机器学习中特征转换或利用是整个流程中的核心内容,这里介绍三个与之有关的三个主流技术:
Embedding Numerous Features: how to exploit and regularize
→
\rightarrow
→
Combining Predictive Features: how to construct and blend
→
\rightarrow
→
Distilling Implicit Features: how to identify and learn implicit
→
\rightarrow
→
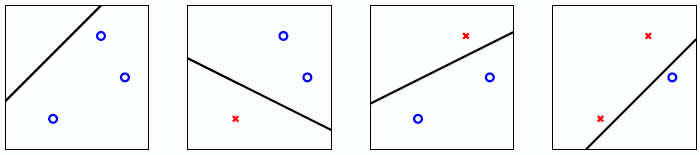
实际上相当于“大间隔的分割超平面 ” (Large - Margin Separating Hyperplane)。什么意思呢?
以线性分类模型 PLA 为例,其最终目标是找出一个超平面将所有的样本分割开。支持向量机实际上是在此基础上,保证离分割线最近的一些样本(
x
n
\mathbf{x}_{n}
x n
x
n
\mathbf{x}_{n}
x n
x
n
\mathbf{x}_{n}
x n
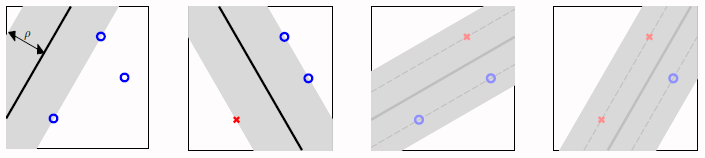
这样可以假设边界不是一条宽度不计的超平面,而是一个有宽度的胖超平面(fat hyperplane)。那么这里的胖度实际上就相当于鲁棒性即
robustness
≡
fatness
\text{robustness} \equiv \text{fatness}
robustness ≡ fatness
那么现在的目标就是找出那个最胖的一个超平面(fattest separating hyperplane)。
max
w
fatness
(
w
)
subject to
w
classifies every
(
x
n
,
y
n
)
correctly
fatness
(
w
)
=
min
n
=
1
,
…
,
N
distance
(
x
n
,
w
)
\begin{aligned} \max _{\mathbf{w}} \quad & \text {fatness }(\mathbf{w})\\ \text{subject to} \quad &\mathrm{w} \text{ classifies every } \left(\mathrm{x}_{n}, y_{n}\right) \text{ correctly}\\ & \text {fatness }(\mathbf{w})=\min _{n=1, \ldots, N} \operatorname{distance}\left(\mathbf{x}_{n}, \mathbf{w}\right) \end{aligned}
w max subject to fatness ( w ) w classifies every ( x n , y n ) correctly fatness ( w ) = n = 1 , … , N min d i s t a n c e ( x n , w )
至此胖胖的超平面正式叫做间隔(margin),据此将上式改写为:
max
w
margin
(
w
)
subject to
y
n
w
T
x
>
0
margin
(
w
)
=
min
n
=
1
,
…
,
N
distance
(
x
n
,
w
)
\begin{aligned} \max _{\mathbf{w}} \quad & \text {margin }(\mathbf{w})\\ \text{subject to} \quad & y_{n} \mathbf{w}^{T}\mathbf{x} > 0\\ & \text {margin }(\mathbf{w})=\min _{n=1, \ldots, N} \operatorname{distance}\left(\mathbf{x}_{n}, \mathbf{w}\right) \end{aligned}
w max subject to margin ( w ) y n w T x > 0 margin ( w ) = n = 1 , … , N min d i s t a n c e ( x n , w )
因为间隔的求取需要将
w
0
\mathbf{w}_0
w 0
(
w
0
,
⋯
,
w
d
)
(\mathbf{w}_0, \cdots , \mathbf{w}_d)
( w 0 , ⋯ , w d )
h
(
x
)
=
sign
(
w
T
x
+
b
)
h(\mathbf{x})=\operatorname{sign}\left(\mathbf{w}^{T}\mathbf{x} + b\right)
h ( x ) = s i g n ( w T x + b )
x
′
\mathbf{x}^{\prime}
x ′
x
′
′
\mathbf{x}^{\prime \prime}
x ′ ′
w
T
x
′
=
−
b
\mathbf{w}^{T}\mathbf{x}^{\prime} = -b
w T x ′ = − b
w
T
x
′
′
=
−
b
\mathbf{w}^{T}\mathbf{x}^{\prime \prime} = -b
w T x ′ ′ = − b
w
⊥
hyperplane
\mathbf{w} \perp \text{ hyperplane}
w ⊥ hyperplane
(
w
T
(
x
′
′
−
x
′
)
⏟
vector on hyperplane
)
=
0
\left(\begin{array}{cc} \mathbf{w}^{T} & \underbrace{\left(\mathbf{x}^{\prime \prime}-\mathbf{x}^{\prime}\right)}_\text { vector on hyperplane } \end{array}\right)=0
( w T vector on hyperplane
( x ′ ′ − x ′ ) ) = 0 所以样本到超平面(hyperplane)距离的计算公式为
distance
=
project
(
x
−
x
′
)
to
⊥
hyperplane
\text{distance }= \text{project }(\mathbf{x} - \mathbf{x}^{\prime}) \text{ to } \perp \text{ hyperplane}
distance = project ( x − x ′ ) to ⊥ hyperplane
即:
distance
(
x
,
b
,
w
)
=
∣
w
T
∥
w
∥
(
x
−
x
′
)
∣
=
(
1
)
1
∥
w
∥
∣
w
T
x
+
b
∣
\operatorname{distance}(\mathbf{x}, b, \mathbf{w})=\left|\frac{\mathbf{w}^{T}}{\|\mathbf{w}\|}\left(\mathbf{x}-\mathbf{x}^{\prime}\right)\right| \stackrel{(1)}{=} \frac{1}{\|\mathbf{w}\|}\left|\mathbf{w}^{T} \mathbf{x}+b\right|
d i s t a n c e ( x , b , w ) = ∣ ∣ ∣ ∣ ∥ w ∥ w T ( x − x ′ ) ∣ ∣ ∣ ∣ = ( 1 ) ∥ w ∥ 1 ∣ ∣ w T x + b ∣ ∣
对于分割超平面(separating hyperplane)有:
y
n
(
w
T
x
n
+
b
)
>
0
y_{n}\left(\mathbf{w}^{T} \mathbf{x}_{n}+b\right)>0
y n ( w T x n + b ) > 0
距离公式可以进一步写为:
distance
(
x
,
b
,
w
)
=
1
∥
w
∥
∣
w
T
x
+
b
∣
=
1
∥
w
∥
y
n
(
w
T
x
+
b
)
\operatorname{distance}(\mathbf{x}, b, \mathbf{w})= \frac{1}{\|\mathbf{w}\|}\left|\mathbf{w}^{T} \mathbf{x}+b\right|= \frac{1}{\|\mathbf{w}\|} y_{n} \left(\mathbf{w}^{T} \mathbf{x}+b\right)
d i s t a n c e ( x , b , w ) = ∥ w ∥ 1 ∣ ∣ w T x + b ∣ ∣ = ∥ w ∥ 1 y n ( w T x + b )
将最小的 margin 缩放至
1
∥
w
∥
\frac{1}{\|\mathbf{w}\|}
∥ w ∥ 1
min
n
=
1
,
⋯
,
N
y
n
(
w
T
x
+
b
)
=
1
\min_{n=1,\cdots,N} y_{n} \left(\mathbf{w}^{T} \mathbf{x}+b\right) = 1
n = 1 , ⋯ , N min y n ( w T x + b ) = 1
可以看出此缩放跟样本无关,只是将
x
\mathbf{x}
x
b
b
b 必要条件 :
y
n
(
w
T
x
n
+
b
)
≥
1
for all
n
y_{n}\left(\mathbf{w}^{T} \mathbf{x}_{n}+b\right) \geq 1 \text{ for all } n
y n ( w T x n + b ) ≥ 1 for all n
由于根号不好求取,所以这里将其转换为等价最优化问题求其倒数平方的最小值,并添加
1
2
\frac{1}{2}
2 1
min
b
,
w
1
2
w
T
w
subject to
y
n
(
w
T
x
n
+
b
)
≥
1
for all
n
\begin{aligned} \min _{b, w} \quad & \frac{1}{2} w^{T} w \\ \text{subject to }\quad & y_{n}\left(\mathbf{w}^{T} \mathbf{x}_{n}+b\right) \geq 1 \text{ for all } n \end{aligned}
b , w min subject to 2 1 w T w y n ( w T x n + b ) ≥ 1 for all n
二次规划(QP,全称 quadratic programming),是一个较为容易的优化问题。二次规划的标准形式为:
optimal
u
←
Q
P
(
Q
,
p
,
A
,
c
)
min
u
1
2
u
T
Q
u
+
p
T
u
subject to
a
m
T
u
≥
c
m
for
m
=
1
,
2
,
…
,
M
\begin{aligned} \text{optimal } \mathrm{u} \leftarrow & \mathrm{QP}(\mathrm{Q}, \mathrm{p}, \mathrm{A}, \mathrm{c}) \\ \min _{u} \quad & \frac{1}{2} u^{T} Q u+p^{T} u\\ \text{subject to }\quad & \mathbf{a}_{m}^{T} \mathbf{u} \geq c_{m} \text{ for } m=1,2, \ldots, M \end{aligned}
optimal u ← u min subject to Q P ( Q , p , A , c ) 2 1 u T Q u + p T u a m T u ≥ c m for m = 1 , 2 , … , M
对比支持向量机的最优化问题的数学表达,可以得出:
objective function:
u
=
[
b
w
]
;
Q
=
[
0
0
d
T
0
d
I
d
]
;
p
=
0
d
+
1
constraints:
a
n
T
=
y
n
[
1
x
n
T
]
;
c
n
=
1
;
M
=
N
\begin{aligned} \text{objective function:} \quad &\mathbf{u}=\left[\begin{array}{l} b \\ \mathbf{w} \end{array}\right] ; Q=\left[\begin{array}{ll} 0 & \mathbf{0}_{d}^{T} \\ \mathbf{0}_{d} & \mathrm{I}_{d} \end{array}\right] ; \mathbf{p}=0_{d+1}\\ \text{constraints:} \quad &\mathbf{a}_{n}^{T}=y_{n}\left[\begin{array}{ll} 1 & \mathbf{x}_{n}^{T} \end{array}\right] ; c_{n}=1 ; M=N \end{aligned}
