目录
Centos7下Hadoop完全分布式集群Kafka安装
- 电脑系统:macOS 10.15.4
- 虚拟机软件:Parallels Desktop14
- Hadoop各节点节点操作系统:CentOS 7
- JDK版本:jdk1.8.0_162
- Kafka版本:kafka_2.11-2.1.1
Kafka的下载源地址:
第一步:安装软件
(1)上传文件
将本机的安装包上传到虚拟机node1,上传方式:
scp 本机的文件绝对路径 [email protected]:/opt/Hadoop
(2)解压文件
上传成功之后需要对文件赋予权限
chmod u+x kafka_2.11-2.1.1.tar.gz
解压文件:
tar -zxvf kafka_2.11-2.1.1.tar.gz
创建软链接:
ln -s kafka_2.11-2.1.1.tar.gz kafka
第二步:配置环境变量
声明:kafka不同的版本对应的配置文件可能不同,命令也不一样,所以在参考之前需要核对好自己的版本号,以免产生误会。
vim ~/.bashrc
然后添加以下内容,注意三台虚拟机都需要配置环境变量
export KAFKA_HOME=/opt/Hadoop/kafka
export PATH=${KAFKA_HOME}/bin:$PATH
最后使之生效

source ~/.bashrc
第三步:修改配置文件
kafka中修改配置文件主要是/opt/Hadoop/kafka/config中的server.properties
第一个地方:
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
在node1中修改编号为1,node2中修改编号为2,node3中修改编号为3,以此类推
第二个地方:
# The address the socket server listens on. It will get the value returned from
# java.net.InetAddress.getCanonicalHostName() if not configured.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://node1:9092
port=9092
这里根据自己的所在的主机名修改
第三个地方:
# Hostname and port the broker will advertise to producers and consumers. If not set,
# it uses the value for "listeners" if configured. Otherwise, it will use the value
# returned from java.net.InetAddress.getCanonicalHostName().
advertised.listeners=PLAINTEXT://node1:9092
这里根据自己的所在的主机名修改
第四个地方:
# A comma separated list of directories under which to store log files
log.dirs=/opt/Hadoop/kafka/kafka-logs
这里需要在/opt/Hadoop/kafka/目录下创建一个kafka-logs文件夹
mkdir kafka-logs
第五个地方:
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=node1:2181,node2:2181,node3:2181
zookeeper这里需要按照这里的格式写
第四步:分发配置文件
将node1的kafka_2.11-2.1.1和kafka_2.11-2.1.1.tar.gz文件分发到node2和node3上:
scp -r kafka_2.11-2.1.1 kafka_2.11-2.1.1.tar.gz caizhengjie@node2:/opt/Hadoop/
scp -r kafka_2.11-2.1.1 kafka_2.11-2.1.1.tar.gz caizhengjie@node3:/opt/Hadoop/
分别在node2和node3上创建软连接
ln -s kafka_2.11-2.1.1.tar.gz kafka
上传完之后要对node2,node3进行配置文件的修改,参考第三步
第五步:启动与检测
kafka的启动方式,需要进入到bin的上一级目录,也就是/opt/Hadoop/kafka
bin/kafka-server-start.sh -daemon config/server.properties
通过输入jps来查看进程

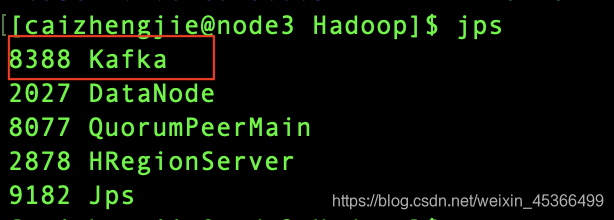
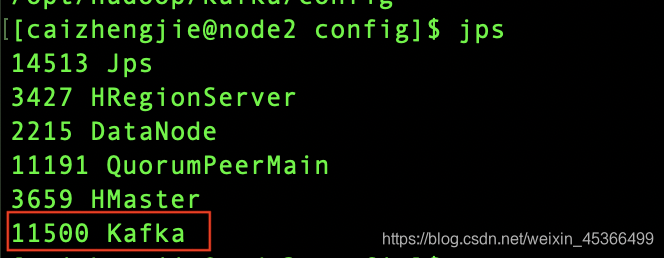
出现kafka则表示安装成功
第六步:对Kafka进行消息测试
在测试之前,需要配置一下producer.properties文件,意思是配置生产者。
我在每一台机的/opt/Hadoop/kafka/config/producer.properties文件中修改
# list of brokers used for bootstrapping knowledge about the rest of the cluster
# format: host1:port1,host2:port2 ...
bootstrap.servers=node1:9092,node2:9092,node3:9092
(1)启动服务
首先要启动zookeeper,再启动kafka,三台要同时启动
启动zookeeper:
zkServer.sh start
启动kafka
在前台启动kafka,注意查看打印在桌面的日志,有无报错信息
bin/kafka-server-start.sh config/server.properties
如果没有报错信息,启动正常,那么就可以在后台启动了
bin/kafka-server-start.sh -daemon config/server.properties
(2)创建topic
创建一个分区和一个副本的“test”的topic
bin/kafka-topics.sh --create --zookeeper node1:2181,node2:2181,node3:2181 --replication-factor 1 --partitions 1 --topic test
这里有的朋友会问到,topic在哪里可以看到?那么我这里解释一下
首先进入到/opt/Hadoop/zookeeper/bin目录下
cd /opt/Hadoop/zookeeper/bin
然后执行zkCli.sh服务,会看到下图的页面
然后输入ls /,则下面就看到brokers,输入ls /brokers,则会看到
[zk: localhost:2181(CONNECTED) 2] ls /brokers
[ids, topics, seqid]
那么刚才所创建的test就在topics下,再次输入ls /brokers/topics,就会看到test
[zk: localhost:2181(CONNECTED) 3] ls /brokers/topics
[protest, test, __consumer_offsets]
输入quit则退出
还有一种方法,可以通过下面的命令查看
bin/kafka-topics.sh --list --zookeeper localhost:2181
[caizhengjie@node1 kafka]$ bin/kafka-topics.sh --list --zookeeper node1:2181
__consumer_offsets
protest
test
(3)生产者发送消息
Kafka带有一个命令行客户端,它将从文件或标准输入中获取输入,并将其作为消息发送到Kafka集群。默认情况下,每行将作为单独的消息发送。运行生产者,然后在控制台中键入一些消息以发送到服务器。
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
[caizhengjie@node1 kafka]$ bin/kafka-console-producer.sh --broker-list node1:9092,node2:9092,node3:9092, --topic test
>java
>python
>php
>hadoop
>linux
>
(4)消费者接收消息
Kafka还有一个命令行使用者,它将消息转储到标准输出。
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
在node2上操作:
bin/kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --from-beginning --topic test
java
python
php
hadoop
linux
参考文章:
官网文档
以上内容仅供参考学习,如有侵权请联系我删除!
如果这篇文章对您有帮助,左下角的大拇指就是对博主最大的鼓励。
您的鼓励就是博主最大的动力!