,都是先对原始数据进行初步处理,为进一步的数据操作打好基础。对输入文件中数据进行排序。输入文件中的每行内容均为一个数字,即一个数据。要求在输出中每行有两个间隔的数字,其中,第一个代表原始数据在原始数据集中的位次,第二个代表原始数据。
5、编程代码如下
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class SortWork extends Configured implements Tool {
public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = getConf();
Job job = new Job(conf, "sort");
job.setJarByClass(getClass());
job.setMapperClass(SortMap.class);
job.setReducerClass(SortReducer.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("hdfs://localhost:9000//sort"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://localhost:9000///outvalue/sort"));
job.submit();
return job.isSuccessful() ? 0 : 1;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new Configuration(), new SortWork(), null);
}
}
class SortMap extends Mapper<LongWritable, Text, IntWritable, IntWritable> {
private IntWritable one = new IntWritable(1);
private IntWritable data = new IntWritable();
protected void map(LongWritable key, Text value, Context context)
throws java.io.IOException, InterruptedException {
String line = value.toString().trim();
data.set(Integer.parseInt(line));
context.write(data, one);
}
}
class SortReducer extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable> {
private int sum = 0;
protected void reduce(IntWritable key, java.lang.Iterable<IntWritable> values,
Context context) throws java.io.IOException, InterruptedException {
for (IntWritable in : values) {
sum += in.get();
}
context.write(new IntWritable(sum), key);
}
}



6、运行后,在localhost:50070下搜索“/”可见出现了outvalue文件夹
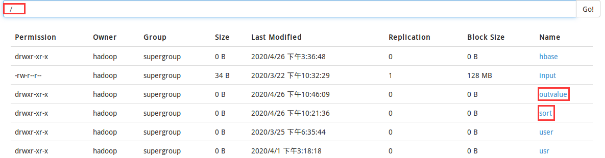
7、打开/outvalue/sort目录,如下图

8、cat目录查看/outvalue/sort/part-r-00000文件内容如下(可见由小到大排序后的结果)
./bin/hdfs dfs -cat /outvalue/sort/part-r-00000

做到这里,本次实验基本完成了,加油!
