1.需要的工具有:谷歌浏览器,一个解析网站(http://jx.618g.com/)
开始:我们在某某视频找到资源

然后,我们需要它的链接
接下来打开解析网站


点击HTTP解析把链接输入记得不要把前面的删除,我们就可以直接观看了,但是,我们是要下载的话,就需要pa了

首先我们要看看视频的信息,按f12打开开发者选项
然后CTRL+r
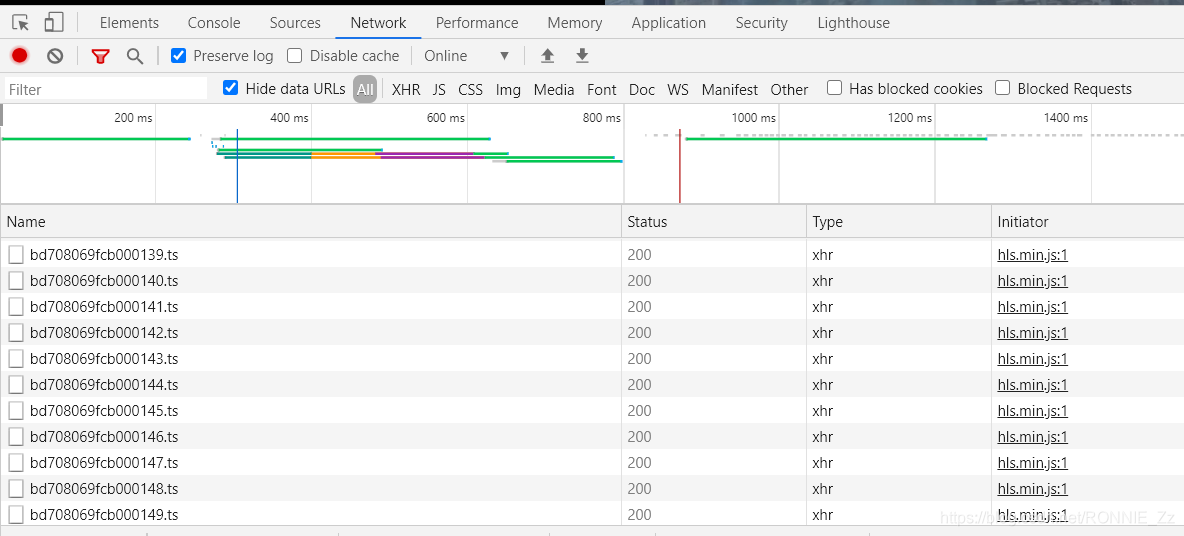
这下面每一个.ts的文件就是视频了,但是是一小段一小段的,可以直接点击下载,但是很多哦,链接就能下载
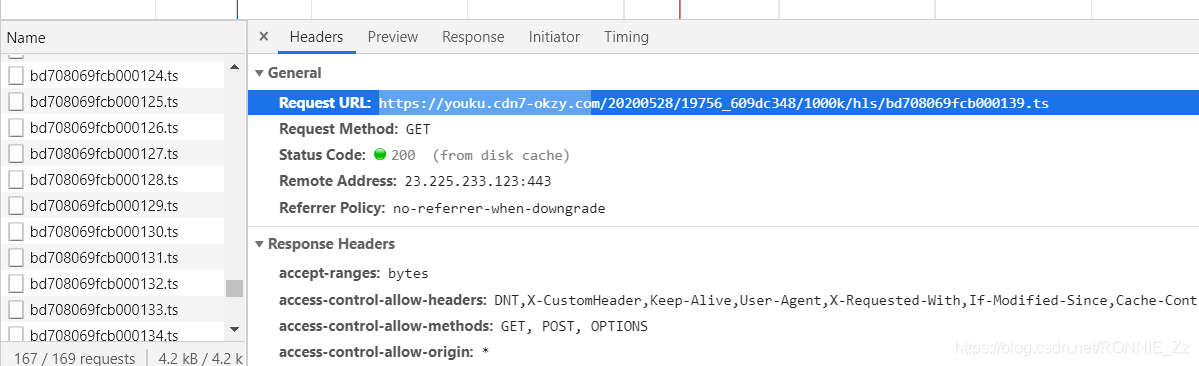
然后生活不易,我们用python,原理就不讲了
代码如下,大家看着改,下下来以后,他是很多小视频,然后我们需要用cmd转移到该文件下,然后输入以下指令
copy /b * ts movie.mp4
回车运行就欧克了
python
import requests
from fake_useragent import UserAgent
import os
from multiprocessing import Pool
def download():
headers = {
'User-Agent':UserAgent().random
}
url = '地址复制在这%04d.ts' % i#我们注意到一部剧下载前面的链接地址是一样的,通过变换地址我们下载它
response = requests.get(url.headers=headers)
os.makedirs('video',exist_ok=True)
if response.status_code != 404:
with open('./video/{}'.format(url[-7:]), 'wb')as f:
f.write(response.content)
if i % 10 == 0:
print('\r进度:‘ + str((i / 1850) * 100)[:4] +'%', end='')
def main():
po = Pool(10)#这里的10换的越大越快,但是要考虑电脑性能和网速
for i in range(1, 1850):#这里的数字自己调节
po.apply_async(download, args=(i,))
po.close()
print('开始下载....')
po.join()
print('下载完成')
if __name__== '__main__':
main()
这就是python代码了,下载好后会全部保留在你建的项目文件夹里面