机器学习——基础算法(十五)
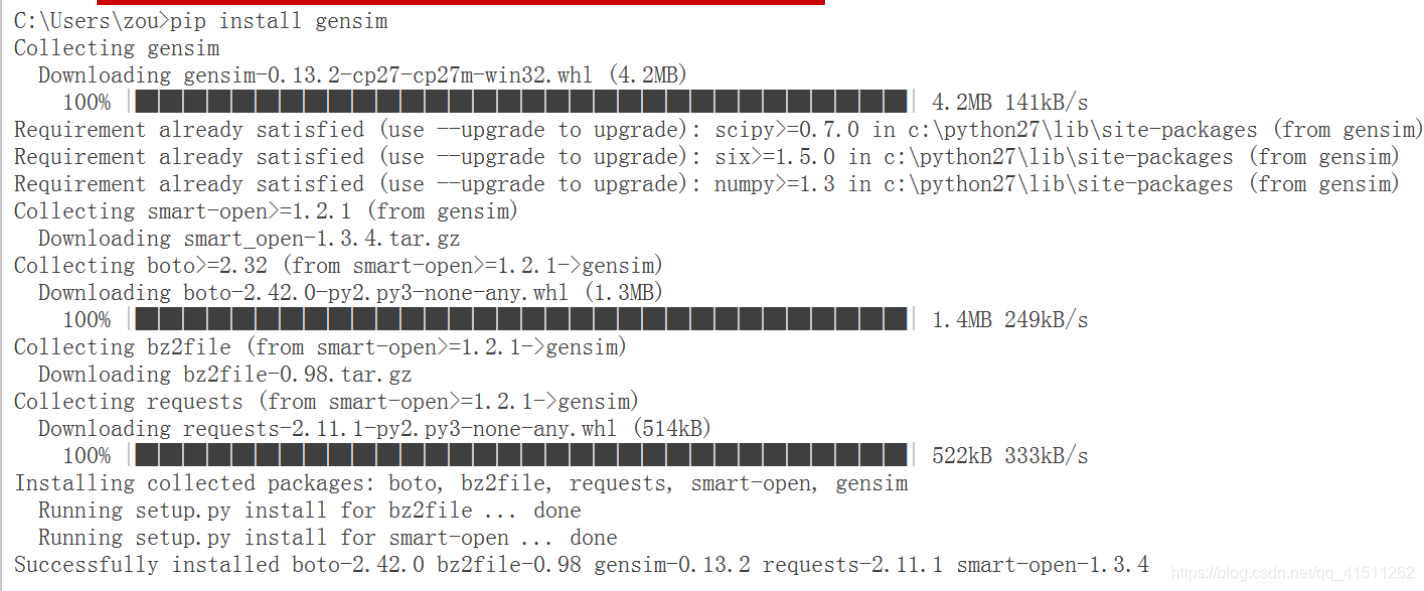
一、Gensim的安装
二、正则表达式
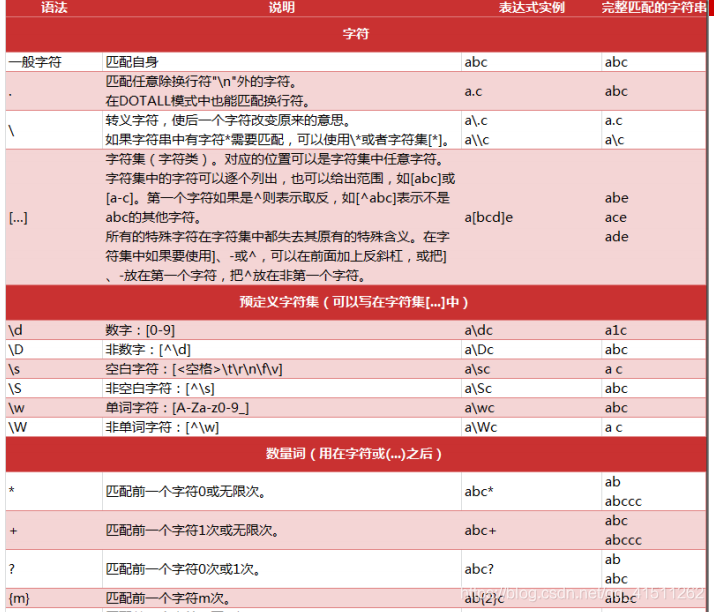
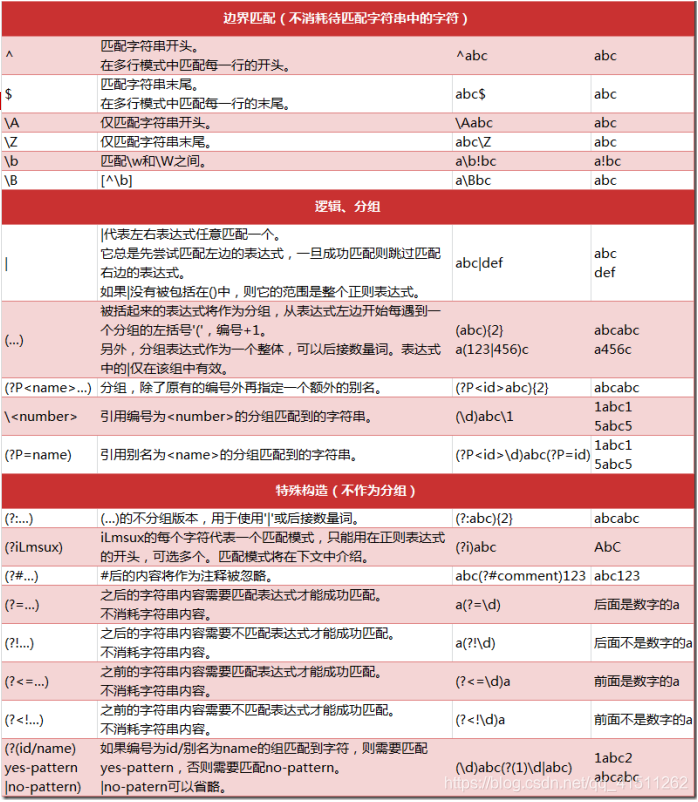
三、常用正则表达式


四、LDA_intro.py
# !/usr/bin/python
# -*- coding:utf-8 -*-
import numpy as np
from textrank4zh import TextRank4Keyword, TextRank4Sentence
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
if __name__ == '__main__':
f = file('novel.txt', mode='r')
text = f.read()
f.close()
tr4w = TextRank4Keyword()
tr4w.analyze(text=text, lower=True, window=5)
print (u'关键词:')
for item in tr4w.get_keywords(10, word_min_len=1):
print (item['word'], item['weight'])
tr4s = TextRank4Sentence()
tr4s.analyze(text=text, lower=True, source = 'no_stop_words')
data = pd.DataFrame(data=tr4s.key_sentences)
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
plt.figure(facecolor='w')
plt.plot(data['weight'], 'ro-', lw=2, ms=5, alpha=0.7)
plt.grid(b=True)
plt.xlabel(u'句子', fontsize=14)
plt.ylabel(u'重要度', fontsize=14)
plt.title(u'句子的重要度曲线', fontsize=18)
plt.show()
key_sentences = tr4s.get_key_sentences(num=20, sentence_min_len=4)
for sentence in key_sentences:
print (sentence['weight'], sentence['sentence'])