算法设计与分析总结笔记
- GitHub仓库资源
考试预测和复习建议
- 第1题:函数的阶:证明
- 第2题:Master定理
- 第3题:分治法
- 第4题:动态规划:压轴题预备
- 第5题:贪心算法
- 第6题:搜索算法:A*
- 第7题:平摊分析
- 第8题:网络流(余图、增广、最大流、最小割)
- 第9题:最短路/最小生成树
- 第10题:字符串匹配算法
大题:思想 + 伪代码 + 时间复杂度 + 证明
- 算法思想 + 伪代码:3-6、8-10必考
- 时间复杂度:3、4、5必考
- 证明:4、5必考
一、绪论
略
二、数学基础
计算复杂性函数的阶
:同阶
渐进紧界 / 常数差异
-
同时为渐进上界和渐进下界,即为渐进紧界
:低阶
渐进上界 / 最坏情况 / 上限
:高阶
渐进下界 / 最好情况 / 下限
:严格低阶
低阶 + 任意常数均满足
:严格高阶
高阶 + 任意常数均满足
例题
- 证明或否证:
要证 ,只需证 ,对于
令 ,有 ,对于 ,推得
使 ,得 ,得证。
Master定理
求解方程
其中 是常数, 是正函数
使用 与 比较
- 若 大,则
- 若 大,则
- 若 与 同阶,则

三、分治法
步骤:划分、递归、合并
时间复杂性:
- 递归求解阶段的时间复杂性
- 划分阶段的时间复杂性
- 合并阶段的时间复杂性
例题
-
对于平面上的两个点p1=(x1, y1)和p2=(x2,y2),如果x1<=x2且y1<=y2,则p2支配p1,给定平面上的n个点,请设计算法求其中没有被任何其他点支配的点
-
逆序对数求解:有长度为N的浮点数组A,元素分别为a1, a2, …, aN。如果满足i<j且ai>aj,则(ai, aj)构成一个逆序对。设计分治方法求解数组A的逆序对个数,并分析算法的时间复杂性。
解法:
- 从ai到aj的逆序对个数 = 从ai到ak中的 + 从ak到aj中的 + 两部分之间的
- 分治:二分计算每段的逆序对个数
- 重点:如何计算两部分之间的——模拟两个有序数列的合并可以计算
- 例:1 4 6 / 2 3 5
- 二分
- 2 放入,经过4和6,两个;
- 3 放入,经过4和6,两个;
- 6放入,经过6,一个;
- 一共5个逆序对,时间
- 给定一棵有N个节点的树,树上的每条边都有权值。定义两个节点vi, vj间的距离dis(vi, vj)为节点间路径的权值和。设计分治方法求解:树上有多少个节点对(vi, vj)满足i<j、且dis(vi, vj)<=K。
解法:
- 点对数 = 子节点为根的树的点对数 + 子结点为根的树之间的点对树
- 每个节点保存以自己为根的树的点对数
- 不同子树之间,求每个点和当前根的距离
- 每个子树获得一个“距离数列”,不同数列之间寻找数对之和小于K
- 有长度为N的数组A、B,每个数组中存储的浮点数已经升序排列。设计一个O(logn)时间的分治算法,找出这2n个数的中位数。证明算法的正确性。
解法:
- 求两个数组的A[n/2];
- 若相等,中位数就是A[n/2]
- 若A[n/2]>B[n/2],说明中位数在B[n/2: n]和A[1: n/2]里,递归;
- 反之同理
快速傅里叶变化*
Divide-and-conquer算法*
四、动态规划
应用条件
- 优化子结构
- 当一个问题的优化解包含了子问题的优化解时, 我们说这个问题具有优化子结构。
- 缩小子问题集合, 只需那些优化问题中包含的子问题, 降低实现复杂性
- 优化子结构使得我们能自下而上地完成求解过程
- 重叠子问题
- 在问题的求解过程中, 很多子问题的解将被多次使用
设计步骤
- 分析优化解的结构
- 递归地定义最优解的代价
- 自底向上地计算优化解的代价保存之, 并获取构造最优解的信息
- 根据构造最优解的信息构造优化解
题型1:编号动态规划
问题描述:输入为x1, x2, …, xn, 子问题是x1, x2, …,xi,子问题复杂性为O(n)
表示状态的方法:
- 状态i表示前i个元素构成的最优解,可能不包含第i个元素。
- 状态i表示在必须包含第i个元素的情况下前i个元素构成的最优解
最大不下降子序列问题
- 子序列是数字序列的子集合,且和序列中数字顺序相同,即递增子序列是其中数字严格增大的子序列
- Eg
- Input. 5; 2; 8; 6; 3; 6; 9; 7
- Output. 2; 3; 6; 9
- 优化子结构:假设最长递增子序列中包含元素ak,那么一定存在一组最优解,它包含了a1, a2, …, ak-1这个序列的最长递增子序列。
正确性? - 重叠子问题: ak和ak+1
- 子问题的表示:令dp[i]表示以第i个元素结尾的前i个元素构成序列的最长递增子序列的长度。
- 最优解递归表达式:
优化:
上面的算法的时间复杂度为O(n2)
分析:设Ai = min { aj | dp[j] == i},那么如果i > j,一定可以推出Ai ≥ Aj。
递推函数:dp[i] = max { j | Aj > ai} + 1; max{j | Aj ≥ ai}可以通过二分查找求出
题型2:划分动态规划
问题描述:输入为x1, x2, …, xn, 子问题为xi, xi+1,…, xj,子问题复杂性是O(n2)
解法:划分成两部分,取两部分分别的代价与两部分合并的代价之和为总代价
矩阵链乘问题
- 输入: <A1, A2, …, An>, Ai是矩阵
- 输出:计算A1×A2×…×An的最小代价方法
- 若A是p×q矩阵, B是q×r矩阵,则A×B的代价是O(pqr)
- 考虑到所有的k,优化解的代价方程为
三角剖分
- 一个多边形P的三角剖分是将P划分为不相交三角形的弦的集合

