一 前言
数据结构,学后面的忘记前面的,学完前面的忘记后面的,何解?图形化它,强记它,能够按自己的思路复现它一次,不行再来一次,还不行再来一次!!
二 正文
学习数据结构,对我来说,比较舒服的方式:
- 提炼出问题,到底 求 什么?
- 图形化描述其实现过程
- 编程实现(找个例子跟着做更好)
- 判断条件 怎么实现
- 核心问题编程
- 实现一次简单运行
- 优化
三 举个例子——堆排序
3.1 堆排序是啥
堆排序是选择排序的一种,目的是利用最大堆的特点(最大堆就是根结点是最大值),得到我们想要的最大;
然后把这个最大值交换到待排序数据的最后面去,这样n个待排数据,就有1个是确定顺序的了,还剩下n-1个未排数据;
对剩下的n-1个重新堆化,循环往复,每次得到最大值都放到后面去,就完成排序了。
3.2 想法
上面的文字描述看着就很烦,不想看,看不懂。怎么办,答:图形化它!
当然我不会图形化,我是看人家的视频,然后知道整个堆排是怎么样的图形化的过程T_T.
所以,看视频去吧。
完结,撒花!
3.3 过程
A 目的
首先,要明白堆排的目的是啥?
堆排是选择排序的一种,选择排序(我说的是上升法),就是每个选出最大值,然后,交换到最后去。
为什么利用堆,来进行排序。堆能干嘛,堆这个树结构它的根,是所有结点中的最大值,我们利用堆就是为了要它的最大值。
所以,得出结论,堆排就是利用堆来进行选择排序。
B 图形化实现过程
B.1 主流程
-
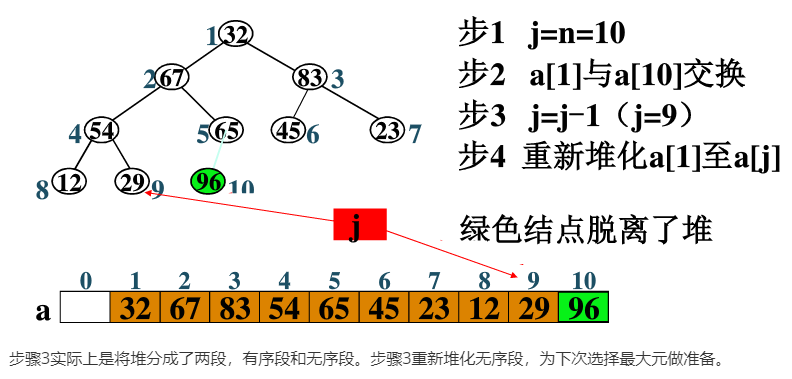
令
j=n;j是堆的最大下标,即堆的当前尾指针 -
将
a[1]与a[j]交换,将最大元换到当前尾 -
j=j-1;使堆的范围缩小 -
重新堆化(是关键步骤)
即调整
a[1]~a[j],使之成为一个新堆 -
若
j>1,则转步骤2;否则排序结束
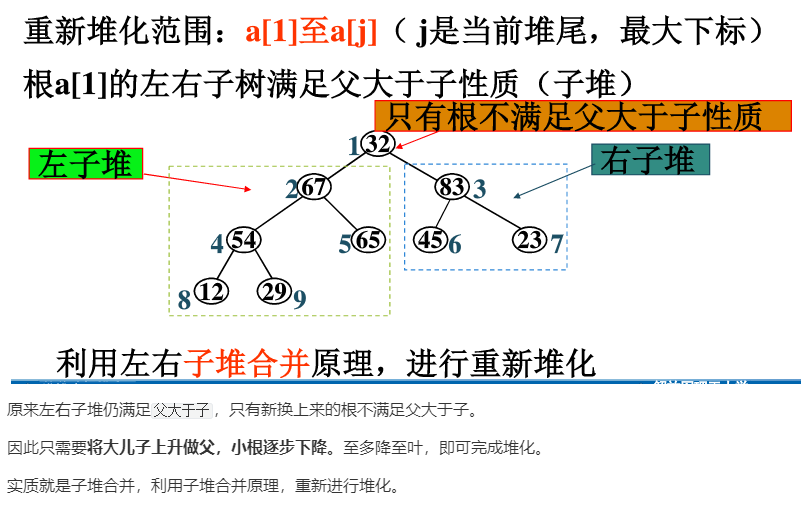
B.2 重新堆化
大儿子上升做父,小根逐步下降
实质就是“子堆合并”
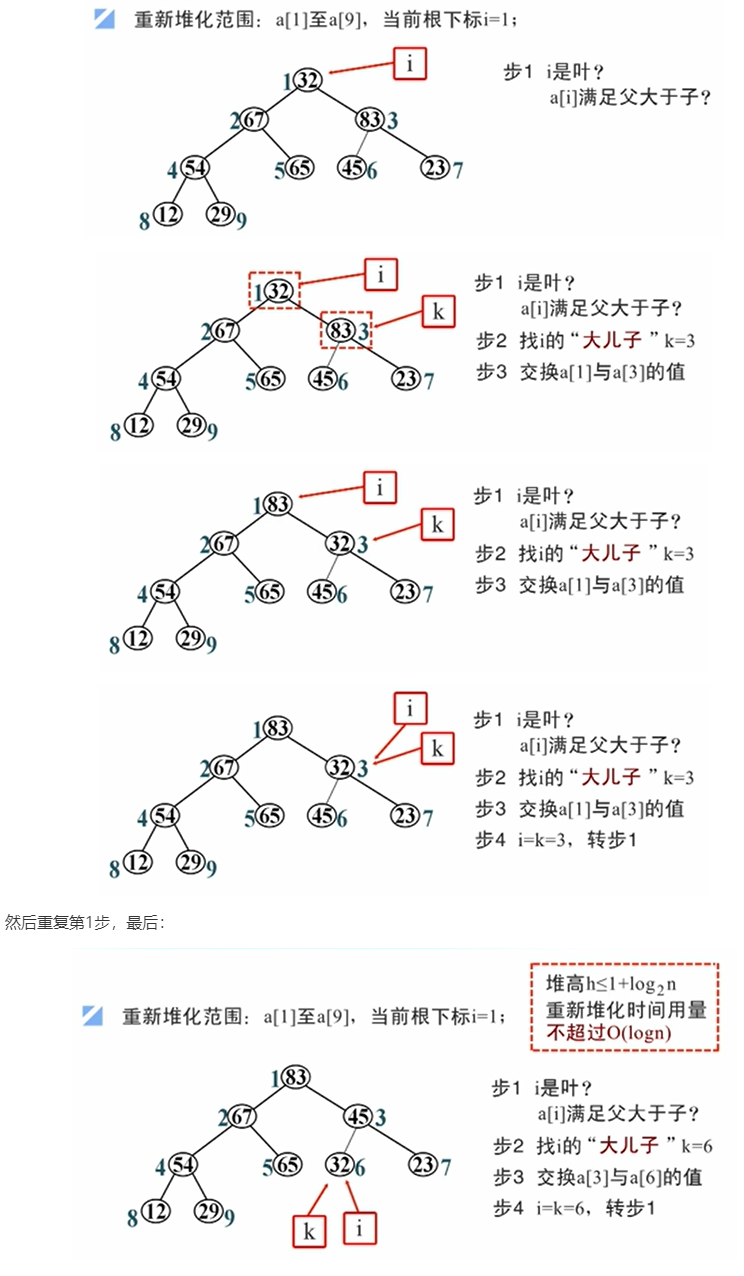
若用i表示当前堆的根的下标,j表示堆的尾的下标。重新堆化的具体步骤如下:
i = 1- 若
