问题说明:
我需要在python中扩展数据框中的每一行并拼接一个数据框
Example:
我现在有两个表(表A,表B)如下:
(表A:学生信息表)
| 姓名 | 学号 |
|---|---|
| A | 1 |
| B | 2 |
| C | 3 |
| D | 4 |
(表B:课程信息表)
| 课程名称 | 是否需要考试 |
|---|---|
| 语文 | 需要 |
| 数学 | 需要 |
| 外语 | 需要 |
| 手工 | 不需要 |
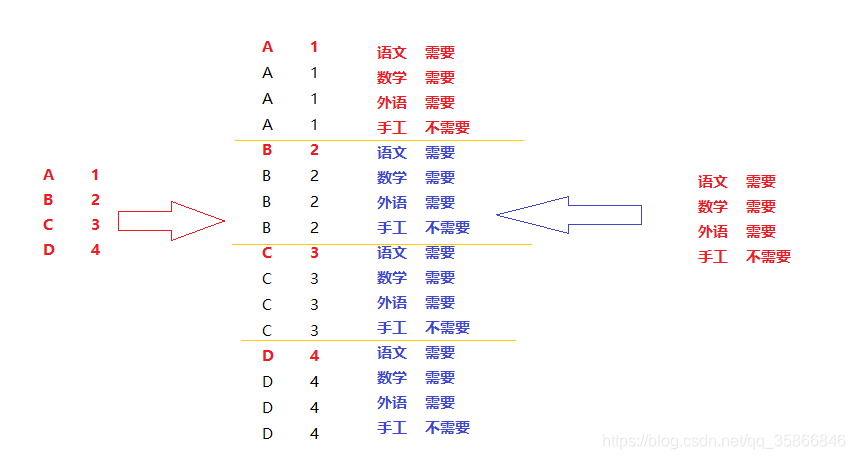
对于一个班的学生来说,哪个课程需不需要考试肯定是对所有同学来说的
所以最后我想把表A的每条信息都复制成4条,把表B整个复制四份,直接拼在A的右边
如下图所示,最终输出中间部分(这就是SQL中常说的笛卡儿积运算):
笛卡儿积形象图
Mysql的笛卡尔积实现方案
mysql> select * from student_info,course_info
-> order by student_name,course;
+--------------+-------------+--------+--------+
| student_name | student_num | course | exam |
+--------------+-------------+--------+--------+
| A | 1 | 外语 | 需要 |
| A | 1 | 手工 | 不需要 |
| A | 1 | 数学 | 需要 |
| A | 1 | 语文 | 需要 |
| B | 2 | 外语 | 需要 |
| B | 2 | 手工 | 不需要 |
| B | 2 | 数学 | 需要 |
| B | 2 | 语文 | 需要 |
| C | 3 | 外语 | 需要 |
| C | 3 | 手工 | 不需要 |
| C | 3 | 数学 | 需要 |
| C | 3 | 语文 | 需要 |
| D | 4 | 外语 | 需要 |
| D | 4 | 手工 | 不需要 |
| D | 4 | 数学 | 需要 |
| D | 4 | 语文 | 需要 |
+--------------+-------------+--------+--------+
python 的笛卡儿积实现(一)
import pandas as pd
import numpy as np
#生成测试数据
a = pd.DataFrame({'name':list('ABCD'),'student_num':[i+1 for i in range(4)]})
b = pd.DataFrame({'course':['语文','数学','外语','手工'],'exam':['yes','yes','yes','no']})
#创建一个虚拟密钥并merge合并创建笛卡儿积然后在删除创建的密钥
a.assign(key=1).merge(b.assign(key=1), on='key').drop('key',axis=1)
分步拆解变形:
import pandas as pd
import numpy as np
a = pd.DataFrame({'name':list('ABCD'),'student_num':[i+1 for i in range(4)]})
b = pd.DataFrame({'course':['语文','数学','外语','手工'],'exam':['yes','yes','yes','no']})
#第一步:分别新增相同辅助列
a['key']=1
b['key']=1
#第二步:merge拼接
result=pd.merge(a,b)
#第三步:删除辅助列
result.drop('key',axis=1,inplace=True)
python 的笛卡儿积实现(二)
import pandas as pd
import numpy as np
a = pd.DataFrame({'name':list('ABCD'),'student_num':[i+1 for i in range(4)]})
b = pd.DataFrame({'course':['语文','数学','外语','手工'],'exam':['yes','yes','yes','no']})
#按行复制扩展 n倍
def zdy_copy1(data,n):
result=pd.DataFrame()
for i in range(len(data)):
s=data.loc[i]
t=pd.DataFrame(s).T
result=result.append([t]*n) #每行复制b长度倍
result.reset_index(drop=True,inplace=True)
return result
#整体复制扩展 n倍
def zdy_copy2(data,n):
result=pd.DataFrame()
for i in range(len(a)):
result=pd.concat([result,b])
result.reset_index(drop=True,inplace=True)
return result
rr1=zdy_copy1(a,len(b))
rr2=zdy_copy2(b,len(a))
pd.concat([rr1,rr2],axis=1)