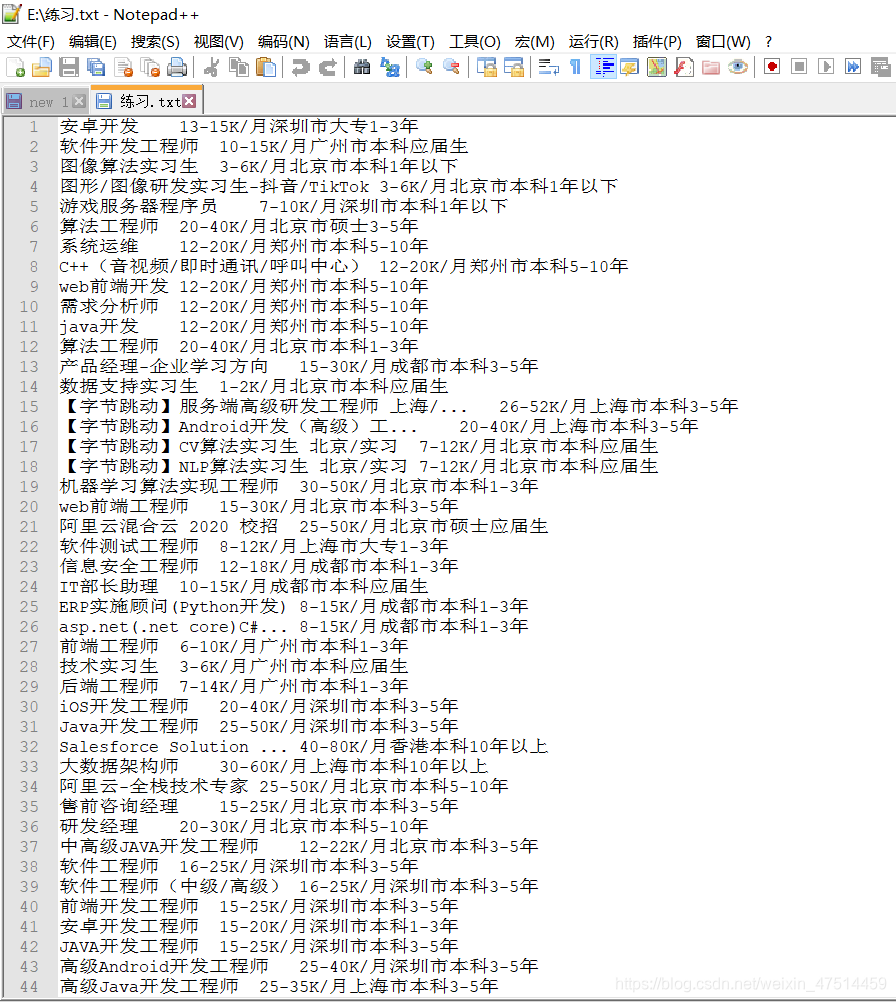
作为python的结束作业,小编写了一篇爬取关于IT招聘的一些内容,想知道一些IT行情,也欢迎大家一起来讨论讨论,废话不多说,开始干货吧。
首先先选择自己想爬取的内容
我想知道招聘里面的内容就点进网页下点f12,看看内容。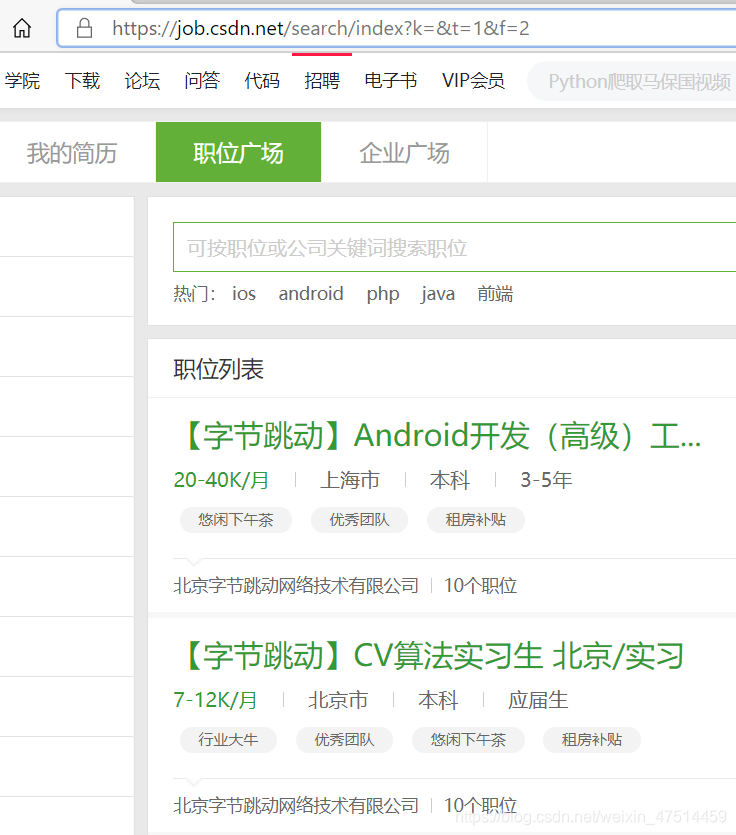
就可以看见自己要访问的网站在哪里了。
https://job.csdn.net/search/index?k=&t=1&f=1
https://job.csdn.net/search/index?k=&t=1&f=2
查看网页的不同点,分析网页翻页的规律
设置一个循环,实现翻页,
page = 1 # 设置条件
while page<=10:#设置循环条件,经行翻页
url=f'https://job.csdn.net/search/index?k=&t=1&f={page}'
这样我们就可以看出网页的下一页关键在f上。下面在网络中看自己服务器的头
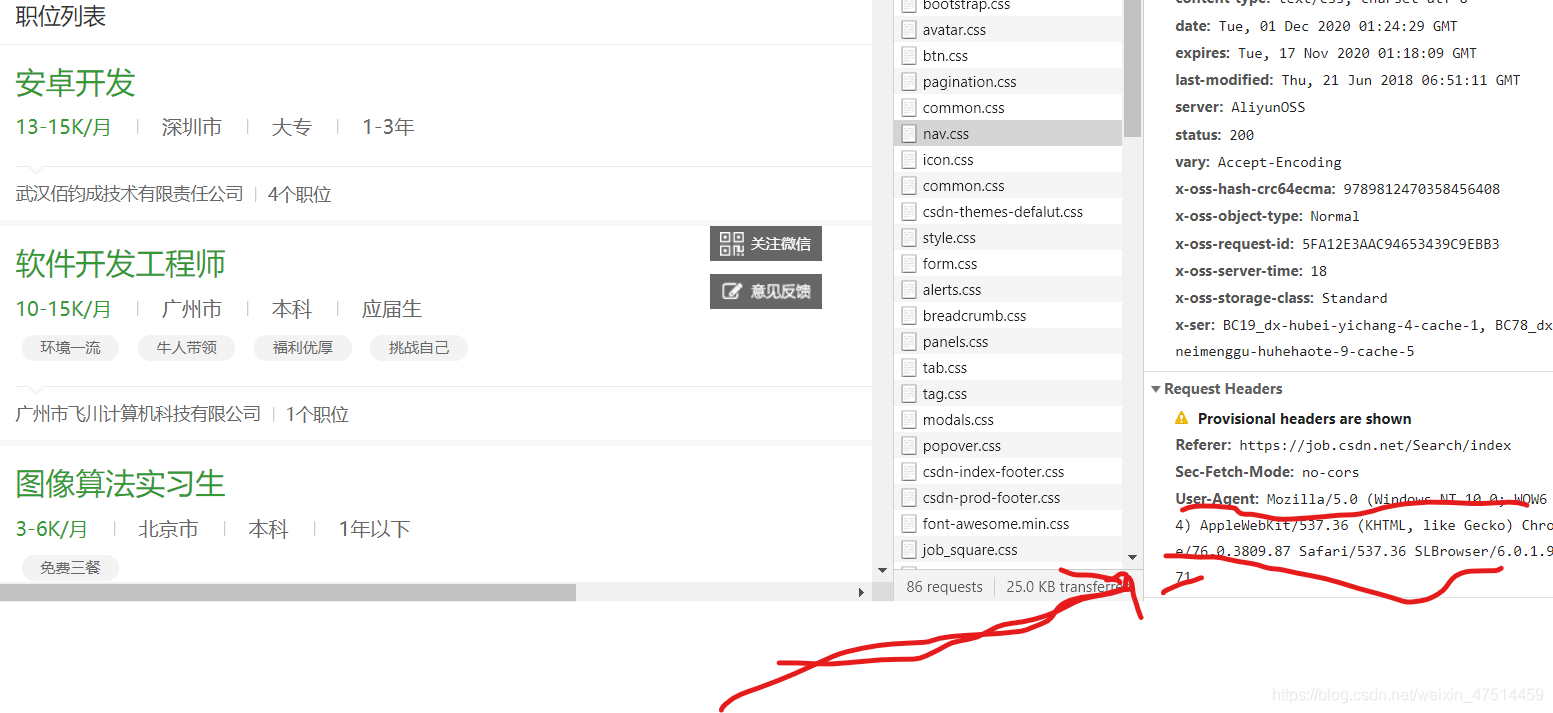
模拟头是为了防止反爬机制,不允许python头进行爬取。
headers= {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47"
}#模拟的服务器头