objective function: constraints: u = [ b w ] ; Q = [ 0 0 d 0 d T I d ] ; p = 0 d + 1 a n T = y n [ 1 x n T ] ; c n = 1 ; M = N
u
=
[
b
w
]
;
Q
=
[
0
0
d
T
0
d
I
d
]
;
p
=
0
d
+
1
a
n
T
=
y
n
[
1
x
n
T
]
;
c
n
=
1
;
M
=
N
\mathbf{u}=\left[\begin{array}{l} b \mathbf{w} \end{array}\right] ; Q=\left[\begin{array}{ll} 0 & \mathbf{0}_{d}^{T} \\ \mathbf{0}_{d} & \mathrm{I}_{d} \end{array}\right] ; \mathbf{p}=0_{d+1} \mathbf{a}_{n}^{T}=y_{n}\left[\begin{array}{ll} 1 & \mathbf{x}_{n}^{T} \end{array}\right] ; c_{n}=1 ; M=N
u = [ b w ] ; Q = [ 0 0 d 0 d T I d ] ; p = 0 d + 1 a n T = y n [ 1 x n T ] ; c n = 1 ; M = N
[
b
w
]
←
Q
P
(
Q
,
p
,
A
,
c
)
\left[\begin{array}{l}b \\ w\end{array}\right] \leftarrow Q P(Q, p, A, c)
[ b w ] ← Q P ( Q , p , A , c ) return
b
&
w
b\,\& \,w
b & w
g
s
v
m
g_{\mathbf{svm}}
g s v m
以二维平面为例求取支持向量机:
假设样本的分布为:
X
=
[
0
0
2
2
2
0
3
0
]
y
=
[
−
1
−
1
+
1
+
1
]
−
b
≥
1
(
i
)
−
2
w
1
−
2
w
2
−
b
≥
1
(
i
i
)
2
w
1
+
b
≥
1
(
i
i
i
)
3
w
1
+
b
≥
1
(
i
v
)
X=\left[\begin{array}{ll} 0 & 0 \\ 2 & 2 \\ 2 & 0 \\ 3 & 0 \end{array}\right] \quad y=\left[\begin{array}{l} -1 \\ -1 \\ +1 \\ +1 \end{array}\right] \quad \begin{aligned} &-b \geq 1 &(i)\\ -2 w_{1}-2 w_{2}& - b \geq 1&(ii) \\ 2 w_{1} \quad \quad \quad &+b \geq 1 &(iii)\\ 3 w_{1} \quad \quad \quad &+b \geq 1 &(iv) \end{aligned}
X = ⎣ ⎢ ⎢ ⎡ 0 2 2 3 0 2 0 0 ⎦ ⎥ ⎥ ⎤ y = ⎣ ⎢ ⎢ ⎡ − 1 − 1 + 1 + 1 ⎦ ⎥ ⎥ ⎤ − 2 w 1 − 2 w 2 2 w 1 3 w 1 − b ≥ 1 − b ≥ 1 + b ≥ 1 + b ≥ 1 ( i ) ( i i ) ( i i i ) ( i v )
可以求解的:
g
s
v
m
(
x
)
=
sign
(
x
1
−
x
2
−
1
)
g_{\mathrm{svm}}(\mathbf{x})=\operatorname{sign}\left(x_{1}-x_{2}-1\right)
g s v m ( x ) = s i g n ( x 1 − x 2 − 1 )
示意图如下:
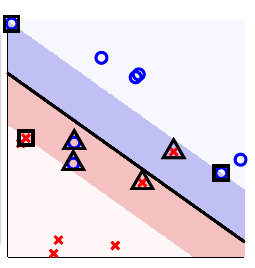
写到这里肯定会想到,采用最大间隔的超平面的意义是什么?
minimize
constraint
regularization
E
in
w
T
w
≤
C
SVM
w
T
w
E
in
=
0
[and more]
\begin{array}{c|c|c} & \text { minimize } & \text { constraint } \\ \hline \text { regularization } & E_{\text {in }} & \mathbf{w}^{T} \mathbf{w} \leq C \\ \hline \text { SVM } & \mathbf{w}^{T} \mathbf{w} & E_{\text {in }}=0 \text { [and more] } \end{array}
regularization SVM minimize E in w T w constraint w T w ≤ C E in = 0 [and more]
可见实际上线性支持向量机(Linear SVM)是一种以
E
in
=
0
E_{\text {in }}=0
E in = 0
SVM 可以理解为一种大间隔算法(large-margin algorithm)
A
ρ
\mathcal{A}_{\rho}
A ρ
g
g
g
margin
(
g
)
≥
ρ
\operatorname{margin}(g) \geq \rho
m a r g i n ( g ) ≥ ρ
当间隔不断扩大时,有些可以 shatter 的情况会因为在间隔内而不能 shatter。
当
ρ
=
0
\rho = 0
ρ = 0
ρ
=
1.126
\rho = 1.126
ρ = 1 . 1 2 6
⇒
\Rightarrow
⇒
⇒
\Rightarrow
⇒
下面列举以下原来所求取的模型的特点与大间隔超平面算法做对比:
large-margin
hyperplanes
hyperplanes
hyperplanes
+
feature transform
Φ
#
even fewer
not many
many
boundary
simple
simple
sophisticated
\begin{array}{c|c|c|c} & \begin{array}{c} \text { large-margin } \\ \text { hyperplanes } \end{array} & \text { hyperplanes } & \begin{array}{c} \text { hyperplanes } \\ +\text { feature transform } \Phi \end{array} \\ \hline \# & \text { even fewer } & \text { not many } & \text { many } \\ \hline \text { boundary } & \text { simple } & \text { simple } & \text { sophisticated } \end{array}
# boundary large-margin hyperplanes even fewer simple hyperplanes not many simple hyperplanes + feature transform Φ many sophisticated
#
\#
#
H
\mathcal{H}
H
H
\mathcal{H}
H
large-margin
hyperplanes
+
numerous feature transform
Φ
#
not many
boundary
sophisticated
\begin{array}{c|c} & \text { large-margin } \\ & \text { hyperplanes } \\ & +\text { numerous feature transform } \Phi \\ \hline \# & \text { not many } \\ \hline \text { boundary } & \text { sophisticated } \end{array}
# boundary large-margin hyperplanes + numerous feature transform Φ not many sophisticated
H
\mathcal{H}
H
经过非线性转换后最优化问题变为:
min
b
,
w
1
2
w
T
w
s.t.
y
n
(
w
T
z
n
⏟
Φ
(
x
n
)
+
b
)
≥
1
for
n
=
1
,
2
,
…
,
N
\begin{array}{ll} \min _{b, w} & \frac{1}{2} \mathbf{w}^{T} \mathbf{w} \\ \text { s.t. } & y_{n}(\mathbf{w}^{T} \underbrace{\mathbf{z}_{n}}_{\Phi\left(\mathbf{x}_{n}\right)}+b) \geq 1 \\ & \text { for } n=1,2, \ldots, N \end{array}
min b , w s.t. 2 1 w T w y n ( w T Φ ( x n )
z n + b ) ≥ 1 for n = 1 , 2 , … , N
实现步骤转换为:
u
=
[
b
w
]
;
Q
=
[
0
0
d
~
T
0
d
~
I
d
~
]
;
p
=
0
d
~
+
1
a
n
T
=
y
n
[
1
z
n
T
]
;
c
n
=
1
;
M
=
N
\begin{aligned} \mathbf{u}=\left[\begin{array}{l} b \\ \mathbf{w} \end{array}\right] ; Q=\left[\begin{array}{ll} 0 & \mathbf{0}_{\tilde{d}}^{T} \\ \mathbf{0}_{\tilde{d}} & \mathrm{I}_{\tilde{d}} \end{array}\right] ; \mathbf{p}=0_{\tilde{d}+1} \mathbf{a}_{n}^{T}=y_{n}\left[\begin{array}{ll} 1 & \mathbf{z}_{n}^{T} \end{array}\right] ; c_{n}=1 ; M=N \end{aligned}
u = [ b w ] ; Q = [ 0 0 d ~ 0 d ~ T I d ~ ] ; p = 0 d ~ + 1 a n T = y n [ 1 z n T ] ; c n = 1 ; M = N
[
b
w
]
←
Q
P
(
Q
,
p
,
A
,
c
)
\left[\begin{array}{l}b \\ w\end{array}\right] \leftarrow Q P(Q, p, A, c)
[ b w ] ← Q P ( Q , p , A , c )
return
b
∈
R
&
w
∈
R
d
with
g
s
v
m
(
x
)
=
sign
(
w
T
Φ
(
x
)
+
b
)
\text { return } b \in \mathbb{R} \, \& \, \mathrm{w} \in \mathbb{R}^{d} \text { with }g_{\mathrm{svm}}(\mathbf{x})=\operatorname{sign}\left(\mathbf{w}^{T} \mathbf{\Phi}(\mathbf{x})+b\right)
return b ∈ R & w ∈ R d with g s v m ( x ) = s i g n ( w T Φ ( x ) + b )
但是可以明显看出随着
Φ
(
x
)
\mathbf{\Phi}(\mathbf{x})
Φ ( x )
d
~
{\tilde{d}}
d ~
在使用核技术之前需要先将支持向量机转换为对偶问题。
首先将其转换为无约束最优化问题:写出其拉格朗日方程(Lagrange Function),其中
α
n
\alpha_{n}
α n
L
(
b
,
w
,
α
)
=
1
2
w
T
w
⏟
objective
+
∑
n
=
1
N
α
n
(
1
−
y
n
(
w
T
z
n
+
b
)
⏟
constraint
)