的优化三角剖分代价
的优化三角剖分代价
题型3:数轴动态规划
问题描述:输入为x1, x2, …, xn和数字C,子问题为x1, x2, …, xi, K(K≤C),子问题复杂性O(nC)
- 代价有限
- 获利最大
等价的整数规划问题
0-1背包问题
- 给定n种物品和一个背包,物品i的重量是wi,价值vi, 背包容量为C, 问如何选择装入背包的物品,使装入背包中的物品的总价值最大?
- 解法:每次计算前i个物品,使用容量j以内的最优解,依据上一次计算(无第i个物品)的情况,尝试放入第i个物品取最优值。
题型4:前缀动态规划
问题描述:输入为x1, x2, …, xn和y1, y2, …, ym,子问题为x1, x2, …, xi和y1, y2, …, yj,子问题复杂性是O(mn)
最长公共子序列问题(编辑距离)
- 优化子结构:设X=(x1, …, xm)、Y=(y1, …, yn) 是两个序列,Z=(z1, …, zk)是X与Y的LCS,我们有:
- ⑴ 如果 , 则 , Zk-1是Xm-1和Yn-1的LCS, 即 .
- ⑵ 如果 , 且 , 则Z是Xm-1和Y的LCS, 即
- ⑶ 如果 ,且 ,则Z是X与Yn-1的LCS,即
- 子问题重叠性