下面我们就导入模块实现爬取网页内容
import requests
from bs4 import BeautifulSoup#导入模块
response = requests.get(url,headers=headers)#换包头
newurl = response.text#获取网页内容
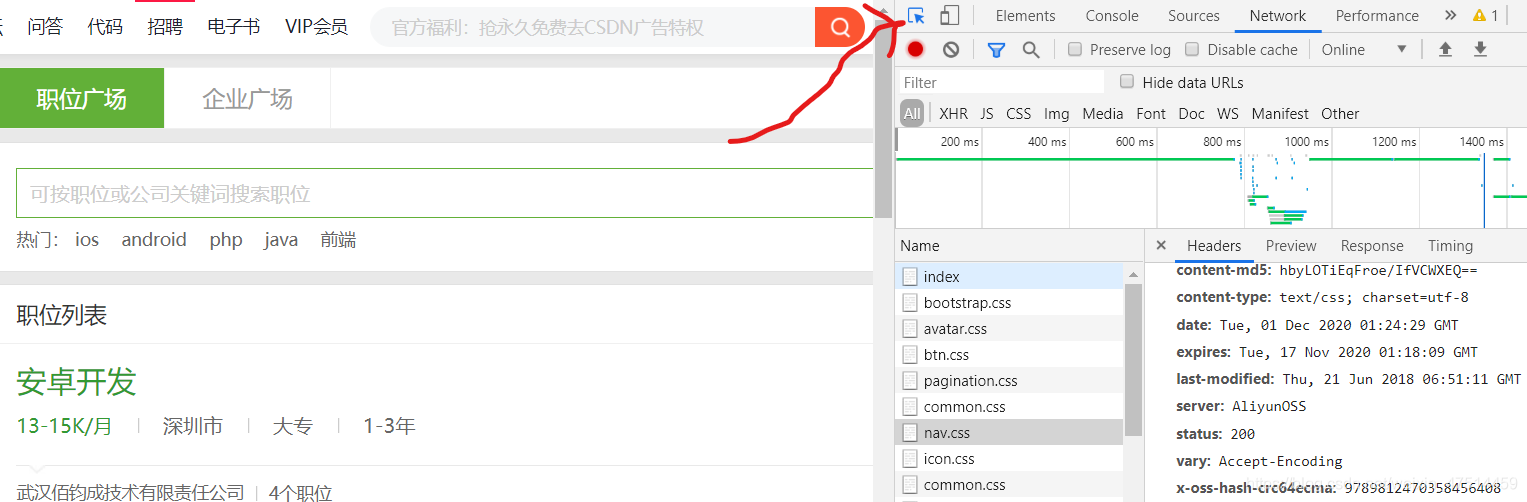
下面进行查找自己想要的内容(把箭头标记的地方点成蓝色,在网页上进行点击,就可以查看自己想要的内容了)

通过向上递归查找看看我们需要的内容。
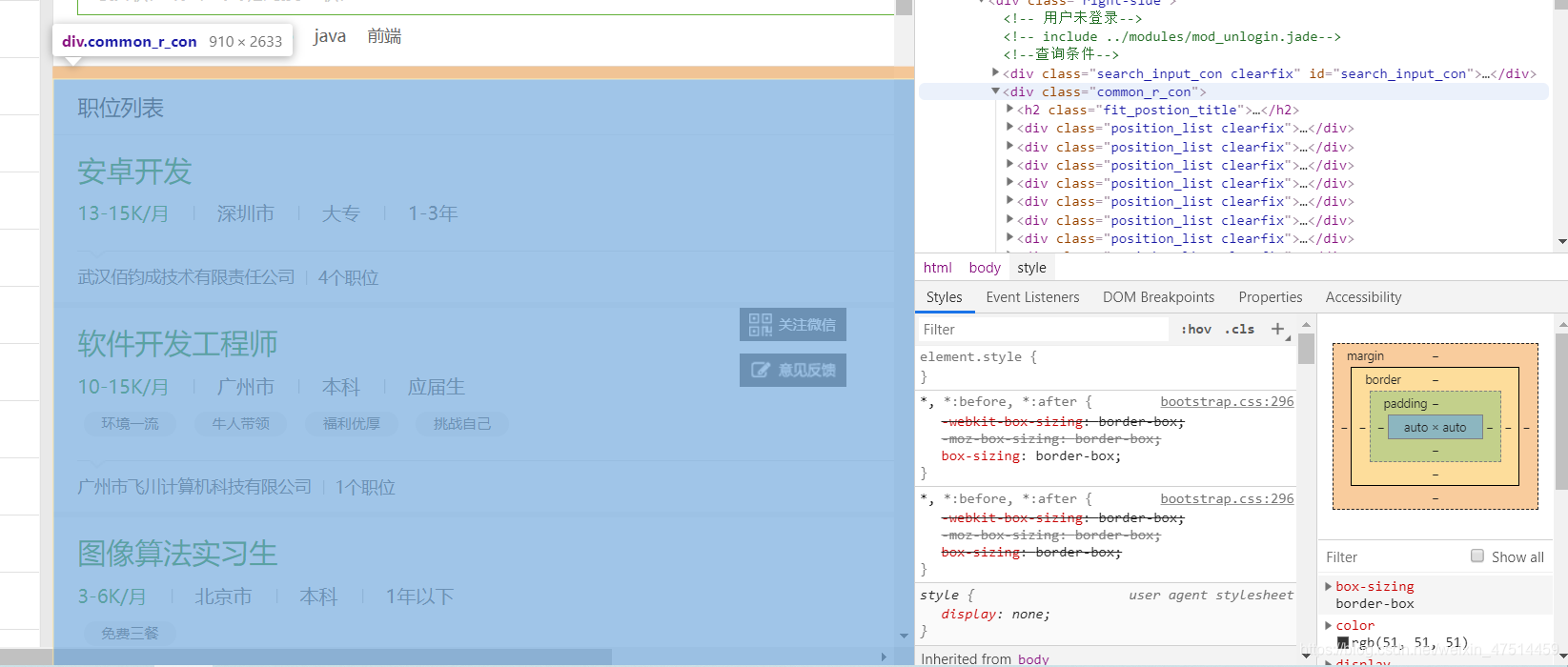
我需要的内容就出来了,在构建css选择器,进行标签查找,选择自己想要内容。
下面进行文件的保存,小项目就完成了。
with open(file= 'e:/练习.txt ',mode= 'a+') as f :#e:/练习.txt 为我电脑新建的文件,a+为给内容进行添加,但不进行覆盖原内容。
下面就是大家想要的完整代码。
'''
作者:ls富
时间:2020/12/1
构建对象
构建方法
方法
换头
请求数据
对数据进行筛选
写入文件夹
'''
import requests
from bs4 import BeautifulSoup#导入模块
class Position():