\mathcal{L}(b, \mathbf{w}, \alpha)= \underbrace{\frac{1}{2} \mathbf{w}^{T} \mathbf{w}}_{\text {objective }}+\sum_{n=1}^{N} \alpha_{n}(\underbrace{1-y_{n}\left(\mathbf{w}^{T} \mathbf{z}_{n}+b\right)}_{\text {constraint }})
L ( b , w , α ) = objective
2 1 w T w + n = 1 ∑ N α n ( constraint
1 − y n ( w T z n + b ) )
那么 SVM 的等价问题可写为:
S
V
M
≡
min
b
,
w
(
max
all
α
n
≥
0
L
(
b
,
w
,
α
)
)
\mathrm{SVM} \equiv \min_{b, \mathrm{w}}\left(\max _{\text{all } \alpha_{n} \geq 0} \mathcal{L}(b, \mathbf{w}, \alpha)\right)
S V M ≡ b , w min ( all α n ≥ 0 max L ( b , w , α ) )
其中对于
(
b
,
w
)
(b, \mathbf{w})
( b , w )
max
all
α
n
≥
0
(
□
+
∑
n
α
n
(
some positive
)
)
→
∞
\max _{\text {all } \alpha_{n} \geq 0}\left(\square+\sum_{n} \alpha_{n}(\text { some positive })\right) \rightarrow \infty
all α n ≥ 0 max ( □ + n ∑ α n ( some positive ) ) → ∞
这是因为求取最大值的操作,在 constraint 部分为 positive 时,
α
n
\alpha_{n}
α n
其中对于
(
b
,
w
)
(b, \mathbf{w})
( b , w )
max
all
α
n
≥
0
(
□
+
∑
n
α
n
(
all non-positive
)
)
=
□
\max _{\text {all } \alpha_{n} \geq 0}\left(\square+\sum_{n} \alpha_{n}(\text { all non-positive })\right)=\square
all α n ≥ 0 max ( □ + n ∑ α n ( all non-positive ) ) = □
这是因为求取最大值的操作,在 constraint 部分为 negative 时,
α
n
\alpha_{n}
α n
那么 SVM 的等价问题可进一步写为:
S
V
M
=
min
b
,
w
(
∞
if violate
;
1
2
w
T
w
if feasible
)
\mathrm{SVM} = \min _{b, \mathrm{w}}\left(\infty \text { if violate } ; \frac{1}{2} \mathrm{w}^{T} \mathrm{w} \text { if feasible }\right)
S V M = b , w min ( ∞ if violate ; 2 1 w T w if feasible )
对于任何一个
α
n
′
≥
0
\alpha_{n}^{\prime} \geq 0
α n ′ ≥ 0
α
′
\alpha^{\prime}
α ′
min
b
,
w
(
max
all
α
n
≥
0
L
(
b
,
w
,
α
)
)
≥
min
b
,
w
L
(
b
,
w
,
α
′
)
\min _{b, \mathbf{w}}\left(\max _{\text {all } \alpha_{n} \geq 0} \mathcal{L}(b, \mathbf{w}, \boldsymbol{\alpha})\right) \geq \min _{b, \mathbf{w}} \mathcal{L}\left(b, \mathbf{w}, \alpha^{\prime}\right)
b , w min ( all α n ≥ 0 max L ( b , w , α ) ) ≥ b , w min L ( b , w , α ′ )
≥
\geq
≥
min
b
,
w
(
max
all
α
n
≥
0
L
(
b
,
w
,
α
)
)
⏟
equiv. to original (primal) SVM
≥
max
all
α
n
≥
0
(
min
b
,
w
L
(
b
,
w
,
α
′
)
)
⏟
Lagrange dual problem
\underbrace{\min _{b, w}\left(\max _{\text {all } \alpha_{n} \geq 0} \mathcal{L}(b, \mathbf{w}, \alpha)\right)}_{\text{equiv. to original (primal) SVM}} \geq \underbrace{\max _{\text {all } \alpha_{n} \geq 0} \left( \min _{b, w} \mathcal{L}\left(b, \mathbf{w}, \alpha^{\prime}\right)\right)}_{\text {Lagrange dual problem }}
equiv. to original (primal) SVM
b , w min ( all α n ≥ 0 max L ( b , w , α ) ) ≥ Lagrange dual problem
all α n ≥ 0 max ( b , w min L ( b , w , α ′ ) )
在上述公式中:
如果是
≤
\leq
≤
=
=
=
原问题的凸的
原问题是可行的(是
Φ
\Phi
Φ
线性约束
拉格朗日的对偶问题:实际上就是求原问题下界的最大值。
所以说线性支持向量机是存在对偶最优解的。
对偶问题的显式为:
max
all
α
n
≥
0
(
min
b
,
w
1
2
w
T
w
+
∑
n
=
1
N
α
n
(
1
−
y
n
(
w
T
z
n
+
b
)
)
⏟
L
(
b
,
w
,
α
)
)
\max _{\text {all } \alpha_{n} \geq 0}\left(\min _{b, w} \underbrace{\frac{1}{2} \mathbf{w}^{T} \mathbf{w}+\sum_{n=1}^{N} \alpha_{n}\left(1-y_{n}\left(\mathbf{w}^{T} \mathbf{z}_{n}+b\right)\right)}_{\mathcal{L}(b, \mathbf{w}, \alpha)}\right)
all α n ≥ 0 max ⎝ ⎜ ⎜ ⎜ ⎜ ⎛ b , w min L ( b , w , α )
2 1 w T w + n = 1 ∑ N α n ( 1 − y n ( w T z n + b ) ) ⎠ ⎟ ⎟ ⎟ ⎟ ⎞
由于里面优化问题为无约束最优化问题,所以其最优解满足:
∂
L
(
b
,
w
,
α
)
∂
b
=
0
=
−
∑
n
=
1
N
α
n
y
n
\frac{\partial \mathcal{L}(b, \mathbf{w}, \alpha)}{\partial b}=0=-\sum_{n=1}^{N} \alpha_{n} y_{n}
∂ b ∂ L ( b , w , α ) = 0 = − n = 1 ∑ N α n y n
max
all
α
n
≥
0
(
min
b
,
w
1
2
w
T
w
+
∑
n
=
1
N
α
n
(
1
−
y
n
(
w
T
z
n
+
b
)
)
)
⇒
max
all
α
n
≥
0
(
min
b
,
w
1
2
w
T
w
+
∑
n
=
1
N
α
n
(
1
−
y
n
(
w
T
z
n
)
)
+
∑
n
=
1
N
α
n
y
n
⋅
b
)
⟹
∑
n
=
1
N
α
n
y
n
=
0
max
all
α
n
≥
0
,
∑
y
n
α
n
=
0
(
min
b
,
w
1
2
w
T
w
+
∑
n
=
1
N
α
n
(
1
−
y
n
(
w
T
z
n
)
)
)
\max _{\text {all } \alpha_{n} \geq 0}\left(\min _{b, w} {\frac{1}{2} \mathbf{w}^{T} \mathbf{w}+\sum_{n=1}^{N} \alpha_{n}\left(1-y_{n}\left(\mathbf{w}^{T} \mathbf{z}_{n}+b\right)\right)}\right) \\ \Rightarrow \max _{\text {all } \alpha_{n} \geq 0}\left(\min _{b, w} {\frac{1}{2} \mathbf{w}^{T} \mathbf{w}+\sum_{n=1}^{N} \alpha_{n}\left(1-y_{n}\left(\mathbf{w}^{T} \mathbf{z}_{n}\right)\right) + \sum_{n=1}^{N} \alpha_{n} y_{n} \cdot b}\right) \\ {\mathop {\Longrightarrow}\limits^{\sum_{n=1}^{N} \alpha_{n} y_{n} = 0} \max _{\text {all } \alpha_{n} \geq 0, \sum y_{n} \alpha_{n}=0}\left(\min _{b, \mathbf{w}} \frac{1}{2} \mathbf{w}^{T} \mathbf{w}+\sum_{n=1}^{N} \alpha_{n}\left(1-y_{n}\left(\mathbf{w}^{T} \mathbf{z}_{n}\right)\right)\right)}\\
all α n ≥ 0 max ( b , w min 2 1 w T w + n = 1 ∑ N α n ( 1 − y n ( w T z n + b ) ) ) ⇒ all α n ≥ 0 max ( b , w min 2 1 w T w + n = 1 ∑ N α n ( 1 − y n ( w T z n ) ) + n = 1 ∑ N α n y n ⋅ b ) ⟹ ∑ n = 1 N α n y n = 0 all α n ≥ 0 , ∑ y n α n = 0 max ( b , w min 2 1 w T w + n = 1 ∑ N α n ( 1 − y n ( w T z n ) ) )
由于里面优化问题为无约束最优化问题,所以其最优解同时也满足:
∂
L
(
b
,
w
,
α
)
∂
w
i
=
0
=
w
i
−
∑
n
=
1
N
α
n
y
n
z
n
,
i
⇒
w
=
∑
n
=
1
N
α
n
y
n
z
n
\frac{\partial \mathcal{L}(b, w, \alpha)}{\partial w_{i}}=0=w_{i}-\sum_{n=1}^{N} \alpha_{n} y_{n} z_{n, i} \Rightarrow \mathbf{w}=\sum_{n=1}^{N} \alpha_{n} y_{n} \mathbf{z}_{n}
∂ w i ∂ L ( b , w , α ) = 0 = w i − n = 1 ∑ N α n y n z n , i ⇒ w = n = 1 ∑ N α n y n z n
max
all
α
n
≥
0
,
∑
y
n
α
n
=
0
,
w
=
∑
α
n
y
n
z
n
(
min
b
,
w
1
2
w
T
w
+
∑
n
=
1
N
α
n
−
w
T
w
)
⟺
max
all
α
n
≥
0
,
∑
y
n
α
n
=
0
,
w
=
∑
α
n
y
n
z
n
−
1
2
∥
∑
n
=
1
N
α
n
y
n
z
n
∥
2
+
∑
n
=
1
N
α
n
