文章目录
文章较长,想看哪儿请直接点目录
先奉上源码链接项目源码
一、项目概述
1、效果展示
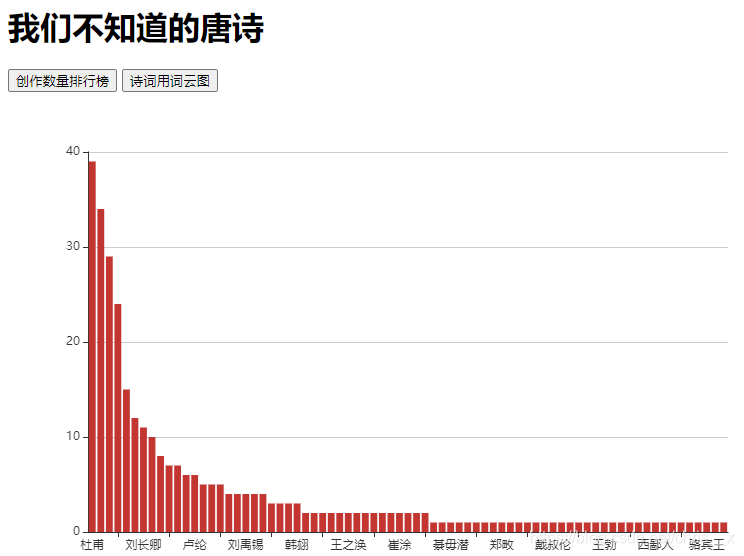
先来看一下项目最终的效果什么样子的,从项目名称可以看出来这个项目是对唐诗的数据进行分析,实现两个功能,也就是我们的需求
功能一:图一这样,以作者创作数量的大小进行排序
功能二:将作者用的高频词汇统计出来,看看古人爱用哪些词
最终用户看到的就是一个分析好的结果。

2、核心技术
①、第三方库的使用,比如HtmlUtil、Servlet、ansj_seg等
②、JavaEE,JAVA和数据库的综合英勇
③、多线程和线程池的理解使用
④、SHA256去重算法
⑤、HTTP协议
⑥、echarts、jQuery、ajax前端展示的使用
⑦、GSON数据格式
⑧、软件测试的基本思想应用
⑨maven的使用
为什么选择maven开发?
1、maven一个命令就可以完成项目构建过程
2、他可以进行强大的依赖管理
3、可以分阶段进行构建
4、提供web项目的模式
3、设计思想
想一下现在需求明确了,就该着手去考虑怎么下手做,我要分析数据,那数据从哪儿来?往哪儿存?怎么存?这是第一个大方面;第二个方面,我有数据了,那用户会去看你找到的数据吗?用户是最懒得,他只想看到上图统计好的结果,那问题来了,怎样展示?所以就可以分为两大模块去做,数据获取和数据展示。

数据的来源应该是公开的,就比如我们不能去获取教务系统存的学生信息,所以选择唐诗三百首,这里的诗词信息都公开
我是要把数据存的数据库,所以表怎么建,要是存进来的数据重复了怎么处理?要统计高频词的前提是知道怎样分词?存进来了怎么让前端获取数据去可视化。
二、诗词数据获取部分
请求列表页->解析列表页->下载详情页->解析详情页->想办法去重->计算分词->存入数据库
1、请求和解析列表页
引入HtmlUnit这个第三方库来帮我们解析,它是一个无界面的浏览器,它自带http客户端,给他一个url,它就会去请求页面。用它里面的webclient类,就可以完成请求和解析,从列表页里筛选我们需要的标签进入详情页,它的一些api使用案例里面有
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.36.0</version>
</dependency>
HtmlUnit使用案例
public class HtmlUnitDemo {
public static void main(String[] args) throws IOException {
//无界面的浏览器(HTTP客户端),假装自己是谷歌浏览器
WebClient webClient=new WebClient(BrowserVersion.CHROME);
//可能第三方库里写的css和js不标准,运行会报警告,所以先关了。关闭浏览器css执行引擎
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
//把url放进去,它会返回HtmlPage类型的数据
HtmlPage page = webClient.getPage("https://so.gushiwen.org/gushi/tangshi.aspx");
//保存列表页html文档,放到文件里
page.save(new File("唐诗三百首\\列表页.html"));
//html的body
HtmlElement body=page.getBody();
//筛选包含我们所需内容的标签,保存标签的内容,3个参数:元素名称,标签名称。标签值,
List<HtmlElement> elements = body.getElementsByAttribute("div",
"class",
"typecont");
HtmlElement divElement = elements.get(0);
List<HtmlElement> aElement = divElement.getElementsByAttribute("a",
"target",
"_blank");
//一个详情页的URL
String str=aElement.get(0).getAttribute("href");
}
}
2、请求和解析详情页
跟上面的道理是一样的,用HtmlPage/HtmlElement,这次用Xpath来获取
标题xpath="//div[@class='cont']/h1/text()";
朝代 (第一个 a 标签,下标从一开始)
xpath="//div[@class='cont']/p[@class='source']/a[1]/text()";
作者 (第二个 a 标签)
xpath="//div[@class='cont']/p[@class='source']/a[2]/text()";```
正文
xpath="//div[@class='cont']/div[@class='contson']";
3、SHA256算法去重
public class SHA256Demo {
public static void main(String[] args) throws NoSuchAlgorithmException, UnsupportedEncodingException {
MessageDigest messageDigest=MessageDigest.getInstance("SHA-256");
String s="你好世界";
//转成字节数组,通过update传进去,调用digest
byte[] bytes = s.getBytes("UTF-8");
messageDigest.update(bytes);
byte[] result = messageDigest.digest();
System.out.println(result.length);
for (byte b : result) {
System.out.printf("%02x",b);
}
System.out.println();
}
}
4、计算分词
引入第三方库,给它一句话,可以帮你分成词,而且使用很方便,AnsjSeg提供了四种分词调用的方式:基本分词(BaseAnalysis)、精准分词(ToAnalysis)、NLP分词(NlpAnalysis)、面向索引分词(IndexAnalysis) NLP分词方式是未登录词,但速度较慢:
<dependency>