i是叶,若a[i]已满足父大于子的性质,重新堆化结束;否则继续下一步; - 找i的“大儿子”k;
- 交换
a[i]与a[k]的值,使根元素下沉。 i=k,转步骤2
C 编程实现
C.1 主流程
C.1.1 初始堆化
在全部流程开始前,先要进行初始堆化,初始堆化,就是将原数据组,形成一个堆,其原理利用重新堆化原理:
- 开始时,每个叶结点单独构成子堆
- 从最下层的非叶结点起,反复进行子堆合并
- 自底向上的逐步合并越来越大的堆
应该不会有人问为什么要初始堆化这个问题吧?
C.1.2 代码
// 主控函数
void heap_sort(int a[], int n)
{
int i, x;
for (i=n/2; i>=1; i--) //初始堆化,n/2之后都是叶子
heapify(a, i, n);
for (i=n; i>1; i--)
{
x = a[1]; // 将最大元放到最后
a[1] = a[i];
a[i] = x;
heapify(a, 1, i-1); // 重新堆化
}
}
C.2 重新堆化
C.2.1 例子
C.2.2 代码
// i是根结点
// j是待调整堆的堆尾的地址
void heapify(int a[], int i, int j)
{
int k, x;
k = 2*i; //k是i的左儿子
x = a[i]; //将a[i]存入临时变量x中,使a[i]单元空出。这样做的目的,是只要把大儿子往上升即可,减小交换的时间开销。
while (k <= j) //当i不是叶,k=j,只有左儿子,k<j有两个儿
{
if (k < j) //若i有两个儿子时,找大儿子
{
if ( a[k] < a[k+1] )
k = k + 1; //k指向i的大儿子
}
if (x >= a[k])
break; //i的儿子都不大于a[i]下渗结束
a[i] = a[k], i = k, k = 2*i; //大儿子上升,i指向下一数据
}
a[i] = x; //原根元素值就位
}
参考文献
[1] 数据结构 – 中国人民解放军陆军工程大学 –陈卫卫、李清等 – 公开课 – 中国大学MOOC
https://www.icourse163.org/course/PAEU-1001660013#/info