def __init__(self,position_name,position_require):#构建对象属性
self.position_name=position_name
self.position_require=position_require
def __str__(self):
return '%s%s/n'%(self.position_name,self.position_require)#重载方法将输入变量改成字符串形式
class Xiang():
def harder(self,url):
headers= {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47"
}#模拟的服务器头
response = requests.get(url,headers=headers)#换包头
newurl = response.text#获取网页内容
soup=BeautifulSoup(newurl,'html.parser') # BeautifulSoup打看网页
soupl = soup.select(".common_r_con")#进行选择页面第一次内容
results=[]#创建一个列表用来存储数据
for e in soupl:
biao=e.select('.position_list.clearfix')#进行二次筛选
for h in biao:
p=Position(h.select_one('.employ_pos_name').get_text(strip=True),h.select_one('.position_require').get_text(strip=True))#调用类转换(继续三次筛选选择自己需要内容)
results.append(p)
return results#返回内容
if __name__ == '__main__':
a=Xiang()#构建对象
url = f'https://job.csdn.net/search/index?k=&t=1&f=1'
a.harder(url)
import time
with open(file= 'e:/练习.txt ',mode= 'a+') as f :#e:/练习.txt 为我电脑新建的文件,a+为给内容进行添加,但不进行覆盖原内容。
page = 1 # 设置条件
while page<=10:#设置循环条件,经行翻页
url=f'https://job.csdn.net/search/index?k=&t=1&f={page}'
for item in a.harder(url):
line=f'{item.position_name}\t{item.position_require}\n'
f.write(line) # 采用方法
print("下载完成")
page += 1
效果