<groupId>org.ansj</groupId>
<artifactId>ansj_seg</artifactId>
<version>5.1.6</version>
</dependency>
public class DetailPartDemo {
public static void main(String[] args) throws IOException {
try (WebClient webClient = new WebClient(BrowserVersion.CHROME)) {
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
String url = "https://so.gushiwen.org/shiwenv_45c396367f59.aspx";
HtmlPage page = webClient.getPage(url);//url传进去得到body部分
HtmlElement body = page.getBody();
/*
List<HtmlElement> elements = body.getElementsByAttribute(
"div",//输出正文对应的id
"class",
"contson"
);
for (HtmlElement element : elements) {
System.out.println(element);
}
System.out.println(elements.get(0).getTextContent().trim());//输出正文内容
*/
// 标题 朝代 作者 正文
{
String xpath = "//div[@class='cont']/h1/text()";
Object o = body.getByXPath(xpath).get(0);//取第一个就行
DomText domText = (DomText) o;//文档对象树
System.out.println(domText.asText());
}
//1就代表第一个 a[1]
{
String xpath = "//div[@class='cont']/p[@class='source']/a[1]/text()";
Object o = body.getByXPath(xpath).get(0);
DomText domText = (DomText) o;
System.out.println(domText.asText());
}
{
String xpath = "//div[@class='cont']/p[@class='source']/a[2]/text()";
Object o = body.getByXPath(xpath).get(0);
DomText domText = (DomText) o;
System.out.println(domText.asText());
}
{
String xpath = "//div[@class='cont']/div[@class='contson']";
Object o = body.getByXPath(xpath).get(0);
HtmlElement element = (HtmlElement) o;
System.out.println(element.getTextContent().trim());
}
}
}
}
5、存入数据库
分为建库建表在连接,要完整的描述一首诗,肯定要有作者、朝代、标题、正文、分词这些信息,连接数据库我们引入第三方库来连接
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
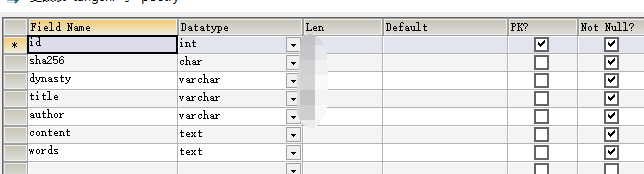
到这里数据获取部分就算是完成了
三、数据可视化部分
1、前端页面渲染工具echatrs
一个免费的js可视化库,上面的项目效果就是它做出来的。写起来简单,这个项目比较简单,基本碰不上它的bug,支持国产
2、RankServler处理作者作诗数
提供一个接口给前端处理作者作诗数的统计
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
public class RankServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
resp.setContentType("application/json; charset=utf-8");
//用的get方法
String condition = req.getParameter("condition");
if (condition == null) {
condition = "5";
}
JSONArray jsonArray = new JSONArray();
try (Connection connection = DBConfig.getConnection()) {
String sql = "SELECT author, count(*) AS cnt FROM tangshi GROUP BY author HAVING cnt >= ? ORDER BY cnt DESC";
//把作者全部统计出来
try (PreparedStatement statement = connection.prepareStatement(sql)) {
statement.setString(1, condition);
try (ResultSet rs = statement.executeQuery()) {
while (rs.next()) {
String author = rs.getString("author");
int count = rs.getInt("cnt");
JSONArray item = new JSONArray();
item.add(author);
item.add(count);
jsonArray.add(item);
System.out.println(author+":"+count);
}
resp.getWriter().println(jsonArray.toJSONString());
}
}
} catch (SQLException e) {
e.printStackTrace();
JSONObject object = new JSONObject();
