一序
本文属于极客时间-算法训练营 学习笔记。
二 数组
Java:new int[100];
-
可以直接进行初始化
-
高级语言,对于数组中的元素类型没有限制--->泛型
计算机底层:内存空间开辟一块连续的地址。
-
每一个地址直接可以通过内存管理器进行访问
-
无论访问哪个元素,时间复杂度是一样的,常数O(1)的
特点:可以随机的访问。
数组的问题,关键在于要增加、删除数组元素的时候,会进行相应的操作,
如下图: 要在index=3的位置插入“D”,则需要移动“E”“F”“G”,此时源码中会涉及非常多的arraycopy操作,时间复杂度由常数级的复杂度--->O(n),(平均移动移动一半的数据)删除同理,将最后的元素设置为空,调用垃圾回收size-1。
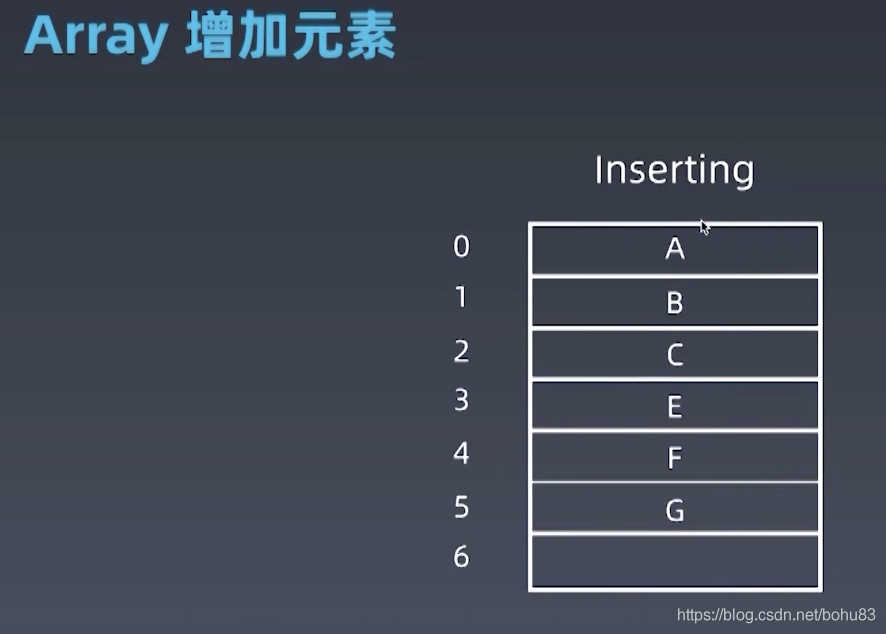
Java的arrayList源码就是这样实现的。
//追加到末尾
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
//指定位置插入
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
//复制
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
//插入
elementData[index] = element;
size++;
}注意: arraycopy(Object src, int srcPos, Object dest, int destPos, int length);
是吧源目标位置拷贝到目标位置,
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}关于扩容ensureCapacityInternal:
首先对旧容量oldCapacity进行1.5倍的扩容,之后如果newCapacity仍然小于最小要求容量minCapacity,就把minCapacity的值给到newCapacity。如果newCapacity的值大于最大要求容量,则会走hugeCapacity()方法,进行一个最终扩容后的大小确认,最后调用Arrays.copyof()方法,在原数组的基础上进行复制,容量变为newCapacity的大小。
由此看来,对于数组扩容涉及到很多array.copy.效率很低。
三 链表
为了弥补数组的插入、删除带来的复杂度上升的缺点

- 一般用class来定义,每个元素有Value、Next,next指向下一个元素。
- 只有一个next指针叫单链表,
有时候往前一个指叫它的先前指针(previous),是双向链表 - 头指针用head表示,尾指针用tail表示,
- 最后一个元素next指向空。
- 如果tail指针可以指向head指针,就叫循环链表。
java的源码:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
/**
* Constructs an empty list.
*/
public LinkedList() {
}
。。。
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
它是双向链表。first 、last分别起到了双向指针的作用。
增加节点

删除节点

- 增加或删除节点的话,没有引起整个链表的群移操作,也不需要复制元素,挪动元素到新的位置,所以它移动的效率和修改的操作效率非常高,复杂度为O(1)
这个结构导致了访问链表中的任何一个位置,(除了头尾节点),复杂度为O(n)
链表操作时间复杂度: prepend ---> O(1) append ---> O(1) lookup ---> O(n) insert ---> O(1) delete ---> O(1)
Array操作复杂度:
prepend ---> O(1)
append ---> O(1)
lookup ---> O(1)
insert ---> O(n)
delete ---> O(n)四 跳表
4.1问题由来:

针对链表有序的情况下,O(n)的时间复杂度已经太慢了。

4.2优化的思路:
升维,将一维结构变为二维结构,不仅仅增加一个头指针和尾指针,还有中间节点。起到加速的作用。
空间换时间,贯穿于整个数据结构和算法.

以此类推,通过增加索引级数来提高查询速度。

4.3、跳表查询的时间复杂度分析
n/2、n/4、n/8、第k级索引结点的个数就是n/(2^k)
假设索引有h级,最高级的索引有2个结点。n/(2^h)=2,从而求得h=log2(n)-1

索引的高度:logn,每层索引遍历的结点个数:3
在跳表中查询任意数据的时间复杂度就是O(logn),也就是从最朴素的原始链表的O(n)的时间复杂度降到了log2n的时间复杂度。
现实中的跳表:维护成本相对较高,每增加或删除一个元素的时候,需要把它的索引都更新一遍。(时间复杂度为logn)
4.4 跳表的空间复杂度

5、工程中的应用
- LRU Cache - Linked list: LRU 缓存机制
- Redis - Skip List:跳跃表、为啥 Redis 使用跳表(Skip List)而不是使用 Red-Black?
真的是干货慢慢,因为每一块知识点展开都是长篇文章的。
