上一篇中,安装和初步使用了requests+BeautifulSoup,感受到了它们的便捷。但之前我们抓取的都是文字信息,这次我们准备来抓取的是图片信息。
>第一个实例
我们来抓取这个网站的图片:http://www.ivsky.com/bizhi/stand_by_me_doraemon_v45983/
首先,审查网页元素:
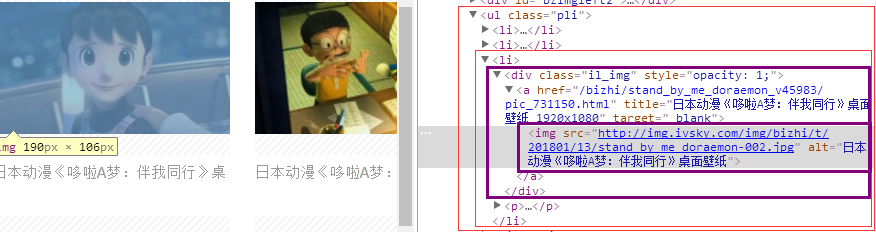
因此其结构就为:
<div class='il_img'> x 若干个,对每个div有 :
<img src='我们要的img src数据'>
整体思路是:
- 获取每个图片的src地址;
- 构建requests去请求img的src并获取图片;
- 写入文件
代码如下:
import requests
from bs4 import BeautifulSoup
pic_id = 0 # 图片编号
url = 'http://www.ivsky.com/bizhi/stand_by_me_doraemon_v45983/'
bs = BeautifulSoup(requests.get(url).content, "lxml") # 调用lxml作为解析引擎 需要:pip install lxml
for i in bs.select('.il_img'):
pic_url = i.find('img')['src']
pic_file = open('./pic_'+str(pic_id)+'.jpg', 'wb') # 二进制创建并写入文件
pic_file.write(requests.get(pic_url).content) # 写出请求得到的img资源
pic_id += 1
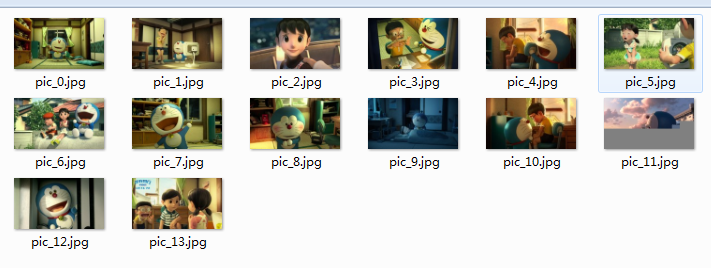
这样,就能在爬虫脚本目录下找到我们需要的图片了:
>第二个实例
这次我们来抓取这个网站的资源,要的是奖章图标+奖章等级+等级标志颜色+称号,并按照'等级+标志颜色+称号.gif'的方式存储:
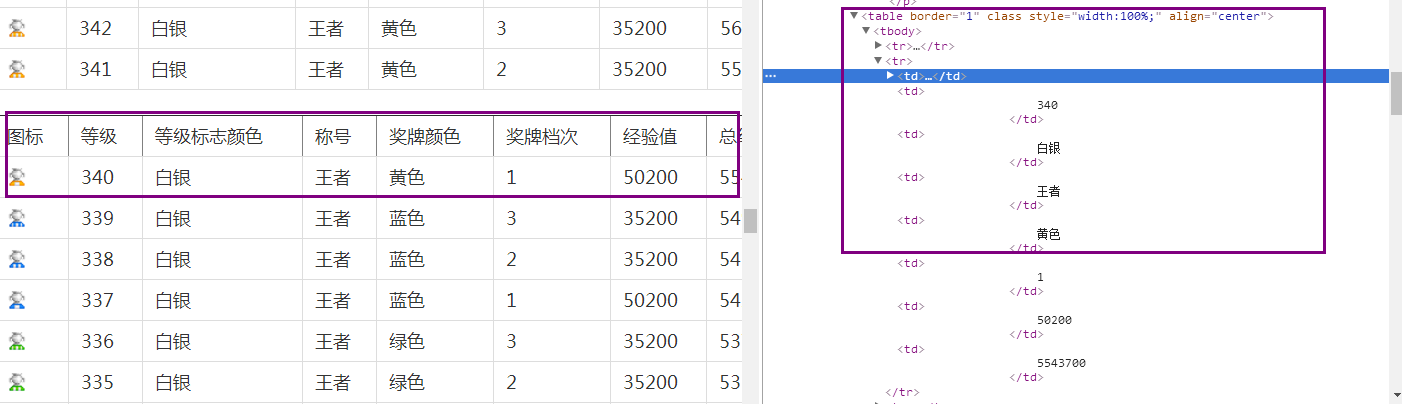
结构为:
<table>
<td>
<img> img-src
<td> 等级
<td> 颜色
<td> 称号
同样,也就可以给出相关的代码了:
import re
import requests
from bs4 import BeautifulSoup
url = 'http://ol.kuai8.com/gonglue/236751_all.html'
bs = BeautifulSoup(requests.get(url).content, "lxml")
for table in bs.find_all('table', attrs={'border': 1, 'align': 'center'}): # 获取所有的数据表
for td in table.find_all(td_with_img): # 获取含有img标签的td标签
img_src = td.img['src'] # 获取图片url
level = td.find_next_sibling('td') # 等级td节点
color = level.find_next_sibling('td') # 颜色td节点
title = color.find_next_sibling('td') # 称号td节点
opf = open(get_title(level.string, color.string, title.string), 'wb')
opf.write(requests.get(img_src).content)
print '已抓取:', re.sub('\s', '', level.string)
这里用了两个方法:
def td_with_img(node):
return node.name == 'td' and node.img is not None # 含有img标签的td标签
def get_title(level, color, title):
return './ppt/'+re.sub('\s', '', level)+re.sub('\s', '', color)+re.sub('\s', '', title)+'.gif' # 移除空白并直接得到文件名
我们的成果:
