豆瓣电影Top250榜单
一、简介
网址:https://movie.douban.com/top250
效果:下载Top250的电影封面
使用框架:requests、re
难度系数:✩
二、教程
1. 确定爬虫思路
首先我们在浏览器打开网站,按 Ctrl+U 查看网页源代码,我们可以在网页源代码中发现所有的电影名字和封面的图片地址,说明该网站采取的是静态网页的方式:

静态网页就是把所有的信息全部都防在网页源代码中,我们要取信息,只需要把网页源代码下载下来就行。
有了网页源代码我们就已经拿到了所有信息,剩下的工作就是从网页源代码中提取信息罢了。
因此相对来说, 这种静态网页的网站都是属于那种比较容易爬取的网站 。
向下浏览网页,我们发现这里不同的页码。总记录为250条,因此我们可以确定页码是分散在了这10张页面里的。
点击第2页和第3页,我们可以发现上面的网址中的数字和下面的页码的关系为:网址 = 25 * 页码
经过对网页代码的简单分析,我们就可以确定我们的爬虫思路了:
2. 构造爬虫
本次爬虫我们采用最为经典的爬虫库—— requests进行爬取,这是一个第三方库,没有安装的需要通过 pip 进行安装:
pip install requests
安装完成后我们就可以开始进行我们的爬虫之旅了!
首先尝试下载网页源代码:
import requests
url = "https://movie.douban.com/top250?start=0&filter="
response = requests.get(url) # 请求网站
print(response) # 打印响应状态
执行完上面的结果后,我们得到的结果却是这个玩意儿:
<Response [418]>
去查HTTP状态码,结果发现没有对上号啊,以4开头的状态码只有417,哪里来的418???
赶紧去搜索一下,发现了状态码418的定义:
HTTP状态码418是IETF在1998年愚人节发布的一个玩笑RFC,在RFC 2324超文本咖啡壶控制协议中定义的,并不需要在真实的HTTP服务器中定义。当一个控制茶壶的HTCPCP收到BREW或POST指令要求其煮咖啡时应当回传此错误。它的含义是当客户端给一个茶壶发送泡咖啡的请求时,那就就返回一个错误的状态码表示:I’m a teapot,即:“我是一个茶壶”。这个HTTP状态码在某些网站中用作彩蛋,另外也用于一些爬虫警告。
原来我们是被别人发现了我们是一只小爬虫了。。。
别慌,在做爬虫这条道路上,反爬虫和爬虫本身就是一直在做斗争的。胜败乃兵家常事,不要会心丧气!
网站是如何检测到我们是爬虫的呢?
每一个向网站的请求,我们都会带上一个Headers(了解更多请点击传送门),这个Headers就是网站来分辨用户的依据。
在这里面有一项参数,叫做 **User-Agent **
这个参数会告诉网站,请求它的浏览器的信息,当我们用上面的程序请求网站时,我们发送的 User-Agent 是长这个模样的:python-requests/2.23.0
再点击传送门,看看我们用正常浏览器请求时我们的 User-Agent 是长啥模样的,我用谷歌请求的是长这样的:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.14 Safari/537.36
好家伙,差异这么大,一眼就把我们识破了。。。
不要灰心,既然它可以让正常的浏览器访问,那我们把自己也伪装成正常的浏览器吧!
import requests
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/83.0.4103.14 Safari/537.36 "
}
url = "https://movie.douban.com/top250?start=0&filter="
response = requests.get(url, headers=headers)
print(response)
print(response.test)
我们改良后的代码长这样,再去请求网站,得到的结果是下面这样的:
<Response [200]>
......
<img width="100" alt="肖申克的救赎" src="https://img3.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg" class="">
......
激动人心的时候到了,我们成功拿到了网页源代码!!!
下一步,我们就需要从网页源代码中提取信息了,在这里我选择的是使用正则表达式来提取信息,还不会正则的小伙伴赶快点击传送门去学习学习吧!
import re
name_url = re.findall('<img width="100" alt="(.*?)" src="(.*?)" class="">', response.text)
for name, purl in name_url:
print(f"name:{name}\turl:{purl}")
运行结果:
name:肖申克的救赎 url:https://img3.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg
name:霸王别姬 url:https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2561716440.jpg
......
既然我们已经拿到了图片的名字和url,那我们就可以尽情下载图片了!
with open(f"{name}.jpg", "wb") as f:
content = requests.get(url, headers=headers).content
f.write(content)
print(f"{name}.jpg 下载完成!")
运行结果:
肖申克的救赎.jpg 下载完成!
霸王别姬.jpg 下载完成!
至此,我们的这只小爬虫就已经完成了!大家快去试试吧~
3. 效果图
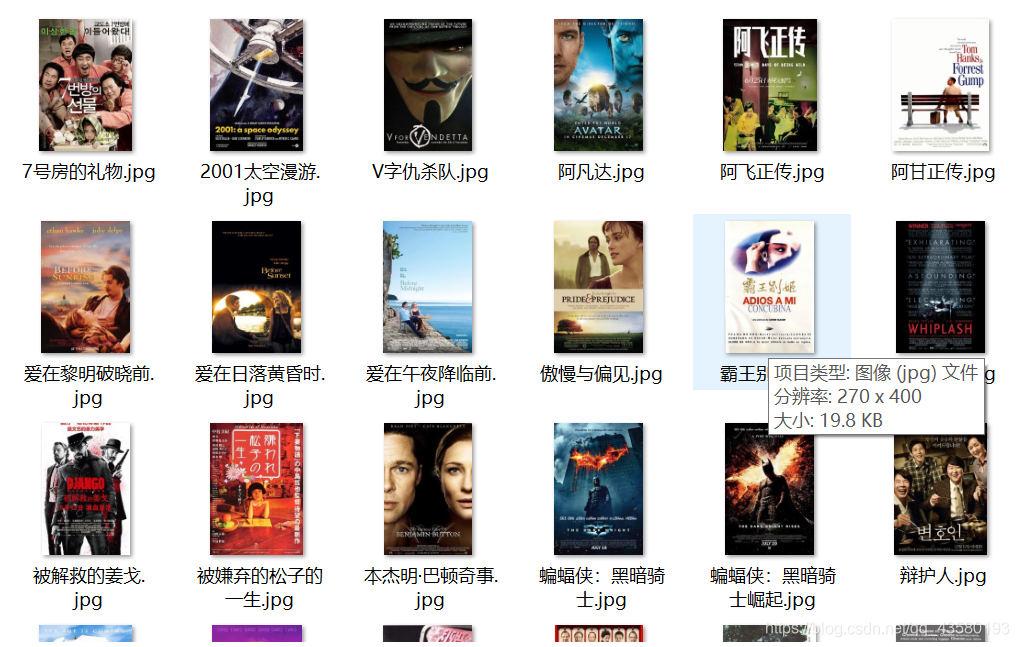
4. 完整代码
如果觉得有帮助,请为博主点一个小小的 star ✩吧,你的鼓励是博主最大的动力!