\begin{array}{ll} &\max\limits_{ \text { all } \alpha_{n} \geq 0, \sum y_{n} \alpha_{n}=0, \mathbf{w}=\sum \alpha_{n} y_{n} z_{n}}\left(\min _{b, w} \frac{1}{2} \mathbf{w}^{T} \mathbf{w}+\sum_{n=1}^{N} \alpha_{n}-\mathbf{w}^{T} \mathbf{w}\right) \\ \Longleftrightarrow &\max\limits_{ \text { all } \alpha_{n} \geq 0, \sum y_{n} \alpha_{n}=0, \mathbf{w}=\sum \alpha_{n} y_{n} z_{n}}-\frac{1}{2}\left\|\sum_{n=1}^{N} \alpha_{n} y_{n} \mathbf{z}_{n}\right\|^{2}+\sum_{n=1}^{N} \alpha_{n} \end{array}
⟺ all α n ≥ 0 , ∑ y n α n = 0 , w = ∑ α n y n z n max ( min b , w 2 1 w T w + ∑ n = 1 N α n − w T w ) all α n ≥ 0 , ∑ y n α n = 0 , w = ∑ α n y n z n max − 2 1 ∥ ∥ ∥ ∑ n = 1 N α n y n z n ∥ ∥ ∥ 2 + ∑ n = 1 N α n
KKT条件是对偶问题的优化的充要条件:
原问题的可行条件:
y
n
(
w
T
z
n
+
b
)
≥
1
y_{n}\left(\mathbf{w}^{T} \mathbf{z}_{n}+b\right) \geq 1
y n ( w T z n + b ) ≥ 1
对偶问题的可行条件:
α
n
≥
0
\alpha_{n} \geq 0
α n ≥ 0
对偶问题的内部最小化问题的最优条件:
∑
y
n
α
n
=
0
;
w
=
∑
α
n
y
n
z
n
\sum y_{n} \alpha_{n}=0 ; \mathbf{w}=\sum \alpha_{n} y_{n} \mathbf{z}_{n}
∑ y n α n = 0 ; w = ∑ α n y n z n
原问题的内部最大化问题的最优条件:
α
n
(
1
−
y
n
(
w
T
z
n
+
b
)
)
=
0
\alpha_{n}\left(1-y_{n}\left(\mathbf{w}^{T} \mathbf{z}_{n}+b\right)\right)=0
α n ( 1 − y n ( w T z n + b ) ) = 0
现在可以通过最优化
α
\alpha
α
(
b
,
w
)
(b,\mathbf{w})
( b , w )
α
\alpha
α
min
α
1
2
∑
n
=
1
N
∑
m
=
1
N
α
n
α
m
y
n
y
m
z
n
T
z
m
−
∑
n
=
1
N
α
n
subject to
∑
n
=
1
N
y
n
α
n
=
0
α
n
≥
0
,
for
n
=
1
,
2
,
…
,
N
\begin{aligned} \min _{\alpha} \quad & \frac{1}{2} \sum_{n=1}^{N} \sum_{m=1}^{N} \alpha_{n} \alpha_{m} y_{n} y_{m} \mathbf{z}_{n}^{T} \mathbf{z}_{m}-\sum_{n=1}^{N} \alpha_{n} \\ \text {subject to} \quad & \sum_{n=1}^{N} y_{n} \alpha_{n}=0 \\ & \alpha_{n} \geq 0, \text { for } n=1,2, \ldots, N \end{aligned}
α min subject to 2 1 n = 1 ∑ N m = 1 ∑ N α n α m y n y m z n T z m − n = 1 ∑ N α n n = 1 ∑ N y n α n = 0 α n ≥ 0 , for n = 1 , 2 , … , N
可以看出这里有:
N
N
N
α
n
\alpha_n
α n
N
+
1
N + 1
N + 1
转换为经典的 QP 问题
min
α
1
2
α
T
Q
α
+
p
T
α
subject to
a
i
T
α
≥
c
i
for
i
=
1
,
2
,
…
⏟
A
T
α
≥
C
\begin{aligned} \min _{\alpha} \quad & \frac{1}{2} \alpha^{T} Q \alpha+p^{T} \alpha \\ \text{subject to } \quad & \underbrace{\mathbf{a}_{i}^{T} \boldsymbol{\alpha} \geq c_{i} \quad \text{for } i=1,2, \ldots}_{A^{T} \alpha \geq C} \end{aligned}
α min subject to 2 1 α T Q α + p T α A T α ≥ C
a i T α ≥ c i for i = 1 , 2 , …
q
n
,
m
=
y
n
y
m
z
n
T
z
m
q_{n, m}=y_{n} y_{m} \mathbf{z}_{n}^{T} \mathbf{z}_{m}
q n , m = y n y m z n T z m
p
=
−
1
N
×
1
\mathbf{p}=-\mathbf{1}_{N \times 1}
p = − 1 N × 1
a
≥
=
y
,
a
≤
=
−
y
,
a
n
T
=
n
\mathbf{a}_{\geq}=\mathbf{y}, \mathbf{a}_{\leq}=-\mathbf{y},\mathbf{a}_{n}^{T}=n
a ≥ = y , a ≤ = − y , a n T = n
⇒
A
=
[
a
≥
,
a
≤
,
a
n
]
\Rightarrow A = \left[a_{\geq},a_{\leq} ,a_{n} \right]
⇒ A = [ a ≥ , a ≤ , a n ]
c
≥
=
0
,
c
≤
=
0
;
c
n
=
0
⇒
c
=
[
c
≥
,
c
≤
,
c
n
]
c_{\geq}=0, c_{\leq}=0 ; c_{n}=0 \Rightarrow c=\left[c_{\geq},c_{\leq} ,c_{n} \right]
c ≥ = 0 , c ≤ = 0 ; c n = 0 ⇒ c = [ c ≥ , c ≤ , c n ]
(
b
,
w
)
(b,\mathbf{w})
( b , w ) 根据KKT条件中的第三条:
w
=
∑
α
n
y
n
z
n
\mathbf{w}=\sum \alpha_{n} y_{n} \mathbf{z}_{n}
w = ∑ α n y n z n
根据KKT条件中的第四条:找出
α
n
>
0
\alpha_{n}>0
α n > 0
b
=
y
n
−
w
T
z
n
b=y_{n}-\mathbf{w}^{T} \mathbf{z}_{n}
b = y n − w T z n
⇒
\Rightarrow
⇒
α
n
>
0
\alpha_{n}>0
α n > 0
α
n
=
0
\alpha_{n}=0
α n = 0
n
n
n
w
n
=
0
w_n = 0
w n = 0
y
n
b
≥
1
y_{n}b \geq 1
y n b ≥ 1
b
b
b
值得注意的是:与 PLA 通过错误点校正相仿,SVM只通过支持向量进行校正。
在前文中虽然可以看出将问题转变为 在
N
+
1
N + 1
N + 1
N
N
N
α
n
\alpha_n
α n
q
n
,
m
=
y
n
y
m
z
n
T
z
m
q_{n, m}=y_{n} y_{m} \mathbf{z}_{n}^{T} \mathbf{z}_{m}
q n , m = y n y m z n T z m
d
~
\tilde d
d ~
z
m
\mathbf{z}_{m}
z m
z
n
\mathbf{z}_{n}
z n
以
Φ
2
\Phi_{2}
Φ 2
Φ
2
\Phi_{2}
Φ 2
Φ
2
(
x
)
=
(
1
,
x
1
,
x
2
,
…
,
x
d
,
x
1
2
,
x
1
x
2
,
…
,
x
1
x
d
,
x
2
x
1
,
x
2
2
,
…
,
x
2
x
d
,
…
,
x
d
2
)
\Phi_{2}(\mathbf{x})=\left(1, x_{1}, x_{2}, \ldots, x_{d}, x_{1}^{2}, x_{1} x_{2}, \ldots, x_{1} x_{d}, x_{2} x_{1}, x_{2}^{2}, \ldots, x_{2} x_{d}, \ldots, x_{d}^{2}\right)
Φ 2 ( x ) = ( 1 , x 1 , x 2 , … , x d , x 1 2 , x 1 x 2 , … , x 1 x d , x 2 x 1 , x 2 2 , … , x 2 x d , … , x d 2 )
其内积可以转换为:
Φ
2
(
x
)
T
Φ
2
(
x
′
)
=
1
+
∑
i
=
1
d
x
i
x
i
′
+
∑
i
=
1
d
∑
j
=
1
d
x
i
x
j
x
i
′
x
j
′
=
1
+
∑
i
=
1
d
x
i
x
i
′
+
∑
i
=
1
d
x
i
x
i
′
∑
j
=
1
d
x
j
x
j
′
=
1
+
x
T
x
′
+
(
x
T
x
′
)
(
x
T
x
′
)
\begin{aligned} \Phi_{2}(\mathrm{x})^{T} \Phi_{2}\left(\mathrm{x}^{\prime}\right) &=1+\sum_{i=1}^{d} x_{i} x_{i}^{\prime}+\sum_{i=1}^{d} \sum_{j=1}^{d} x_{i} x_{j} x_{i}^{\prime} x_{j}^{\prime} \\ &=1+\sum_{i=1}^{d} x_{i} x_{i}^{\prime}+\sum_{i=1}^{d} x_{i} x_{i}^{\prime} \sum_{j=1}^{d} x_{j} x_{j}^{\prime} \\ &=1+\mathrm{x}^{T} \mathrm{x}^{\prime}+\left(\mathrm{x}^{T} \mathrm{x}^{\prime}\right)\left(\mathrm{x}^{T} \mathrm{x}^{\prime}\right) \end{aligned}
Φ 2 ( x ) T Φ 2 ( x ′ ) = 1 + i = 1 ∑ d x i x i ′ + i = 1 ∑ d j = 1 ∑ d x i x j x i ′ x j ′ = 1 + i = 1 ∑ d x i x i ′ + i = 1 ∑ d x i x i ′ j = 1 ∑ d x j x j ′ = 1 + x T x ′ + ( x T x ′ ) ( x T x ′ )
即
Φ
2
\Phi_{2}
Φ 2
O
(
d
)
O(d)
O ( d )
O
(
d
2
)
O(d^2)
O ( d 2 )
至此给出定义 :Kernel = Transform + Inner Product。即 transform
Φ
⟺
\Phi \Longleftrightarrow
Φ ⟺
K
Φ
(
x
,
x
′
)
≡
Φ
(
x
)
T
Φ
(
x
′
)
K_{\Phi}\left(\mathbf{x}, \mathbf{x}^{\prime}\right) \equiv \Phi(\mathbf{x})^{T} \mathbf{\Phi}\left(\mathbf{x}^{\prime}\right)
K Φ ( x , x ′ ) ≡ Φ ( x ) T Φ ( x ′ )
那么二阶多项式转换的核函数可写为:
Φ
2
⟺
K
Φ
2
(
x
,
x
′
)
=
1
+
(
x
T
x
′
)
+
(
x
T
x
′
)
2
\Phi_{2} \Longleftrightarrow K_{\Phi_{2}}\left(\mathbf{x}, \mathbf{x}^{\prime}\right)=1+\left(\mathbf{x}^{T} \mathbf{x}^{\prime}\right)+\left(\mathbf{x}^{T} \mathbf{x}^{\prime}\right)^{2}
Φ 2 ⟺ K Φ 2 ( x , x ′ ) = 1 + ( x T x ′ ) + ( x T x ′ ) 2
至此可以将QP问题中涉及转换后内积求解的部分全部转换:
二次项系数
q
n
,
m
=
y
n
y
m
z
n
T
z
m
=
y
n
y
m
K
(
x
n
,
x
m
)