题型5:树形动态规划*
问题描述:输入是树,其子问题为子树,子问题复杂性是子树的个数。
树中独立集合问题
- 独立集合: 输入图T=(V,E),输出结点最大的子集合 ,满足E的每条边中两个顶点至多有一个在S之内。
- 解法思路:从下往上推导,对于任意一个点,若自己在独立集合中,则自己的儿子均不能在独立集合中,此时要取孙子的最优解之和;反之则取儿子最优解之和。
- 状态转移方程
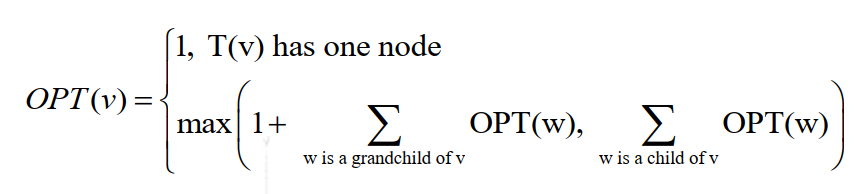
最优二分搜索树
任意两点最短路径问题
五、贪心算法
贪心选择性
若一个优化问题的全局优化解可以通过局部优化选择得到, 则该问题称为具有贪心选择性
优化子结构
若一个优化问题的优化解包含它的子问题的优化解, 则称其具有优化子结构
动态规划 vs 贪心算法
- 动态规划方法可用的条件
- 优化子结构
- 子问题重叠性
- 子问题空间小
- 贪心方法可用的条件
- 优化子结构
- 贪心选择性
可用贪心方法时, 动态规划方法可能不适用
可用动态规划方法时, 贪心方法可能不适用
例题
任务安排问题
- 输入:
- 输出: S的最大相容集合
- 贪心思想:为了选择最多的相容活动, 每次选fi最小的活动, 使我们能够选更多的活动
哈夫曼编码问题
- 优化编码树问题
- 输入: 字母表 C = {c1, c2, …, cn },频率表 F = {f(c1), f(c2), …, f(cn)}
- 输出: 具有最小B(T)的C前缀编码树
- 贪心思想:循环地选择具有最低频率的两个结点,生成一棵子树, 直至形成树
- 优化:堆
最小生成树问题
- 输入: 无向连通图G=(V, E), 权函数W
输出: G的最小生成树 - Kruskal
- CSDN:最小生成树(kruskal算法)
- 可加入边,边权最小的
- Prim
- 博客园:最小生成树-Prim算法和Kruskal算法
- 加入点相连的可加入边,边权最小的
拟阵*
六、搜索算法
深度优先搜索
略
广度优先搜索
略
搜索优化:爬山法——分支界限策略
- 爬山策略使用贪心方法确定搜索的方向,是优化的深度优先搜索策略,使用启发式测度来排序节点扩展的顺序
搜索优化:剪枝
人员安排问题
A*算法
A*算法与分支界限策略的比较
- 分支界限策略是为了剪掉不能达到优化解的分支,关键是“界限”
- A*算法的核心是告诉我们在某些情况下, 我们得到的解一定是优化解, 于是算法可以停止,试图尽早地发现优化解,经常使用Best-first策略求解优化问题
- 扩展 最小的点
- 计算 和 ,并得出新点的
- 当最小的 是汇T时,算法结束
七、平摊分析
在平摊分析中,执行一系列数据结构操作所需要时间是通过对执行的所有操作求平均而得出的
聚集方法
- 直接求平均
会计方法
- 在各种操作上定义平摊代价使得任意操作序列上存款总量是非负的,将操作序列上平摊代价求和即可得到这个操作序列的复杂度上界
| 实际代价 | 平摊代价 | |
|---|---|---|
| PUSH | 1 | 2 |
| POP | 1 | 0 |
| MULTIPOP | 0 |
例:二进计数器
显然:这个操作序列的代价与0-1或者1-0翻转发生的次数成正比
- 定义:
- 0-1翻转的平摊代价为2
- 1-0翻转的平摊代价为0
任何操作序列,存款余额是计数器中1的个数,非负
因此,所有的翻转操作的平摊代价的和是这个操作序列代价的上界
势能方法
如果我们将这些余额都与整个数据结构关联,所有的这样的余额之和,构成——数据结构的势能
- 如果操作的平摊代价大于操作的实际代价——势能增加
- 如果操作的平摊代价小于操作的实际代价,要用数据结构的势能来支付实际代价——势能减少
势能的定义:
- 对一个初始数据结构
执行n个操作,对操作i:
- 实际代价 将数据结构 变为
- 势函数 将每个数据结构 映射为一个实数
- 平摊代价 定义为:
例1:栈操作
平摊代价为栈内个数的变化值
例2:二进计数器
平摊代价为计数器中1的个数
如果我们执行了至少n=φ(k)次INCREMENT操作,则无论计数器中包含什么样的初始值,总的实际代价都是O(n)
动态表
略
八、图论算法
最短路径
优化子结构:最短路径包含最短子路径
证明: 如果某条子路径不是最短子路径,必然存在最短子路径,用最短子路径替换当前子路径,当前路径不是最短路径,矛盾。
最短路径算法的核心技术是松弛
Relax(u,v,w) {
if (d[v] > d[u]+w) then d[v]=d[u]+w;
}
Bellman-Ford
时间复杂度
BellmanFord()
// 初始化 d
for each v in V
d[v] = MAXINT;
d[s] = 0;
// 松弛: 进行 |V|-1 轮, 松弛每条边
for i=1 to |V|-1
for each edge (u,v) in E
Relax(u,v, w(u,v));
// 检验结果
for each edge (u,v) in E
if (d[v] > d[u] + w(u,v))
return “no solution”;
Dijkstra
Dijkstra(G)
// 初始化 d
for each v in V
d[v] = MAXINT;
d[s] = 0;
S = 空集;
Q = V;
while (Q ≠ 空集)
u = ExtractMin(Q);
S = S U {u};
for each v in u->Adj[]
// 松弛
if (d[v] > d[u]+w(u,v))
d[v] = d[u]+w(u,v);
Floyd
- 3重循环
- 中间点
- 松弛边点之一
- 松弛边点另一
D0 = W //初始化D
P = 0 // 初始化 P
for k = 1 to n
for i = 1 to n
for j = 1 to n
if (Dk-1[ i, j ] > Dk-1 [ i, k ] + Dk-1 [ k, j ] ) then
Dk[ i, j ] = Dk-1 [ i, k ] + Dk-1 [ k, j ]
P[ i, j ] = k;
else Dk[ i, j ] = Dk-1 [ i, j ]
二分图匹配
使用最大流算法
- 在左侧增加源S,S连接到所有二分图左侧点;
- 在右侧增加汇T,所有二分图右侧点连接到T;
- 每条边容量为1,单向边,从左向右;
- 使用最大流算法后,右侧点指向的左侧点即为匹配点;
网络流
网络:本质上是一张图

