前言
问题:将百分制的成绩变为五分制的成绩
if(score < 60) grade = 1;
else if(score < 70) grade = 2;
else if(socre < 80) grade = 3;
else if(socre < 90) grade = 4;
else grade = 5;
我们将其画为一颗判定树

如果我们学生的成绩绝大多数都是90,80,但是60分的很少,这颗判定树的效率就很低了。
如果考虑学生成绩的分布概率

按照上述的查找方法,查找效率为:
0.05 * 1 + 0.15 * 2 + 0.40 * 3 + 0.30 * 4 + 0.10 * 4 = 3.15
修改判定树
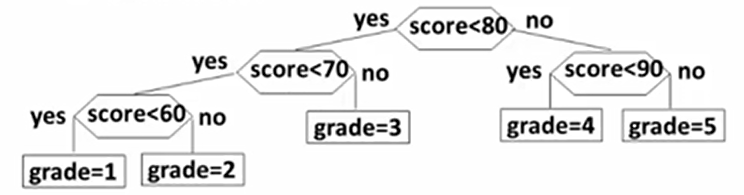
if(score < 80)
{
if(score < 70)
{
if(score < 60) grade = 1;
else grade = 2;
}
else = 3;
}
else
{
if(score < 90) grade = 4;
else grade = 5;
}
此时的效率就是
0.05 * 3 + 0.15 *3 + 0.4 * 2 + 0.3 * 2 + 0.1 *2 = 2.2
显然比之前的判定树要好
根据这个,给了我们一个启示
如何根据结点不同的查找频率构造更有效的搜索树?
这个就是哈夫曼树要解决的问题
哈夫曼树
带权路径长度(WPL):
设有n个叶子节点,每个叶子节点带有权值 ,从根节点到每个叶节点的长度为 ,则每个叶子节点的带权路径长度之和就是
什么是哈夫曼树
哈夫曼树(Huffman Tree),又称最优二叉树,是一类带权路径长度最短的树。假设有n个权值{w1,w2,…,wn},如果构造一棵有n个叶子节点的二叉树,而这n个叶子节点的权值是{w1,w2,…,wn},则所构造出的带权路径长度最小的二叉树就被称为哈夫曼树。
举例
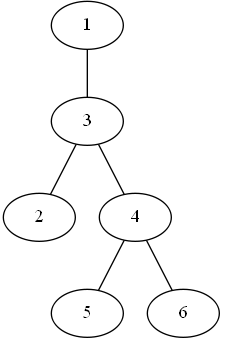
如图二叉树,
WPL = (5+6)* 4 + (2+4)* 3 + 3 * 2 + 1 * 1 = 69
哈夫曼树的特点
哈夫曼树的特点:
- 没有度为1的结点 ;
- n个叶子节点数的哈夫曼树,节点总数为2n-1
- 哈夫曼树的任意非叶节点的左右子树交换后仍是哈夫曼树;
哈夫曼树构建
思路:
- 将权值从小打到进行排序
- 每次把权值最小的两棵二叉树合并,这颗二叉树的权值就是并在一起两棵二叉树权值的和
比如 [1,2,3,4,5]

先将最小的两个子树合并,合并后的权值为两子树权值之和
a = 1 + 2 = 3
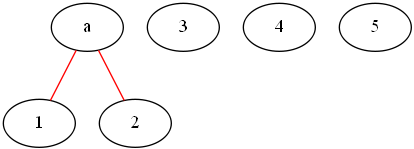
再进行排序,将最小两数合并
b = a + 3 = 6
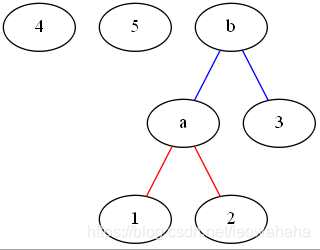
重复12操作
c = 4 + 5 > b

最后再进行合并
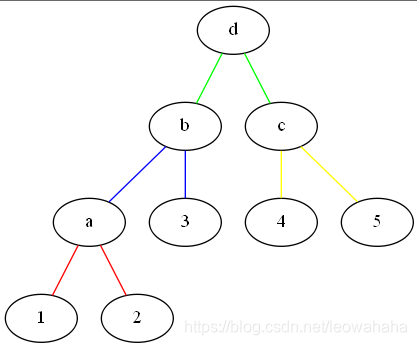
此时WPL =
(1+2)*3 + 3 * 2 + (4+5) * 2 = 33
代码实现哈夫曼树的构造
这里我运用了我另一篇博客数据结构——堆的基本操作(堆的建立、插入、删除等)详解的知识,这里我运用了最小堆的相关操作,某些函数有所不同,我就不列出了
struct HuffmanTree {
int Weight;
HuffmanTree* Left, * Right;
};
HuffmanTree* CreateHuffmanTree(HNode* H) { //此处的HNode为最小堆
int i;
HuffmanTree* T;
H = CreateHeap(H->Size); //先将H-Data按照权值调整成最小堆
for (i = 1;i < H->Size;i++) {
T = new HuffmanTree;
T->Left = DeleteMin(H); //从最小堆中删除一个节点,作为新T的左子结点
T->Right = DeleteMin(H); //从最小堆中删除一个节点,作为新T的右子结点
T->Weight = T->Left->Weight + T->Right->Weight; //计算新权值
H = Insert(H, T); //*将新T插入最小堆*/
}
T = DeleteMin(H);
return T;
}
Ps:本人初学数据结构,若有出现错误,欢迎指出