q_{n, m}=y_{n} y_{m} \mathbf{z}_{n}^{T} \mathbf{z}_{m}=y_{n} y_{m} K\left(\mathbf{x}_{n}, \mathbf{x}_{m}\right)
q n , m = y n y m z n T z m = y n y m K ( x n , x m )
最佳偏差系数
b
b
b
S
V
(
x
s
,
y
s
)
\mathrm{SV}\left(\mathrm{x}_{s}, y_{s}\right)
S V ( x s , y s )
b
=
y
s
−
w
T
z
s
=
y
s
−
(
∑
n
=
1
N
α
n
y
n
z
n
)
T
z
s
=
y
s
−
∑
n
=
1
N
α
n
y
n
(
K
(
x
n
,
x
s
)
)
b=y_{s}-\mathbf{w}^{T} \mathbf{z}_{s}=y_{s}-\left(\sum_{n=1}^{N} \alpha_{n} y_{n} \mathbf{z}_{n}\right)^{T} \mathbf{z}_{s}=y_{s}-\sum_{n=1}^{N} \alpha_{n} y_{n}\left(K\left(\mathbf{x}_{n}, \mathbf{x}_{s}\right)\right)
b = y s − w T z s = y s − ( n = 1 ∑ N α n y n z n ) T z s = y s − n = 1 ∑ N α n y n ( K ( x n , x s ) )
最佳假设函数
g
svm
g_{\text {svm }}
g svm
x
\mathbf{x}
x
g
s
v
m
(
x
)
=
sign
(
w
T
Φ
(
x
)
+
b
)
=
sign
(
∑
n
=
1
N
α
n
y
n
K
(
x
n
,
x
)
+
b
)
g_{\mathrm{svm}}(\mathrm{x})=\operatorname{sign}\left(\mathbf{w}^{T} \Phi(\mathbf{x})+b\right)=\operatorname{sign}\left(\sum_{n=1}^{N} \alpha_{n} y_{n} K\left(\mathbf{x}_{n}, \mathbf{x}\right)+b\right)
g s v m ( x ) = s i g n ( w T Φ ( x ) + b ) = s i g n ( n = 1 ∑ N α n y n K ( x n , x ) + b )
所以核技巧使用有效的和函数,避免了在
d
~
\tilde d
d ~
核支持向量机的具体实现步骤为:
q
n
,
m
=
y
n
y
m
K
(
x
n
,
x
m
)
;
p
=
−
1
N
;
(
A
,
c
)
q_{n, m}=y_{n} y_{m} K\left(\mathbf{x}_{n}, \mathbf{x}_{m}\right) ; \mathbf{p}=-\mathbf{1}_{N} ;(\mathrm{A}, \mathbf{c})
q n , m = y n y m K ( x n , x m ) ; p = − 1 N ; ( A , c )
α
←
Q
P
(
Q
D
,
p
,
A
,
c
)
\alpha \leftarrow \mathrm{QP}\left(\mathrm{Q}_{\mathrm{D}}, \mathrm{p}, \mathrm{A}, \mathrm{c}\right)
α ← Q P ( Q D , p , A , c )
b
←
(
y
s
−
∑
SV indices
n
α
n
y
n
K
(
x
n
,
x
s
)
)
with
S
V
(
x
s
,
y
s
)
b \leftarrow\left(y_{s}-\sum\limits_{\text {SV indices } n} \alpha_{n} y_{n} K\left(\mathrm{x}_{n}, \mathrm{x}_{s}\right)\right) \text { with } \mathrm{SV}\left(\mathrm{x}_{s}, y_{s}\right)
b ← ( y s − SV indices n ∑ α n y n K ( x n , x s ) ) with S V ( x s , y s ) return SVs and their
α
n
\alpha_{n}
α n
b
b
b
x
\mathbf{x}
x
g
s
v
m
(
x
)
=
sign
(
∑
SV indices
n
α
n
y
n
K
(
x
n
,
x
)
+
b
)
g_{\mathrm{svm}}(\mathbf{x})=\operatorname{sign}\left(\underset{\text { SV indices } n}{\sum} \alpha_{n} y_{n} K\left(\mathbf{x}_{n}, \mathbf{x}\right)+b\right)
g s v m ( x ) = s i g n ( SV indices n ∑ α n y n K ( x n , x ) + b )
时间复杂度分析:
上述第一步中每一个
q
n
,
m
=
y
n
y
m
K
(
x
n
,
x
m
)
q_{n, m}=y_{n} y_{m} K\left(\mathbf{x}_{n}, \mathbf{x}_{m}\right)
q n , m = y n y m K ( x n , x m )
Q
D
\mathrm{Q}_{\mathrm{D}}
Q D
N
2
N^2
N 2
O
(
N
2
)
⋅
(
kernel evaluation
)
O(N^2) \cdot (\text{kernel evaluation})
O ( N 2 ) ⋅ ( kernel evaluation )
上述第二步中的时间复杂度为带有
N
N
N
N
+
1
N+1
N + 1
上述第三步和第四步的时间复杂度为
O
(
#
S
V
)
⋅
(
kernel evaluation
)
O(\#SV) \cdot (\text{kernel evaluation})
O ( # S V ) ⋅ ( kernel evaluation )
#
S
V
\#SV
# S V
所以实际上核支持向量机是使用计算技巧避免了依赖于映射空间维度
d
~
\tilde d
d ~ 支持向量进行预测。
在原来的
Φ
2
\Phi_{2}
Φ 2
Φ
2
(
x
)
=
(
1
,
2
x
1
,
…
,
2
x
d
,
x
1
2
,
…
,
x
d
2
)
⇔
K
2
(
x
,
x
′
)
=
1
+
2
x
T
x
′
+
(
x
T
x
′
)
2
\Phi_{2}(\mathbf{x})=\left(1, \sqrt{2} x_{1}, \ldots, \sqrt{2} x_{d}, x_{1}^{2}, \ldots, x_{d}^{2}\right) \\ \Leftrightarrow K_{2}\left(\mathbf{x}, \mathbf{x}^{\prime}\right)=1+2 \mathbf{x}^{T} \mathbf{x}^{\prime}+\left(\mathbf{x}^{T} \mathbf{x}^{\prime}\right)^{2}
Φ 2 ( x ) = ( 1 , 2
x 1 , … , 2
x d , x 1 2 , … , x d 2 ) ⇔ K 2 ( x , x ′ ) = 1 + 2 x T x ′ + ( x T x ′ ) 2
Φ
2
(
x
)
=
(
1
,
2
γ
x
1
,
…
,
2
γ
x
d
,
γ
x
1
2
,
…
,
γ
x
d
2
)
⇔
K
2
(
x
,
x
′
)
=
1
+
2
γ
x
T
x
′
+
γ
2
(
x
T
x
′
)
2
\Phi_{2}(\mathbf{x})=\left(1, \sqrt{2 \gamma} x_{1}, \ldots, \sqrt{2 \gamma} x_{d}, \gamma x_{1}^{2}, \ldots, \gamma x_{d}^{2}\right) \\ \Leftrightarrow K_{2}\left(\mathbf{x}, \mathbf{x}^{\prime}\right)=1+2 \gamma \mathbf{x}^{T} \mathbf{x}^{\prime}+\gamma^{2}\left(\mathbf{x}^{T} \mathbf{x}^{\prime}\right)^{2}
Φ 2 ( x ) = ( 1 , 2 γ
x 1 , … , 2 γ
x d , γ x 1 2 , … , γ x d 2 ) ⇔ K 2 ( x , x ′ ) = 1 + 2 γ x T x ′ + γ 2 ( x T x ′ ) 2
K
2
(
x
,
x
′
)
=
(
1
+
γ
x
T
x
′
)
2
with
γ
>
0
K_{2}\left(\mathbf{x}, \mathbf{x}^{\prime}\right)=\left(1+\gamma \mathbf{x}^{T} \mathbf{x}^{\prime}\right)^{2} \text { with } \gamma>0
K 2 ( x , x ′ ) = ( 1 + γ x T x ′ ) 2 with γ > 0
虽然随着
γ
\gamma
γ power是一样的,但是其内积不同,也就是几何定义中的距离不同。
那么据此可以写出通用的多项式核(General Polynomial Kernel):
K
1
(
x
,
x
′
)
=
(
0
+
1
⋅
x
T
x
′
)
1
K
2
(
x
,
x
′
)
=
(
ζ
+
γ
x
T
x
′
)
2
with
γ
>
0
,
ζ
≥
0
K
3
(
x
,
x
′
)
=
(
ζ
+
γ
x
T
x
′
)
3
with
γ
>
0
,
ζ
≥
0
⋮
K
Q
(
x
,
x
′
)
=
(
ζ
+
γ
x
T
x
′
)
Q
with
γ
>
0
,
ζ
≥
0
\begin{aligned} K_{1}\left(\mathbf{x}, \mathbf{x}^{\prime}\right) &=\left(0+1 \cdot \mathbf{x}^{T} \mathbf{x}^{\prime}\right)^{1} \\ K_{2}\left(\mathbf{x}, \mathbf{x}^{\prime}\right) &=\left(\zeta+\gamma \mathbf{x}^{T} \mathbf{x}^{\prime}\right)^{2} \text { with } \gamma>0, \zeta \geq 0 \\ K_{3}\left(\mathbf{x}, \mathbf{x}^{\prime}\right) &=\left(\zeta+\gamma \mathbf{x}^{T} \mathbf{x}^{\prime}\right)^{3} \text { with } \gamma>0, \zeta \geq 0 \\ & \vdots \\ K_{Q}\left(\mathbf{x}, \mathbf{x}^{\prime}\right) &=\left(\zeta+\gamma \mathbf{x}^{T} \mathbf{x}^{\prime}\right)^{Q} \text { with } \gamma>0, \zeta \geq 0 \end{aligned}
K 1 ( x , x ′ ) K 2 ( x , x ′ ) K 3 ( x , x ′ ) K Q ( x , x ′ ) = ( 0 + 1 ⋅ x T x ′ ) 1 = ( ζ + γ x T x ′ ) 2 with γ > 0 , ζ ≥ 0 = ( ζ + γ x T x ′ ) 3 with γ > 0 , ζ ≥ 0 ⋮ = ( ζ + γ x T x ′ ) Q with γ > 0 , ζ ≥ 0
其中
K
1
K_1
K 1
上述的多项式核函数都是有限维度的,那么现在使用核技巧避免了对映射空间的依赖,是否存在拥有无限维度(infinite dimensional)或者说最有力(most powerful)的映射函数
Φ
\Phi
Φ
K
(
x
,
x
′
)
=
exp
(
−
(
x
−
x
′
)
2
)
=
exp
(
−
(
x
)
2
)
exp
(
−
(
x
′
)
2
)
exp
(
2
x
x
′
)
⟹
Taylor
exp
(
−
(
x
)
2
)
exp
(
−
(
x
′
)
2
)
(
∑
i
=
0
∞
(
2
x
x
′
)
i
i
!
