一、requests
request是请求库,用来获取页面信息。
首先记得导入库啊,这个是第三方库,py没有自带,没有安装的小伙伴可以移步我上一篇安装第三方库教程
import requests
介绍几个常用的函数
1> 请求命令
import requests
url = 'https://www.163.com'
resp = requests.get(url)
get用途其实跟构造函数差不多,它的参数不少,我们这里主要用到url和headers两个。
url:学过计网的自然懂,没学过的……嗯简单来说就是要爬取的网站。。。地址吧?(不准确)它其实就是浏览器地址框里那个。

headers:请求头,有时候网站会有反爬,加这个可以爬的更真实。这个放到后面讲。
2> 显示状态码
import requests
url = 'https://www.163.com'
resp = requests.get(url)
print(resp.status_code)
# >>200
爬取的状态。如果是200就代表成功了。
3> 显示文本格式的信息
import requests
url = 'https://www.163.com'
resp = requests.get(url)
print(resp.status_code)
print(resp.text)
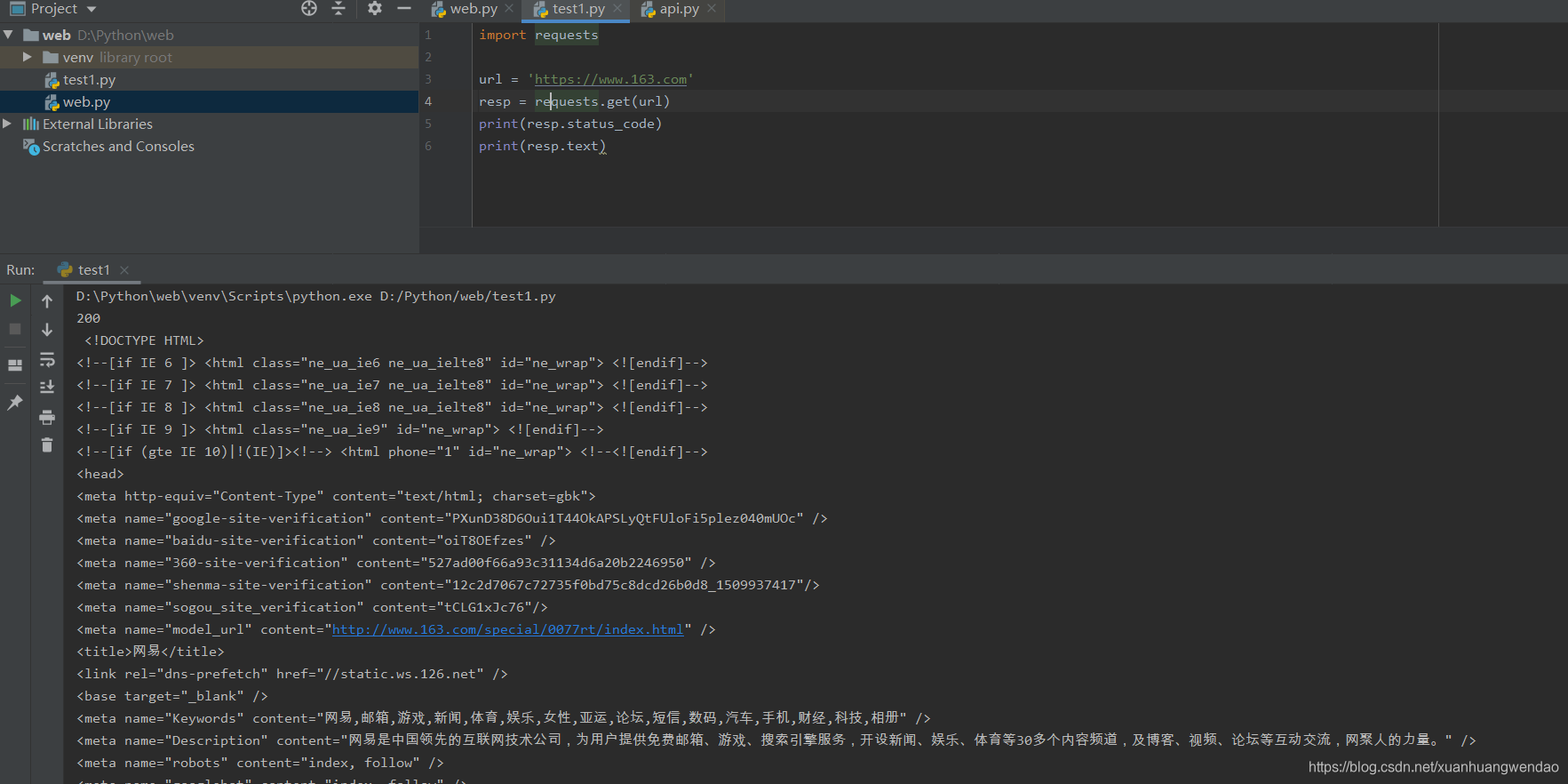
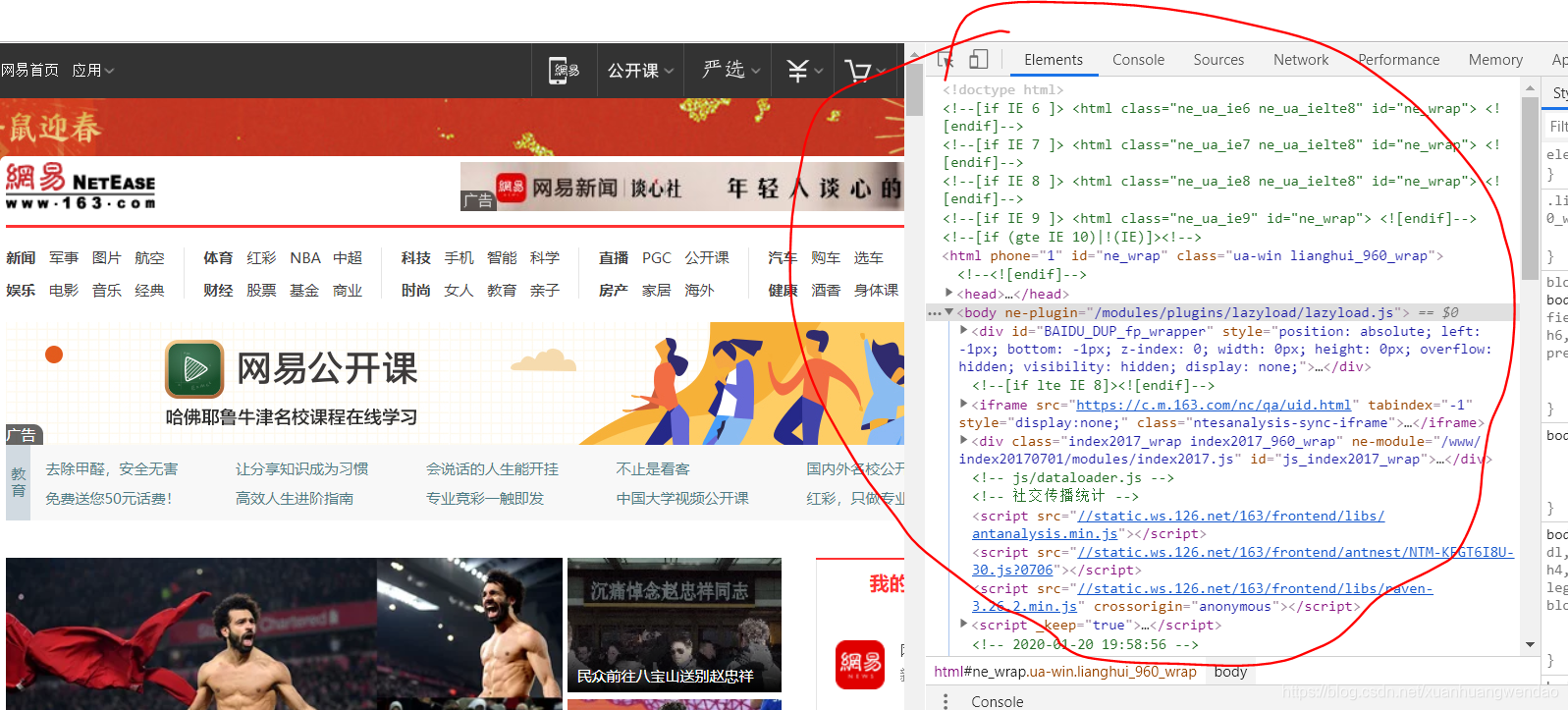
可以看到,我把网易首页的内容爬取出来了,这个其实就是网页的源码,我用的Chrome,F12键可以在浏览器查看
4> 显示源码信息
import requests
url = 'https://www.163.com'
resp = requests.get(url)
print(resp.status_code)
print(resp.text)
html = resp.content
上一个text是使用文本格式显示,我们用content方法将之存入变量html中。
以上就是requests的基本操作,下面我们开始解析源码。
二、BeautifulSoup
首先还是导入库
from bs4 import BeautifulSoup as bes
1、首先我们要把html转化为bs4可以解析的格式
from bs4 import BeautifulSoup as bes
soup = bes(html, 'html.parser') # 转化为bs4能解析的格式
2、定位元素
定位元素有很多方法,下面我介绍几个简单、好用、常见的。
方式1:soup.find(标签名)
这个方法用来返回第一个满足的Tag(就是标签)
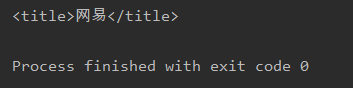
title = soup.find('title')
print(title)
方式2:soup.find_all(标签名)
这个就是返回所有满足的标签啦,结果以列表形式出现。
比如我想找所有标签名为em的标签