object.put("error", e.getMessage());
resp.getWriter().println(object.toJSONString());
}
}
}在这里插入代码片
3、wordServlet提供给前端处理用词统计
public class WordServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws IOException {
String condition=req.getParameter("condition");
if(condition==null){
condition="5";
}
HashMap<String,Integer>map=new HashMap<>();
Connection connection = DBConfig.getConnection();
String sql="SELECT word FROM tangshi";
PreparedStatement statement=null;
try {
statement = connection.prepareStatement(sql);
ResultSet rs = statement.executeQuery();
while (rs.next()){
String word=rs.getString("word");
String[] split = word.split(",");
for (String s : split) {
int count=map.getOrDefault(s,0);
map.put(s,++count);
}
}
// System.out.println(map.toString());
} catch (SQLException e) {
e.printStackTrace();
JSONObject object = new JSONObject();
object.put("error", e.getMessage());
resp.getWriter().println(object.toJSONString());
}finally {
DBConfig.close(connection,statement);
}
JSONArray jsonArray=new JSONArray();
for (String s : map.keySet()) {
JSONArray item=new JSONArray();
item.add(s);
item.add(map.get(s));
jsonArray.add(item);
}
resp.setContentType("application/json ; charset=utf-8");
resp.getWriter().println(jsonArray.toJSONString());
System.out.println(jsonArray.toJSONString());
}
}
4、前后端交互jQuery
利用$.ajax()发起一个HTTP请求,后台收到请求时返回给前端一个index.html文件,这个文件里面的Script标签又会主动向后台发送http请求,得到json格式的数据,js中的代码把数据写到echart中,页面就展示出来了也引入第三方库,js请求交给相对应的servlet去处理(创作数量排行榜用RankServlet()去处理,诗词用词云图用wordServlet()去处理)
这里也引入servlet第三方库
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>3.1.0</version>
<scope>provided</scope>
</dependency>在这里插入代码片
四、项目改进办法
1、原始方法单线程
所有工作只有主线程一个人在做,线程安全但速度太慢了
2、改进方法一多线程
增加速度,列表页的请求和解析整个项目只执行一次,所以放在主线程中去做而;详情页的请求和解析需要执行320次,在多线程中去做,同理提取诗词信息(标题,作者,内容)、计算 sha256 的值、计算分词、信息插入数据库等步骤放到多线程中去做
引入的问题:线程不安全,webclient messagedigest ,preparedstament、datasource都线程不安全,加锁的话达不到高效率的目的,所以让每个线程建立自己的对象,
3、改进方法二线程池
线程池可以减少线程创建和销毁的次数,但线程池中的线程不会结束,因为jvm在所有非后台线程都结束后才会结束,我们用CountDownLatch,在主线程中调用countDownLatch,作为参数传给线程,调用pool.shutDown();让线程池结束
五、对项目的具体测试
①功能测试
1、点击创作数量排行榜,页面正常显示,如上图
2、二次点击创作数量排行榜,同名次的人会被替换
3、点击诗词用词云图,页面正常显示
4、多次点击诗词用词云图可将所有字展示出来
5、没有网络时,功能不可用
6、运行过程中关闭tomcat,显示失败
7、获取数据部分写完运行可以存进数据库
8、数据的过滤清洗得到了预期的结果
9、数据库异常时访问失败
10、统计到得到诗人作诗数量经测试一致
11、在进行结果分析时断网
12、超过数据库字段设置的最大长度会报错
13、多次启动爬取数据会报错
14、爬的过程中执行truncate table
②性能测试
1、响应时间都、在三秒以内,符合358原则
2、单线程版本数据从爬取到插入数据库需要38秒
3、多线程版本数据从爬取到插入数据库需要5秒
4、线程池版本数据从爬取到插入数据库需要4秒
5、多个用户同时点击时,系统会不会崩溃
③界面测试
1、页面排版符合预期效果
2、页面字体大小是否合适
3、页面的整个布局是否合理
4、界面按钮在预期位置
5、页面文字显示正确
④兼容性测试
1、在谷歌浏览器可正常显示
2、在搜狗浏览器可正常显示
3、在IE浏览器可正常显示
4、在火狐浏览器可正常显示
5、在linux环境下可运行
6、在win7环境下可运行
7、在winxp环境下可正常显示
8、手机可正常显示
9、每一个浏览器的不同版本也要测试
10、在苹果系统运行正常
⑤安全性测试
1、数据库方面的安全
2、反爬虫方面
⑥易用性测试
1、不能用上下左右键操作功能切换,对没有鼠标的人不方便
2、页面功能按钮设计直观,用户很容易理解
3、输入一个简单的url就可以展示结果