)
=
∑
i
=
0
∞
(
exp
(
−
(
x
)
2
)
exp
(
−
(
x
′
)
2
)
2
i
i
!
2
i
i
!
(
x
)
i
(
x
′
)
i
=
Φ
(
x
)
T
Φ
(
x
′
)
\begin{aligned} K\left(x, x^{\prime}\right) & =\exp \left(-\left(x-x^{\prime}\right)^{2}\right) \\ &=\exp \left(-(x)^{2}\right) \exp \left(-\left(x^{\prime}\right)^{2}\right) \exp \left(2 x x^{\prime}\right) \\ &{\mathop{\Longrightarrow}\limits^{\text { Taylor }}} \exp \left(-(x)^{2}\right) \exp \left(-\left(x^{\prime}\right)^{2}\right)\left(\sum_{i=0}^{\infty} \frac{\left(2 x x^{\prime}\right)^{i}}{i !}\right) \\ &=\sum_{i=0}^{\infty}\left(\exp \left(-(x)^{2}\right) \exp \left(-\left(x^{\prime}\right)^{2}\right) \sqrt{\frac{2^{i}}{i !}} \sqrt{\frac{2^{i}}{i !}}(x)^{i}\left(x^{\prime}\right)^{i}\right.\\ &=\Phi(x)^{T} \Phi\left(x^{\prime}\right) \end{aligned}
K ( x , x ′ ) = exp ( − ( x − x ′ ) 2 ) = exp ( − ( x ) 2 ) exp ( − ( x ′ ) 2 ) exp ( 2 x x ′ ) ⟹ Taylor exp ( − ( x ) 2 ) exp ( − ( x ′ ) 2 ) ( i = 0 ∑ ∞ i ! ( 2 x x ′ ) i ) = i = 0 ∑ ∞ ( exp ( − ( x ) 2 ) exp ( − ( x ′ ) 2 ) i ! 2 i
i ! 2 i
( x ) i ( x ′ ) i = Φ ( x ) T Φ ( x ′ )
这时便有了无限维的映射函数:
Φ
(
x
)
=
exp
(
−
x
2
)
⋅
(
1
,
2
1
!
x
,
2
2
2
!
x
2
,
…
)
\Phi(x)=\exp \left(-x^{2}\right) \cdot\left(1, \sqrt{\frac{2}{1 !}} x, \sqrt{\frac{2^{2}}{2 !}} x^{2}, \ldots\right)
Φ ( x ) = exp ( − x 2 ) ⋅ ( 1 , 1 ! 2
x , 2 ! 2 2
x 2 , … )
所以通用的高斯核函数(Gaussian Kernel)可以写为:
K
(
x
,
x
′
)
=
exp
(
−
γ
∥
x
−
x
′
∥
2
)
with
γ
>
0
K\left(\mathbf{x}, \mathbf{x}^{\prime}\right)=\exp \left(-\gamma\left\|\mathbf{x}-\mathbf{x}^{\prime}\right\|^{2}\right) \text { with } \gamma>0
K ( x , x ′ ) = exp ( − γ ∥ x − x ′ ∥ 2 ) with γ > 0
所以拥有高斯核的高斯支持向量机(Gaussian SVM)的表达式如下:
g
s
v
m
(
x
)
=
sign
(
∑
S
V
α
n
y
n
K
(
x
n
,
x
)
+
b
)
=
sign
(
∑
S
V
α
n
y
n
exp
(
−
γ
∥
x
−
x
n
∥
2
)
+
b
)
\begin{aligned} g_{\mathrm{svm}}(\mathbf{x}) &=\operatorname{sign}\left(\sum_{\mathrm{SV}} \alpha_{n} y_{n} K\left(\mathrm{x}_{n}, \mathbf{x}\right)+b\right) \\ &=\operatorname{sign}\left(\sum_{\mathrm{SV}} \alpha_{n} y_{n} \exp \left(-\gamma\left\|\mathbf{x}-\mathbf{x}_{n}\right\|^{2}\right)+b\right) \end{aligned}
g s v m ( x ) = s i g n ( S V ∑ α n y n K ( x n , x ) + b ) = s i g n ( S V ∑ α n y n exp ( − γ ∥ x − x n ∥ 2 ) + b )
又叫做径向基函数核(Radial Basis Function (RBF) kernel)。其中 Radial 代表了类似 Gaussian 这样由中心向外放射的函数,而 Basis 代表了线性组合。
值得注意的是当
γ
\gamma
γ
线性核(Linear Kernel):important and basic
优点:安全(Linear first),快速(使用Special QP 求解很快),可解释性强(
w
\mathbf{w}
w
S
V
s
SVs
S V s
缺点:有局限性,只适用于线性可分的数据
多项式核(Polynomial Kernel):perhaps small-Q only(尽量使用低阶次的)
优点:阶次(Q)可控,解决非线性
缺点:数值计算难以处理(高阶次时),且三个参数
(
γ
,
ζ
,
Q
)
( \gamma , \zeta , Q )
( γ , ζ , Q )
高斯核(Gaussian Kernel):one of most popular but be used with care
优点:比线性核和多项式核有更高的空间,且数值计算好处理(bounded),只需要选择一个参数。
缺点:比线性计算慢,
w
\mathbf{w}
w
一个核函数有效的充分必要条件是: Mercer’s condition
对称(symmetric)
矩阵
K
K
K
K
K
K
k
i
j
=
K
(
x
i
,
x
j
)
k _ { i j } = K \left( \mathbf { x } _ { i } , \mathbf { x } _ { j } \right)
k i j = K ( x i , x j )
K
=
[
Φ
(
x
1
)
T
ϕ
(
x
1
)
Φ
(
x
1
)
T
Φ
(
x
2
)
…
Φ
(
x
1
)
T
Φ
(
x
N
)
Φ
(
x
2
)
T
ϕ
(
x
1
)
Φ
(
x
2
)
T
Φ
(
x
2
)
…
Φ
(
x
2
)
T
ϕ
(
x
N
)
⋯
⋯
⋯
⋯
Φ
(
x
N
)
T
Φ
(
x
1
)
Φ
(
x
N
)
T
Φ
(
x
2
)
…
Φ
(
x
N
)
T
Φ
(
x
N
)
]
=
[
z
1
z
2
…
z
N
]
T
[
z
1
z
2
…
z
N
]
=
Z
Z
T
must always be positive semi-definite
\begin{aligned}K & = \left[ \begin{array} { c c c c } \boldsymbol { \Phi } \left( \mathbf { x } _ { 1 } \right) ^ { T } \boldsymbol { \phi } \left( \mathbf { x } _ { 1 } \right) & \boldsymbol { \Phi } \left( \mathbf { x } _ { 1 } \right) ^ { T } \boldsymbol { \Phi } \left( \mathbf { x } _ { 2 } \right) & \dots & \mathbf { \Phi } \left( \mathbf { x } _ { 1 } \right) ^ { T } \boldsymbol { \Phi } \left( \mathbf { x } _ { N } \right) \\ \boldsymbol { \Phi } \left( \mathbf { x } _ { 2 } \right) ^ { T } \boldsymbol { \phi } \left( \mathbf { x } _ { 1 } \right) & \boldsymbol { \Phi } \left( \mathbf { x } _ { 2 } \right) ^ { T } \boldsymbol { \Phi } \left( \mathbf { x } _ { 2 } \right) & \dots & \boldsymbol { \Phi } \left( \mathbf { x } _ { 2 } \right) ^ { T } \boldsymbol { \phi } \left( \mathbf { x } _ { N } \right) \\ \cdots & \cdots & \cdots & \cdots \\ \boldsymbol { \Phi } \left( \mathbf { x } _ { N } \right) ^ { T } \Phi \left( \mathbf { x } _ { 1 } \right) & \boldsymbol { \Phi } \left( \mathbf { x } _ { N } \right) ^ { T } \Phi \left( \mathbf { x } _ { 2 } \right) & \ldots & \boldsymbol { \Phi } \left( \mathbf { x } _ { N } \right) ^ { T } \Phi \left( \mathbf { x } _ { N } \right) \end{array} \right] \\ &= { \left[ \begin{array} { l l l l } \mathbf { z } _ { 1 } & \mathbf { z } _ { 2 } & \ldots & \mathbf { z } _ { N } \end{array} \right] ^ { T } \left[ \begin{array} { l l l l } \mathbf { z } _ { 1 } & \mathbf { z } _ { 2 } & \ldots & \mathbf { z } _ { N } \end{array} \right] } \\ &= \mathrm { ZZ } ^ { T } \text { must always be positive semi-definite } \end{aligned}
K = ⎣ ⎢ ⎢ ⎡ Φ ( x 1 ) T ϕ ( x 1 ) Φ ( x 2 ) T ϕ ( x 1 ) ⋯ Φ ( x N ) T Φ ( x 1 ) Φ ( x 1 ) T Φ ( x 2 ) Φ ( x 2 ) T Φ ( x 2 ) ⋯ Φ ( x N ) T Φ ( x 2 ) … … ⋯ … Φ ( x 1 ) T Φ ( x N ) Φ ( x 2 ) T ϕ ( x N ) ⋯ Φ ( x N ) T Φ ( x N ) ⎦ ⎥ ⎥ ⎤ = [ z 1 z 2 … z N ] T [ z 1 z 2 … z N ] = Z Z T must always be positive semi-definite
在之前介绍的都是硬间隔支持向量机,不允许存在分类错误的状况(在噪声存在的情况下)。这里结合 Pocket 算法,对于分类错误的样本点实施以惩罚。
C
C
C
min
b
,
w
1
2
w
⊤
w
+
C
⋅
∑
n
=
1
N
[
[
y
n
≠
sign
(
w
⊤
z
n
+
b
)
]
]
s.t.
