最近沉迷于学习政治经济学无法自拔,听了很多资本论相关的课程。今天也尝试通过what how who的方式介绍下联邦学习,
(感谢这个领域的专家,老同学Dr Liu给我的输入)
灵魂三问指的是:
1.联邦学习解决了什么问题
2.联邦学习怎么解决的问题
3.具备什么样条件可以实现联邦学习商业化
联邦学习解决了什么问题?
联邦学习最早是Google在差不多两年前提出的,当时我还兴奋地发了一个文章讲联邦学习。Google定义了联邦学习的概念,是通过多个终端联合建模,实现一个完整的强大的模型。
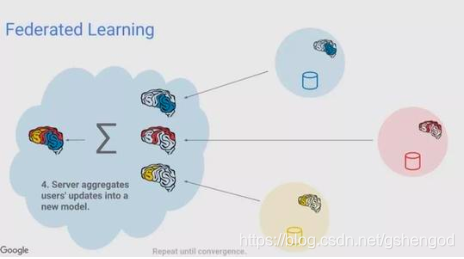
Google提出联邦学习后呢,这个方向一直不温不火,因为仿佛联邦学习解决的是不同终端间分布式建模的问题,把联邦学习看作一种框架性的问题。
但是最近,国内一些公司开始逐步实现了联邦学习的商业化,甚至有类似于FATE这样的联邦学习开源框架产生。我个人认为,联邦学习之所以能在商业化场景找到突破口,是因为一些公司成功的重新定义了联邦学习解决的问题。
今天在机器学习领域,框架性的问题有很多解决方案,但是数据的共享问题一直没有好的答案。联邦学习被重新定义为解决数据共享的一种方案,用来解决数据孤岛问题。
之前在写《机器学习实践应用》的时候我做过一个调研,这个世界上92%以上的数据会保留到少数10家互联网巨头的数据库里。也就是说,普通的企业如果想做模型的训练,数据样本不足是一个很大的问题,而且数据交互在业内基本上是禁区。
所以,如果将联邦学习重新定位为解决数据孤岛问题,在商业化方面的机会点会远比解决一些技术框架性问题的机会大得多。
联邦学习如何解决数据孤岛问题?
首先大家要知道一个概念,机器学习模型可以简单理解是一组权重值,在做模型训练的时候的本质目的是找到这些权重值发展的合理方向,类似于求导。这种方向性可以通过梯度表示,联邦学习就是利用了梯度的交换实现了不同终端的联合建模。
如上图讲的,公司A和B,虽然不能交换数据共同建模,但是他们可以把各自模型训练过程中的梯度做交换,因为梯度在离开数据之后是没有实际意义的,也不会有监管和法律风险。
所以联邦学习将模型训练抽象成了利用多个模型间的模型的共享梯度进行建模,这就将联邦学习转换成了迁移学习,迁移学习接下来的技术手段就很成熟了。
于是,联邦学习的技术难点并不在通过得到的梯度去优化模型,因为这一部分的技术很成熟。联邦学习的难点在于如何做到各个公司间的梯度共享,因为这里面涉及到许多加密传输相关的问题,是信息编码理论的范畴。编码有很多方式,最简单的可能就是哈希一下再传输(这部分没研究过,虽然我本科是通信与信息专业毕业)~
总结下,联邦学习解决问题的技术手段就是在迁移学习的基础上加上信息编码技术。这里面涉及到相当多的细节,就不展开了。
比如我提一个课后题,联邦学习怎么做预测?假如某纵向联邦学习生成了一个10个特征的模型,是由A和B两家公司共同建模完成,每个公司贡献5个特征。A公司拿到这个模型要怎么用呢?因为A只有包含5个特征的数据样本啊~嘿嘿,这里面有很多设计,大家开通脑筋想一想。
具备什么样的条件才能实现联邦学习?
马克思在《资本论》里说:“社会主义革命,会首先在生产力发达的国家诞生。”那想做联邦学习这个生意需要什么样的前提条件呢?
首先,联邦学习按照数据的X和Y问题,分为横向联邦和纵向联邦。
纵向:
横向:
以中国互联网公司的情况,横向联邦是很难有大的市场的。因为横向联邦意味着两家公司需要数据格式一致,那大概率是在同一领域的相互竞争的两家公司,合作的概率不大。
商业机会可能在纵向联邦,需要有一家数据非常全的公司,然后其它小公司跟这家公司撞库,这个商业模式是可能的。而梯度交换又要求所有使用联邦学习的公司必须数据在同一云平台。
所以,我大胆预测,如果未来几年有谁能做好公共云联邦学习的生意,一定背靠某个国内的大的云厂商才行。这个论断纯属YY,毕竟国内还没有特别成功的关于联邦学习的范例共参考。