流
- 中间节点的进总量和出总量必须相等
- 源S和汇T满足:源的流出=汇的流入

余图
余图:
- 同样的结点,中间结点和s,t
- 对于每条边 e 满足 ce > f(e) 赋给权重 ce - f(e) (剩余容量)
- 对于每条边 e = (u,v) 给其逆向边(v,u)赋给权重 f(e) (剩余容量)

增广路径
给定图G中的流f, 及其对应的余图Gf
- 找到余图中的一条新流,该流通过一条没有重复结点的路径并且值和该路径上的最小容量相等(增广路径)
- 沿着路径更新余图

Ford-Fulkerson 算法
- 对于所有e初始化 f(e) = 0
- While 余图中存在s-t 路径 P
- 沿着路径P增广 f 得到新的 f 和新的余图
沿着P增广f :
- 找到路径的最小容量
- 沿着路径修改权重
最大流
FF算法可以求得最大流
最小割
- (A,B) – 图 G的割:
A,B 是结点的划分, s 在 A中, t 在 B中
是这个割的容量 - 性质:最小割等于最大流
例:c(A,B) = 50

保证
设FF-算法在流f上停止:
从s出发的 DFS 不包含 t,这意味着在余图中DFS经过的结点和其余结点之间割的容量是0
因此这个割中的每条边都被增广流逆转过,这意味着c(DFS,DFS’) = value(f)
根据 可得到f最大

九、字符串匹配算法
经典匹配
时间复杂度
略
指纹匹配 & Rabin-Karp算法
令字母表位 S={0,1,2,3,4,5,6,7,8,9}
令指纹为一个十进制数, 即, f(“1045”) = 1*103 + 0*102 + 4*101 + 5 = 1045
Fingerprint-Search(T,P)
fp = compute f(P)
f = compute f(T[0..m–1])
for s = 0 to n – m do
if fp = f return s
f = (f – T[s]*10m-1)*10 + T[s+m]
return -1

指纹算法前提:对m位数在O(1)时间内进行算术运算
若不可行,考虑Hash函数
Rabin-Karp-Search(T,P)
q = a prime larger than m
c = 10m-1 mod q // run a loop multiplying by 10 mod q
fp = 0; ft = 0
for i = 0 to m-1 // preprocessing
fp = (10*fp + P[i]) mod q
ft = (10*ft + T[i]) mod q
for s = 0 to n – m // matching
if fp = ft then // run a loop to compare strings
if P[0..m-1] = T[s..s+m-1] return s
ft =((ft – T[s]*c)*10 + T[s+m]) mod q
return –1
KMP算法
网上讲解太多了,搬运一下吧
BMH算法
- 基于经典算法,改为逆向匹配(从模式的最后一位开始匹配)
- 启发式:在不匹配之后,将T[s + m–1]对齐到模式P[0…m–2]中的最右出现
Trie树*

- 字符串集合: {bear, bid, bulk, bull, sun, sunday}
紧缩Trie树

后缀树*
一种包含文本所有后缀的紧缩trie树(或类似的结构)
