【论文学习】关于联邦学习激励机制的三篇论文
企业开发
2023-04-07 09:26:16
阅读次数: 0
A Game-theoretic Approach for Robust Federated Learning
- 题目截图

- 主要内容:探究纳什均衡下的收益函数,考虑更可信地聚合,利用kmeans算法聚类得到可信模型参数
- 1.考虑某次迭代的更新的加权平均,通过计算偏离得到客户端的可信度,利用kmeans聚类得到诚实和恶意节点
- 2.引入概率,考虑误判
- 3.引入博弈论模型,对误判的节点进行补偿,求解纳什均衡点
Privacy-Preserving Blockchain-Based Federated Learning for IoT Devices
- 题目截图

- 主要内容:引入差分隐私到提取的特征上,使用multi-krum梯度选择算法考虑恶意节点,构造简单的声誉激励模型
- 1.利用multikrum算法,求出每个节点到最邻近的节点的总距离,从而判定其是否存在偏离,然后排序计算,利用声誉机制,对其进行记录和奖赏
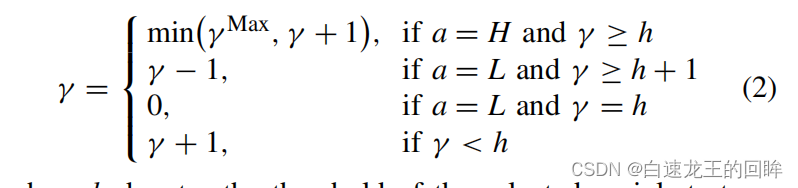
- reputation上升得慢,下降得快
- 提出了一种高效的归一化方法,融合进拉普拉斯噪声,实验表明学习精确率得到提高
Auction-Based Ex-Post-Payment Incentive Mechanism Design for Horizontal Federated Learning with Reputation and Contribution Measurement
- 题目截图

- 主要内容:通过声誉和拍卖制定的竞标价选择客户,通过给样本权重以及考察不同节点在不同样本的表现(测试集的精度)得到评价,基于表现和可信度构造出声誉的计算公式;考虑连续作恶以及连续善意的影响,使用构造法得到函数,最后通过了激励机制的五个特性的证明
- 考虑选择,评判和支付可靠的节点
- 考虑不同样本的权重不同,通过测试集定义节点的表现
- 贡献为表现乘以权重
- 通过shapley值的方法来检测该节点是否通过
- 通过通过和失败的次数来定义可信度
- 信誉值即为贡献和可信度的成绩
- 信誉值可叠加
- 考虑连续成功和连续失败的次数,构造出特定的函数满足既定的性质
总结
- 激励机制无非就是选择,评判和支付
- 可以考虑跟dp结合,因为里面可以计算隐私损失,从而进行补偿!
转载自blog.csdn.net/weixin_40986490/article/details/129508863