1. 初始爬取源
https://voice.baidu.com/act/newpneumonia/newpneumonia/?from=osari_pc_3
找不到数据,放弃
2. 实际数据源
2.1 在腾讯新闻中找到了实时疫情数据
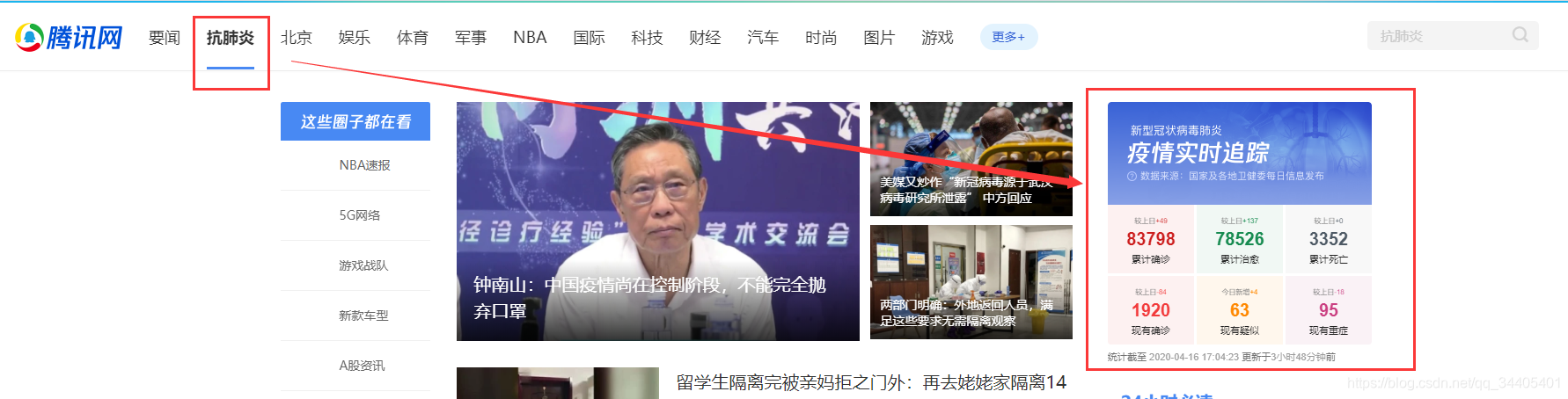
点击进入https://news.qq.com/zt2020/page/feiyan.htm#/global:
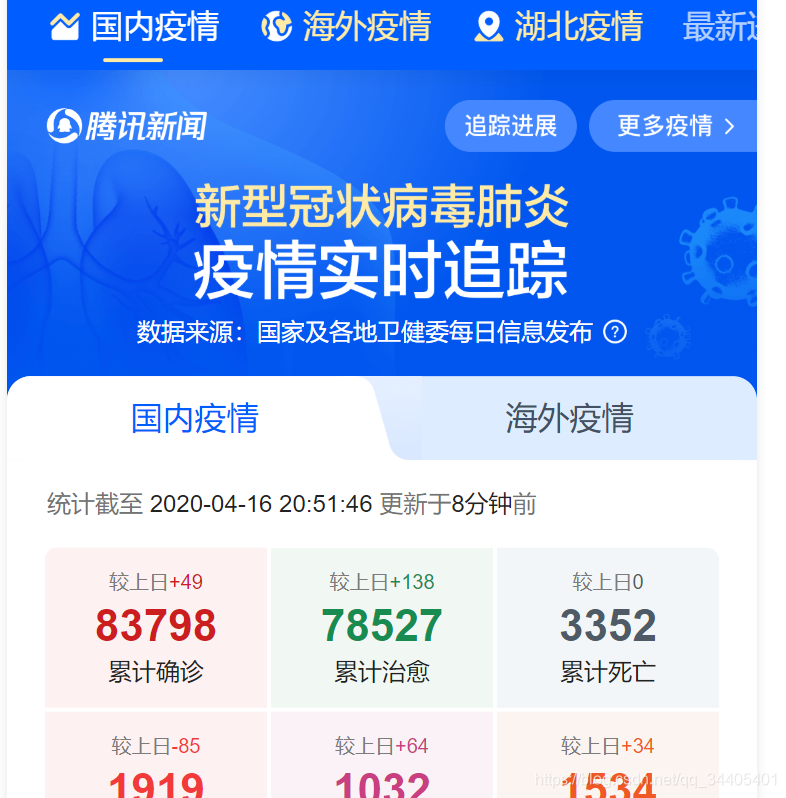
2.2 先试着从网页代码这个角度爬取
2.2.1 查看网页源码,发现这种无法直接爬取

2.3 直接找到数据爬数据
2.3.1 打开控制台,找此类存放数据的文件(这些文件不是js文件,且不是每个网站都能找到,此处以中国省份数据为例)
1.在response里找到
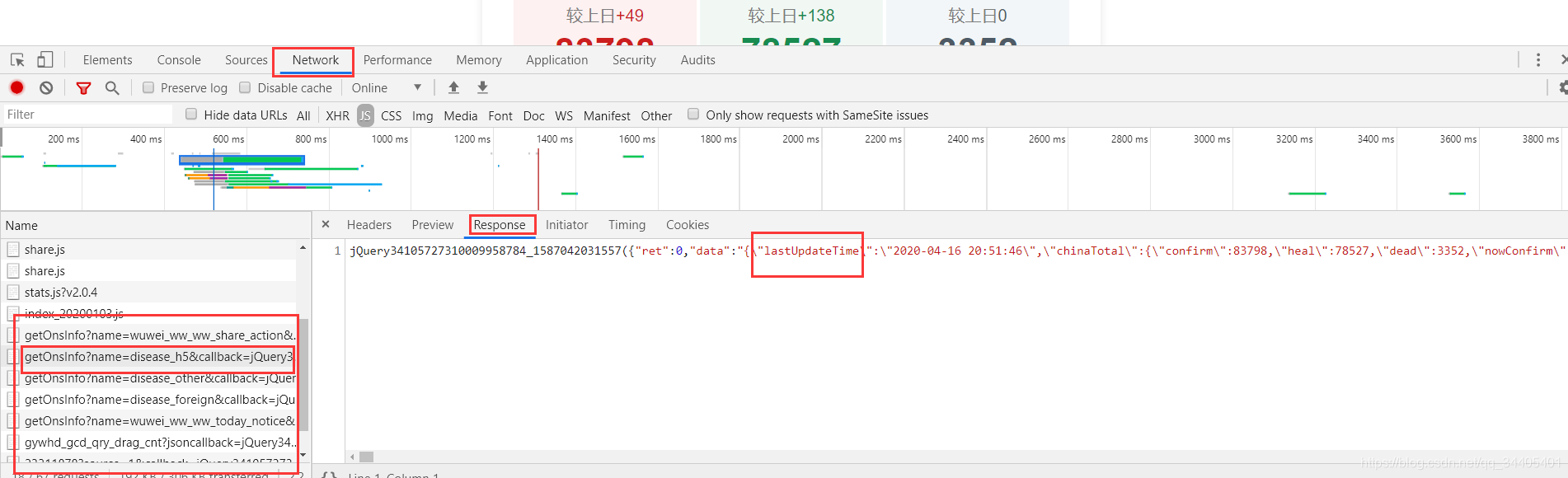
2.到header里找到请求Request URL,并在浏览器打开就可看到数据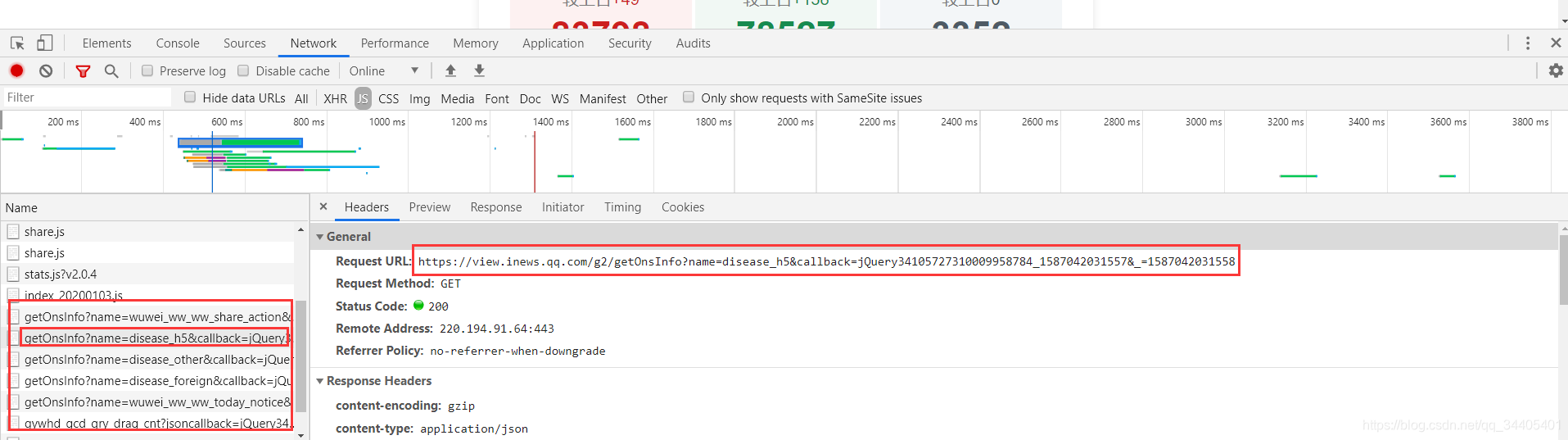
浏览器打开:
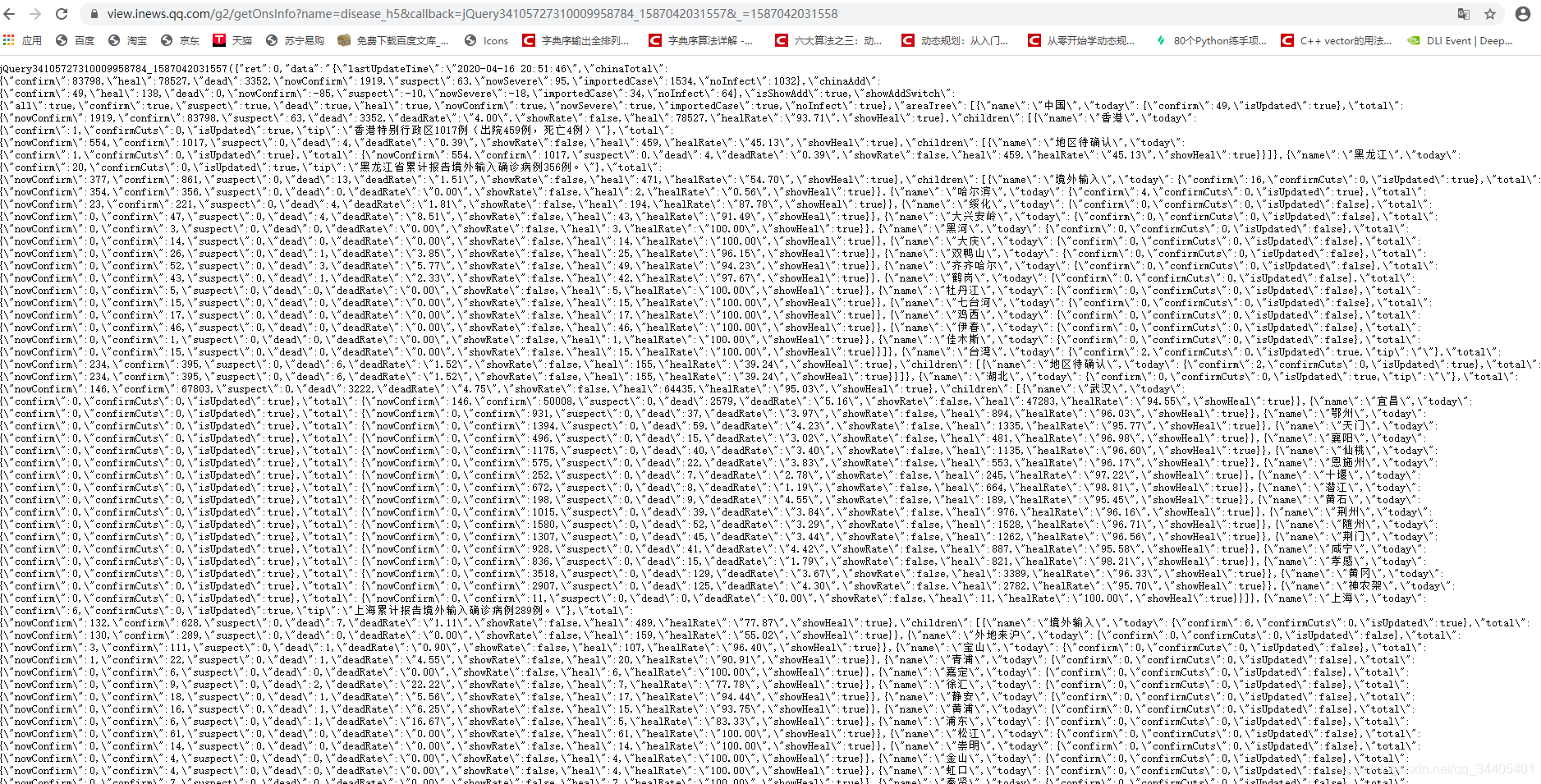