y
n
(
w
T
z
n
+
b
)
≥
1
for correct
n
y
n
(
w
T
z
n
+
b
)
≥
−
∞
for incorrect
n
\begin{array} { l l } \min _ { b , w } & \frac { 1 } { 2 } \mathbf { w } ^ { \top } \mathbf { w } + C \cdot \sum _ { n = 1 } ^ { N } \left[\kern-0.25em\left[ y _ { n } \neq \operatorname { sign } \left( \mathbf { w } ^ { \top } \mathbf { z } _ { n } + b \right) \right] \kern-0.25em \right] \\ \text { s.t. } & y _ { n } \left( \mathbf { w } ^ { T } \mathbf { z } _ { n } + b \right) \geq 1 \text { for correct } n \\ & y _ { n } \left( \mathbf { w } ^ { T } \mathbf { z } _ { n } + b \right) \geq - \infty \text { for incorrect } n \end{array}
min b , w s.t. 2 1 w ⊤ w + C ⋅ ∑ n = 1 N [ [ y n = s i g n ( w ⊤ z n + b ) ] ] y n ( w T z n + b ) ≥ 1 for correct n y n ( w T z n + b ) ≥ − ∞ for incorrect n
min
b
,
w
1
2
w
T
w
+
C
⋅
∑
n
=
1
N
[
[
y
n
≠
sign
(
w
T
z
n
+
b
)
]
]
s.t.
y
n
(
w
T
z
n
+
b
)
≥
1
−
∞
⋅
[
[
y
n
≠
sign
(
w
T
z
n
+
b
)
]
]
\begin{array} { l l } \min _ { b , w } & \frac { 1 } { 2 } \mathbf { w } ^ { T } \mathbf { w } + C \cdot \sum _ { n = 1 } ^ { N } \left[ \kern-0.25em \left[y _ { n } \neq \operatorname { sign } \left( \mathbf { w } ^ { T } \mathbf { z } _ { n } + b \right) \right] \kern-0.25em \right]\\ \text { s.t. } & y _ { n } \left( \mathbf { w } ^ { T } \mathbf { z } _ { n } + b \right) \geq 1 - \infty \cdot \left[ \kern-0.25em \left[ y _ { n } \neq \operatorname { sign } \left( \mathbf { w } ^ { T } \mathbf { z } _ { n } + b \right) \right] \kern-0.25em \right] \end{array}
min b , w s.t. 2 1 w T w + C ⋅ ∑ n = 1 N [ [ y n = s i g n ( w T z n + b ) ] ] y n ( w T z n + b ) ≥ 1 − ∞ ⋅ [ [ y n = s i g n ( w T z n + b ) ] ]
但是值得注意的是
[
[
]
]
\left[ \kern-0.15em \left[ \right]\kern-0.15em \right]
[ [ ] ]
min
b
,
w
,
ξ
1
2
w
T
w
+
C
⋅
∑
n
=
1
N
ξ
n
s.t.
y
n
(
w
T
z
n
+
b
)
≥
1
−
ξ
n
and
ξ
n
≥
0
for all
n
\begin{aligned} \min _ { b , \mathbf { w } , \xi } & \frac { 1 } { 2 } \mathbf { w } ^ { T } \mathbf { w } + C \cdot \sum _ { n = 1 } ^ { N } \xi _ { n } \\ \text { s.t. } & y _ { n } \left( \mathbf { w } ^ { T } \mathbf { z } _ { n } + b \right) \geq 1 - \xi _ { n } \text { and } \xi _ { n } \geq 0 \text { for all } n \end{aligned}
b , w , ξ min s.t. 2 1 w T w + C ⋅ n = 1 ∑ N ξ n y n ( w T z n + b ) ≥ 1 − ξ n and ξ n ≥ 0 for all n
可以看出本问题是一个二次规划问题
Q
P
with
d
~
+
1
+
N
variables,
2
N
constraints
\mathrm { QP } \text { with } \tilde { d } + 1 + N \text { variables, } 2 N \text { constraints }
Q P with d ~ + 1 + N variables, 2 N constraints
d
~
\tilde { d }
d ~
首先将其转换为无约束最优化问题:写出其拉格朗日方程(Lagrange Function),其中
α
n
,
β
n
\alpha_{n},\beta_n
α n , β n
L
(
b
,
w
,
ξ
,
α
,
β
)
=
1
2
w
⊤
w
+
C
⋅
∑
n
=
1
N
ξ
n
+
∑
n
=
1
N
α
n
⋅
(
1
−
ξ
n
−
y
n
(
w
T
z
n
+
b
)
)
+
∑
n
=
1
N
β
n
⋅
(
−
ξ
n
)
\begin{aligned} \mathcal { L } ( b , \mathbf { w } , \boldsymbol { \xi } , \alpha , \boldsymbol { \beta } ) = & \frac { 1 } { 2 } \mathbf { w } ^ { \top } \mathbf { w } + C \cdot \sum _ { n = 1 } ^ { N } \xi _ { n } \\ & + \sum _ { n = 1 } ^ { N } \alpha _ { n } \cdot \left( 1 - \xi _ { n } - y _ { n } \left( \mathbf { w } ^ { T } \mathbf { z } _ { n } + b \right) \right) \\ &+ \sum _ { n = 1 } ^ { N } \beta _ { n } \cdot \left( - \xi _ { n } \right) \end{aligned}
L ( b , w , ξ , α , β ) = 2 1 w ⊤ w + C ⋅ n = 1 ∑ N ξ n + n = 1 ∑ N α n ⋅ ( 1 − ξ n − y n ( w T z n + b ) ) + n = 1 ∑ N β n ⋅ ( − ξ n )
max
α
n
≥
0
,
β
n
≥
0
(
min
b
,
w
,
ξ
L
(
b
,
w
,
ξ
,
α
,
β
)
)
⟹
max
α
n
≥
0
,
β
n
≥
0
(
min
b
,
w
,
ξ
1
2
w
⊤
w
+
C
⋅
∑
n
=
1
N
ξ
n
+
∑
n
=
1
N
α
n
⋅
(
1
−
ξ
n
−
y
n
(
w
T
z
n
+
b
)
)
+
∑
n
=
1
N
β
n
⋅
(
−
ξ
n
)
)
\max _ { \alpha _ { n } \geq 0 , \beta _ { n } \geq 0 } \left( \min _ { b , \mathbf { w } , \xi } \mathcal { L } ( b , \mathbf { w } , \boldsymbol { \xi } , \boldsymbol { \alpha } , \boldsymbol { \beta } ) \right) \\ \Longrightarrow \max _ { \alpha _ { n } \geq 0 , \beta _ { n } \geq 0 } \left( \min _ { b , \mathbf { w } , \xi } \frac { 1 } { 2 } \mathbf { w } ^ { \top } \mathbf { w } + C \cdot \sum _ { n = 1 } ^ { N } \xi _ { n } + \sum _ { n = 1 } ^ { N } \alpha _ { n } \cdot \left( 1 - \xi _ { n } - y _ { n } \left( \mathbf { w } ^ { T } \mathbf { z } _ { n } + b \right) \right) + \sum _ { n = 1 } ^ { N } \beta _ { n } \cdot \left( - \xi _ { n } \right) \right)
α n ≥ 0 , β n ≥ 0 max ( b , w , ξ min L ( b , w , ξ , α , β ) ) ⟹ α n ≥ 0 , β n ≥ 0 max ( b , w , ξ min 2 1 w ⊤ w + C ⋅ n = 1 ∑ N ξ n + n = 1 ∑ N α n ⋅ ( 1 − ξ n − y n ( w T z n + b ) ) + n = 1 ∑ N β n ⋅ ( − ξ n ) )
与硬间隔支持向量机相似:
∂
L
∂
ξ
n
=
0
=
C
−
α
n
−
β
n
\frac { \partial \mathcal { L } } { \partial \xi _ { n } } = 0 = C - \alpha _ { n } - \beta _ { n }
∂ ξ n ∂ L = 0 = C − α n − β n
β
n
=
C
−
α
n
,
0
≤
α
n
≤
C
\beta _ { n } = C - \alpha _ { n },0 \leq \alpha _ { n } \leq C
β n = C − α n , 0 ≤ α n ≤ C
max
α
n
≥
0
,
β
n
≥
0
(
min
b
,
w
,
ξ
1
2
w
⊤
w
+
C
⋅
∑
n
=
1
N
ξ
n
+
∑
n
=
1
N
α
n
⋅
(
1
−
ξ
n
−
y
n
(
w
T
z
n
+
b
)
)
+
∑
n
=
1
N
β
n
⋅
(
−
ξ
n
)
)
⟹
max
α
n
≥
0
,
β
n
≥
0
(
min
b
,
w
,
ξ
1
2
w
⊤
w
+
∑
n
=
1
N
α
n
⋅
(
1
−
y
n
(
w
T
z
n
+
b
)
)
)
