前言
今天给大家介绍的是Python爬取音频数据并保存本地
开发工具
Python版本: 3.6.4
相关模块:
requests模块
re模块
os模块
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
思路分析
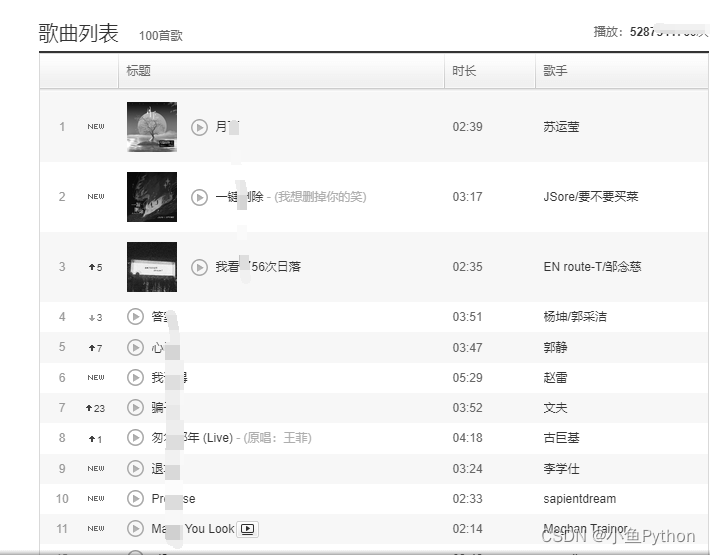
1.页面数据
浏览器中打开我们要爬取的页面
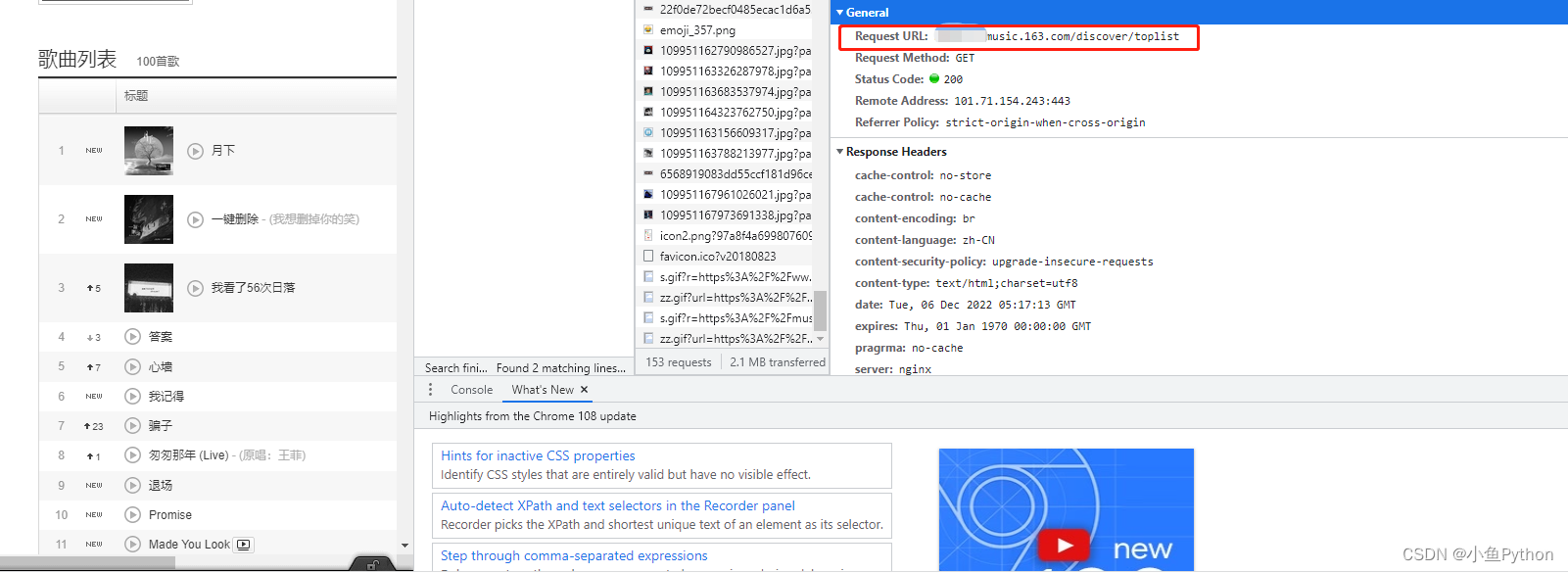
按F12进入开发者工具,查看我们想要的数据在哪里
这里我们需要页面数据就可以了
2.代码实现
伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
url = 'https://music.163.com/discover/toplist?id=3778678'
1.发送请求
response = requests.get(url=url, headers=headers)
2.获取数据
print(response.text)
3.解析数据
info_list = re.findall( 'lio<a href="/song \?id=(.*?)"">(.*?)</a></li>',html_data)
for music, title in result:
music_url = f'http://music.163.com/song/media/outer/url?id={
music}.mp3'
music_content = requests.get(url=music_url, headers=headers).content
4.保存数据
with open(filename + title + '.mp3', mode='wb') as f:
f.write(music_content)
print(title)
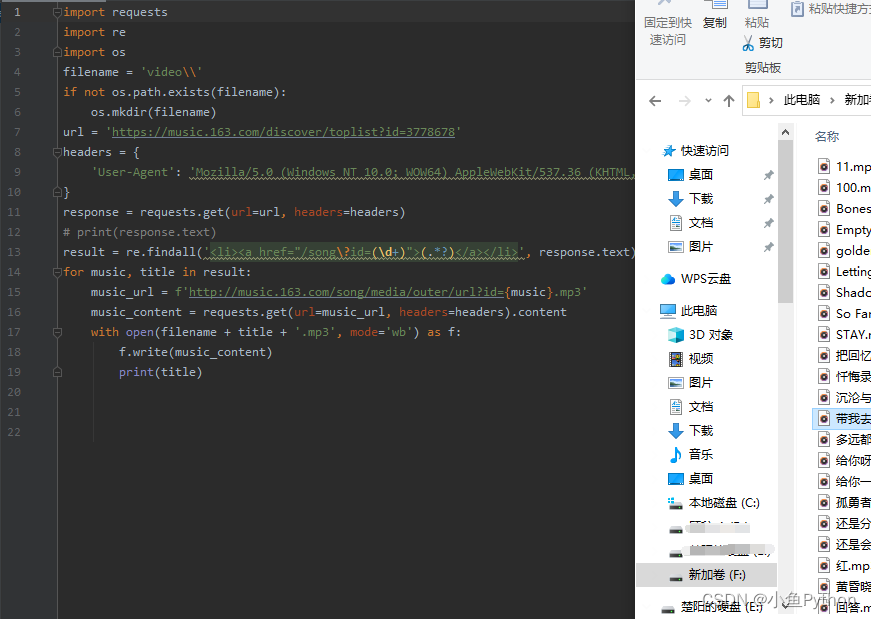
结果展示
最后
今天的分享到这里就结束了 ,感兴趣的朋友也可以去试试哈
对文章有问题的,或者有其他关于python的问题,可以在评论区留言或者私信我哦
觉得我分享的文章不错的话,可以关注一下我,或者给文章点赞(/≧▽≦)/