搜一个在线json格式化的工具,将页面中数据复制上去查看数据结构:

3. 代码
3.1 路径处理
查看header里的数据请求路径Request URL,可发现最后组成就是下方query string parameters里的,但是注意此处name保持不变,callback直接置空,最后一个参数是时间戳,我们可以用Python的time模块生成!
(但是后来实验发现header里Request URL内容一点不改去直接搜的话,也会出来最新结果)
3.2 代码
import requests
import time
import json
#获取疫情title部分的数据
def getTitle():
url = "https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=&_=%d"%time.time()
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36"}
response = requests.get(url, headers=headers)
#此时data是json数据
datas=response.text
#print(datas)
#将json数据转换为dict
datas=json.loads(datas)
#print(datas)
data = json.loads(datas['data'])
#print(data["chinaAdd"])
returnData={
"defineDiagnosis": {
"addNum": "昨日"+str(data["chinaAdd"]["nowConfirm"]),
"num": str(data["chinaTotal"]["nowConfirm"])
},
"noPerformance": {
"addNum": "昨日"+str(data["chinaAdd"]["noInfect"]),
"num": str(data["chinaTotal"]["noInfect"])
},
"doubtDiagnosis": {
"addNum": "昨日"+str(data["chinaAdd"]["suspect"]),
"num": str(data["chinaTotal"]["suspect"])
},
"defineSerious": {
"addNum": "昨日"+str(data["chinaAdd"]["suspect"]),
"num": str(data["chinaTotal"]["suspect"])
},
"cumulativeDefine": {
"addNum": "昨日"+str(data["chinaAdd"]["confirm"]),
"num": str(data["chinaTotal"]["confirm"])
},
"fromForeign": {
"addNum": "昨日"+str(data["chinaAdd"]["importedCase"]),
"num": str(data["chinaTotal"]["importedCase"])
},
"cumulativeCure": {
"addNum": "昨日"+str(data["chinaAdd"]["heal"]),
"num": str(data["chinaTotal"]["heal"])
},
"cumulativeDead": {
"addNum": "昨日"+str(data["chinaAdd"]["dead"]),
"num": str(data["chinaTotal"]["dead"])
}
}
return returnData