那么:
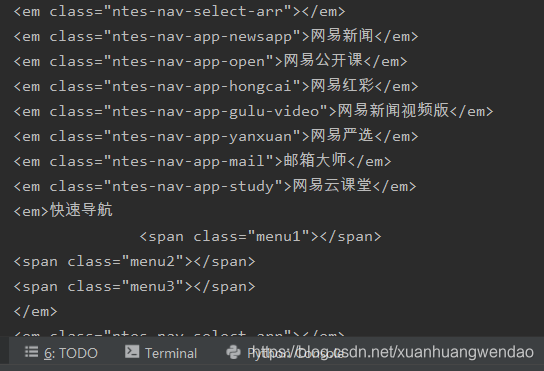
em = soup.find_all('em')
for one in em:
print(one)
结果:
方式3:CSS选择器
bs4还支持css选择器(啥是css不详细讲了),简单来说就是通过某种规则定位标签。
1> 通过标签名查找(木的特征)
首先最简单的,select也可以通过标签名查找。这个前面就不用加东西了。
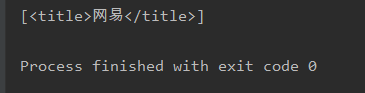
t = soup.select('title')
print(t)
2> 用class定位元素 (特征是点(.))
我们现想提取“网易新闻”那个Tag

em1 = soup.select('.ntes-nav-app-newsapp')
print('em1:', em1)
print(type(em1))

可以看到,select返回的结果是一个set类,也就是说它可以找到所有满足条件的Tag
3> 用id属性定位 (特征是井号(#))
同样,我们还可以用id来定位。

em2 = soup.select('#js_N_nav')
print('em2:', em2)
4> 属性查找(特征是[ ])
还可以根据Tag内属性来查找
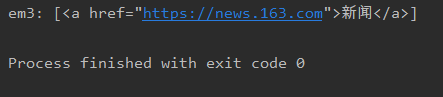
em3 = soup.select('a[href="https://news.163.com"]')
print('em3:', em3)
查找< a >标签中herf属性为OOXX的标签
5> 嵌套定位
html网页源码其实是一个树形结构,那么我们就可以一层一层的定位查找。

我们通过分析层次,提取北京要问信息
a = soup.select('div.yaowen_news > div.news_bj_yw > ul > li > a')
for one in a:
print(one, '\n')

emmm大家要注意身体啊,这肺炎挺严重的
首先认真分析源码,找出规律,再用上面几个方法组合起来使用,就可以得到想要的玩具标签了
3、提取内容
可以看到,我们所得到的信息中有好多乱七八糟的东西,我们想要的只是其中的内容罢了,这是我们就可以用get_text()来获取标签内容
a = soup.select('div.yaowen_news > div.news_bj_yw > ul > li > a')
c_list = []
for one in a:
c_list.append(one.get_text())
for one in c_list:
print(one)
我们把新闻标题存到了c_list里了

完工!
其实我觉得,爬虫这件事,三分看技术,七分看眼力,从不同中找相同,准确抓取自己想要的信息才是难点。
