报错
’utf-8’ codec can’t decode byte 0xb6 in position 2
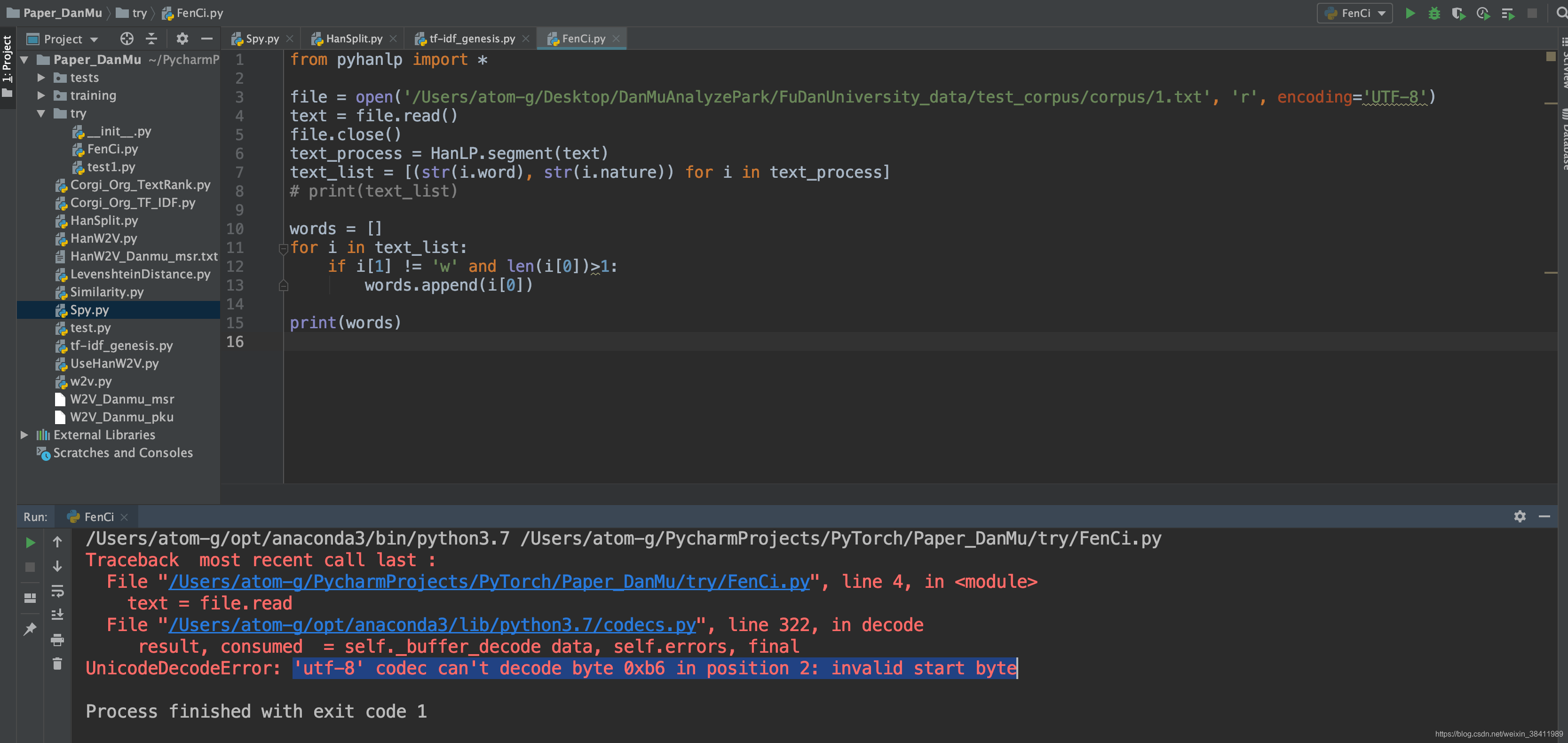
解决办法
1 ✅
file = open('/Users/atom-g/Desktop/DanMuAnalyzePark/FuDanUniversity_data/test_corpus/corpus/1.txt', 'r', encoding='gbk')
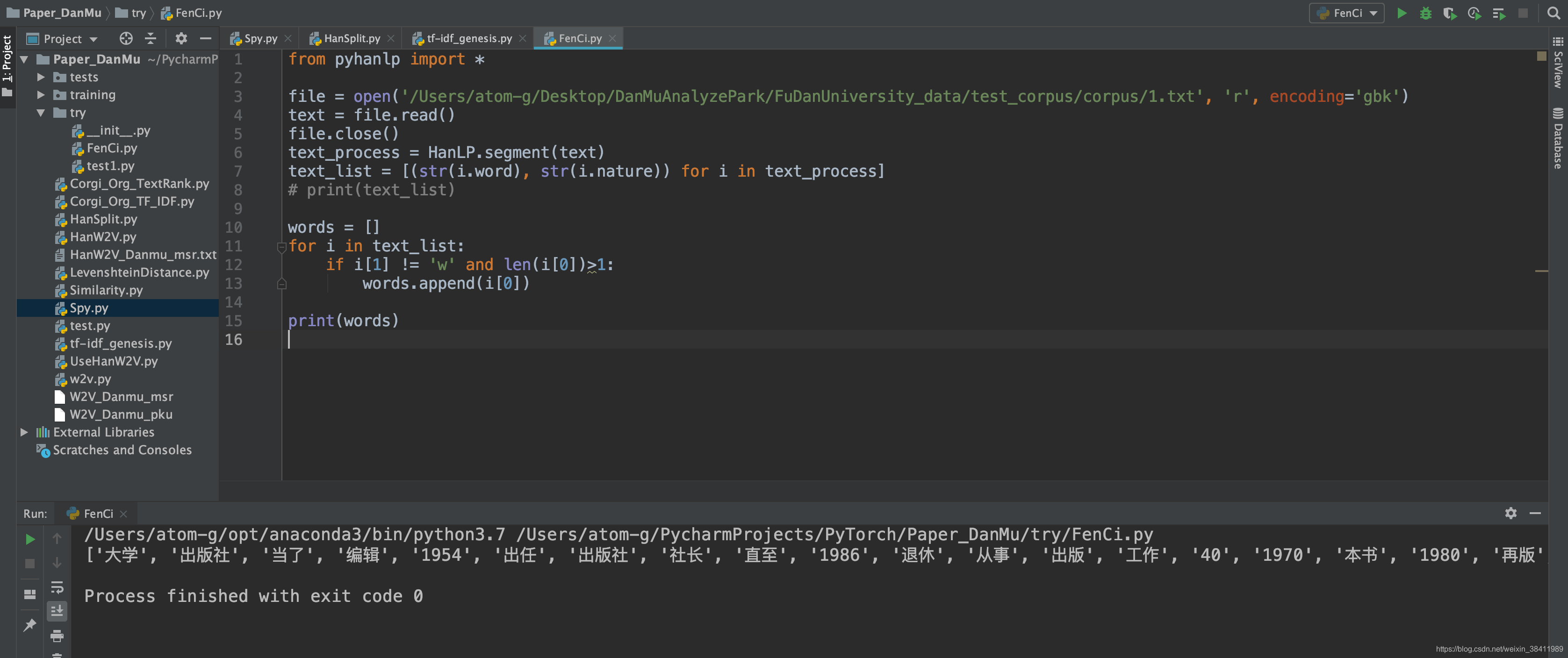
2-代码美观一点 ✅
from pyhanlp import *
def readtxt(path):
with open(path, 'r', encoding='gbk') as fr:
content = fr.read()
return content
text = readtxt('/Users/atom-g/Desktop/DanMuAnalyzePark/FuDanUniversity_data/test_corpus/corpus/1.txt')
text_process = HanLP.segment(text)
text_list = [(str(i.word), str(i.nature)) for i in text_process]
# print(text_list)
words = []
for i in text_list:
if i[1] != 'w' and len(i[0])>1:
words.append(i[0])
print(words)