\max _ { \alpha _ { n } \geq 0 , \beta _ { n } \geq 0 } \left( \min _ { b , \mathbf { w } , \xi } \frac { 1 } { 2 } \mathbf { w } ^ { \top } \mathbf { w } + C \cdot \sum _ { n = 1 } ^ { N } \xi _ { n } + \sum _ { n = 1 } ^ { N } \alpha _ { n } \cdot \left( 1 - \xi _ { n } - y _ { n } \left( \mathbf { w } ^ { T } \mathbf { z } _ { n } + b \right) \right) + \sum _ { n = 1 } ^ { N } \beta _ { n } \cdot \left( - \xi _ { n } \right) \right) \\ \Longrightarrow \max _ { \alpha _ { n } \geq 0 , \beta _ { n } \geq 0 } \left( \min _ { b , \mathbf { w } , \xi } \frac { 1 } { 2 } \mathbf { w } ^ { \top } \mathbf { w } + \sum _ { n = 1 } ^ { N } \alpha _ { n } \cdot \left( 1 - y _ { n } \left( \mathbf { w } ^ { T } \mathbf { z } _ { n } + b \right) \right) \right)
α n ≥ 0 , β n ≥ 0 max ( b , w , ξ min 2 1 w ⊤ w + C ⋅ n = 1 ∑ N ξ n + n = 1 ∑ N α n ⋅ ( 1 − ξ n − y n ( w T z n + b ) ) + n = 1 ∑ N β n ⋅ ( − ξ n ) ) ⟹ α n ≥ 0 , β n ≥ 0 max ( b , w , ξ min 2 1 w ⊤ w + n = 1 ∑ N α n ⋅ ( 1 − y n ( w T z n + b ) ) )
至此可以看出其内部问题与硬间隔支持向量机的内部问题一样:
∂
L
∂
b
=
0
⇒
∑
n
=
1
N
α
n
y
n
=
0
∂
L
∂
w
i
=
0
⇒
w
=
∑
n
=
1
N
α
n
y
n
z
n
\frac { \partial \mathcal { L } } { \partial b } = 0 \Rightarrow \sum _ { n = 1 } ^ { N } \alpha _ { n } y _ { n } = 0 \\ \frac { \partial \mathcal { L } } { \partial w _ { i } } = 0 \Rightarrow \mathbf { w } = \sum _ { n = 1 } ^ { N } \alpha _ { n } y _ { n } \mathbf { z } _ { n }
∂ b ∂ L = 0 ⇒ n = 1 ∑ N α n y n = 0 ∂ w i ∂ L = 0 ⇒ w = n = 1 ∑ N α n y n z n
所以与硬间隔支持向量机不同地方是限制条件中
α
n
\alpha_n
α n
min
α
1
2
∑
n
=
1
N
∑
m
=
1
N
α
n
α
m
y
n
y
m
z
n
T
z
m
−
∑
n
=
1
N
α
n
subject to
∑
n
=
1
N
y
n
α
n
=
0
0
≤
α
n
≤
C
,
for
n
=
1
,
2
,
…
,
N
\begin{aligned} \min _{\alpha} \quad & \frac{1}{2} \sum_{n=1}^{N} \sum_{m=1}^{N} \alpha_{n} \alpha_{m} y_{n} y_{m} \mathbf{z}_{n}^{T} \mathbf{z}_{m}-\sum_{n=1}^{N} \alpha_{n} \\ \text {subject to} \quad & \sum_{n=1}^{N} y_{n} \alpha_{n}=0 \\ & 0 \leq \alpha_{n} \leq C, \text { for } n=1,2, \ldots, N \end{aligned}
α min subject to 2 1 n = 1 ∑ N m = 1 ∑ N α n α m y n y m z n T z m − n = 1 ∑ N α n n = 1 ∑ N y n α n = 0 0 ≤ α n ≤ C , for n = 1 , 2 , … , N
可以看出这是一个QP问题带有
N
N
N
2
N
+
1
2N+1
2 N + 1
核软间隔支持向量机算法(Kernel Soft-Margin SVM Algorithm)的具体实现步骤为:
q
n
,
m
=
y
n
y
m
K
(
x
n
,
x
m
)
;
p
=
−
1
N
;
(
A
,
c
)
q_{n, m}=y_{n} y_{m} K\left(\mathbf{x}_{n}, \mathbf{x}_{m}\right) ; \mathbf{p}=-\mathbf{1}_{N} ;(\mathrm{A}, \mathbf{c})
q n , m = y n y m K ( x n , x m ) ; p = − 1 N ; ( A , c )
α
←
Q
P
(
Q
D
,
p
,
A
,
c
)
\alpha \leftarrow \mathrm{QP}\left(\mathrm{Q}_{\mathrm{D}}, \mathrm{p}, \mathrm{A}, \mathrm{c}\right)
α ← Q P ( Q D , p , A , c )
b
←
y
s
−
∑
S
V
indices
n
α
n
y
n
K
(
x
n
,
x
s
)
b \leftarrow y _ { s } - \sum \limits_ { \mathrm { SV } \text { indices } n } \alpha _ { n } y _ { n } K \left( \mathbf { x } _ { n } , \mathbf { x } _ { s } \right)
b ← y s − S V indices n ∑ α n y n K ( x n , x s ) return SVs and their
α
n
\alpha_{n}
α n
b
b
b
x
\mathbf{x}
x
g
s
v
m
(
x
)
=
sign
(
∑
SV indices
n
α
n
y
n
K
(
x
n
,
x
)
+
b
)
g_{\mathrm{svm}}(\mathbf{x})=\operatorname{sign}\left(\underset{\text { SV indices } n}{\sum} \alpha_{n} y_{n} K\left(\mathbf{x}_{n}, \mathbf{x}\right)+b\right)
g s v m ( x ) = s i g n ( SV indices n ∑ α n y n K ( x n , x ) + b )
其中
b
b
b
α
n
(
1
−
ξ
n
−
y
n
(
w
T
z
n
+
b
)
)
=
0
,
(
C
−
α
n
)
ξ
n
=
0
\alpha _ { n } \left( 1 - \xi_n - y _ { n } \left( \mathbf { w } ^ { T } \mathbf { z } _ { n } + b \right) \right) = 0, (C - \alpha_n)\xi_n = 0
α n ( 1 − ξ n − y n ( w T z n + b ) ) = 0 , ( C − α n ) ξ n = 0
0
<
α
n
<
C
0< \alpha_n < C
0 < α n < C
ξ
n
=
0
\xi_n = 0
ξ n = 0
b
=
y
n
−
w
T
z
n
b=y_{n}-\mathbf{w}^{T} \mathbf{z}_{n}
b = y n − w T z n
α
n
\alpha_n
α n
C
C
C
α
n
\alpha_n
α n
C
C
C
α
s
∈
(
0
,
C
)
\alpha_s \in (0,C)
α s ∈ ( 0 , C )
b
b
b
α
n
\alpha_n
α n
□
\square
□
(
0
<
α
n
<
C
)
\left( 0 < \alpha _ { n } < C \right)
( 0 < α n < C )
ξ
n
=
0
,
⇒
\xi _ { n } = 0,\Rightarrow
ξ n = 0 , ⇒
b
b
b
Δ
\Delta
Δ
(
α
n
=
C
)
\left( \alpha _ { n } = C \right)
( α n = C )
ξ
n
=
violation amount
,
⇒
\xi _ { n } = \text{violation amount},\Rightarrow
ξ n = violation amount , ⇒
(
α
n
=
0
)
\left(\alpha _ { n } = 0\right)
( α n = 0 )
ξ
n
=
0
,
⇒
\xi _ { n } = 0,\Rightarrow
ξ n = 0 , ⇒
也就是说
b
b
b
α
n
\alpha_n
α n
E
c
v
(
C
,
γ
)
E _ { \mathrm { cv } } ( C , \gamma )
E c v ( C , γ )
(
C
,
γ
)
( C , \gamma )
( C , γ )
E
cv
E _ { \text {cv} }
E cv
交叉验证误差:对于软间隔 SVM 是非常流行的评价标准。
值得注意的是支持向量的个数(#SV)可用于表达
E
loocv
E _ { \text {loocv} }
E loocv
E
loocv
≤
#
S
V
N
E _ { \text {loocv } } \leq \frac { \# \mathrm { SV } } { N }
E loocv ≤ N # S V
for
(
x
N
,
y
N
)
:
if optimal
α
N
=
0
(non-SV)
⟹
(
α
1
,
α
2
,
…
,
α
N
−
1
)
still optimal when leaving out
(
x
N
,
y
N
)
\begin{array} { l } \text { for } \left( \mathbf { x } _ { N } , y _ { N } \right) : \text { if optimal } \alpha _ { N } = 0 \text { (non-SV) } \\ \Longrightarrow \left( \alpha _ { 1 } , \alpha _ { 2 } , \ldots , \alpha _ { N - 1 } \right) \text { still optimal when leaving out } \left( \mathbf { x } _ { N } , y _ { N } \right) \end{array}
for ( x N , y N ) : if optimal α N = 0 (non-SV) ⟹ ( α 1 , α 2 , … , α N − 1 ) still optimal when leaving out ( x N , y N )
e
non-SV
=
err
(
g
−
,
non-SV
)
=
err
(
g
,
non-SV
)
=
0
e
S
V
≤
1
\begin{aligned} e _ { \text {non-SV } } & = \operatorname { err } \left( g ^ { - } , \text {non-SV } \right) \\ & = \operatorname { err } ( g , \text { non-SV } ) = 0 \\ e _ { S V } & \leq 1 \end{aligned}
e non-SV e S V = e r r ( g − , non-SV ) = e r r ( g , non-SV ) = 0 ≤ 1 虽然只是上限,但是当交叉验证非常耗时时,支持向量的个数经常用于估计模型的安全性,支持向量的个数越多越容易过拟合。 方法是通过对 不同的
(
C
,
γ
)
( C , \gamma )
( C , γ )
软间隔实用工具有:LIBLINEAR(线性的),LIBSVM(非线性的)