1.二叉搜索树的概念
一棵二叉搜索树是以一棵二叉树来组织的,这样的一棵树可以以链表的数据结构来表示,其中的每个结点就是一个对象。
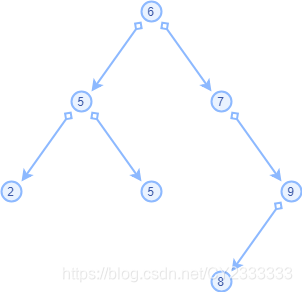
2.二叉搜索树结点对象的属性
(1)key(关键字,用于代表整个对象)
(2)基本数据和信息
(3)left、right和p,分别指向结点的左子结点,右子结点,父结点(父节点的使用较少时,可以省略)
class TreeNode {
int key; //关键字
TreeNode left; //左节点
TreeNode right; //右节点
TreeNode() {
}
TreeNode(int val) {
this.val = val; }
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}
3.二叉搜索树的最基本构造规则
对于任何结点node,其左子树的每一个结点的key不能大于node.key,其右子树的每一个结点的key不能小于node.key。这一点构造规则可以引出二叉搜索树的一个性质——如果childNode是node的左子树上的一个结点,则childNode.key<=node.key,同理,如果在右子树上,则childNode.key>=node.key。
4.二叉树搜索的遍历
(1)二叉树的遍历主要有2种方法,分别是BFS广度搜索遍历和DFS深度搜索遍历,其中广度搜索遍历的核心是对于队列这一数据结构的应用;深度搜索遍历有两种方式,一种是通过递归函数的设计进行遍历,另一种是利用栈这一数据结构进行遍历
1>DFS
//递归遍历
public void search(TreeNode root){
if(root==null)
return;
search(root.left);
search(root.right);
}
//利用栈进行遍历
public void search(TreeNode root){
public void search(TreeNode root) {
TreeNode node = root;
Stack<TreeNode> DFS = new Stack<>();
while (!DFS.isEmpty() || node != null) {
while (node != null) {
DFS.push(node);
node = node.left;
}
node = DFS.pop().right;
}
}
}
2>BFS
//利用队列进行遍历
public void search(TreeNode root){
TreeNode node=root;
Queue<TreeNode>DFS=new LinkedList<>();
DFS.offer(node);
while(!DFS.isEmpty()||node!=null){
node=DFS.poll();
if(node.left!=null)
DFS.offer(node.left);
if(node.right!=null)
DFS.offer(node.right);
}
}
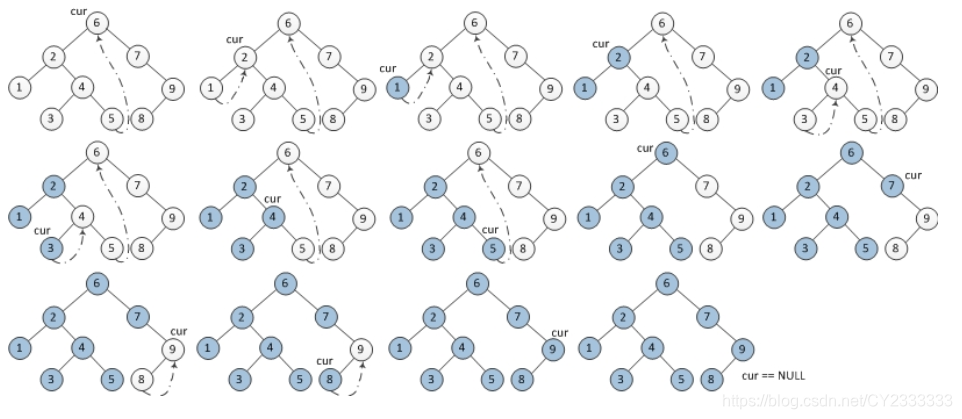
(2)二叉树遍历的高级算法:Morris算法。Morris算法极大的缩减了遍历二叉搜索树的空间复杂度,算法主要是利用了二叉搜索树中必定会存在的大量空结点(末端结点一定存在空结点),省去了栈或者队列。
算法的主要步骤:
1>.对于二叉搜索树的子结点node如果node无左孩子,则访问node的右孩子,如果node有左孩子,则找到node左子树上最右的节点(即node左子树中序遍历的最后一个节点),记为morrisBack。
2>.根据morrisBack的右孩子是否为空,进行如下操作——如果右孩子为空,则将其右孩子指向node然后访问的左孩子;如果右孩子不为空,说明我们已经遍历完node的左子树,我们将morrisBack的右孩子置空(为了不破坏二叉搜索树的结构),然后访问node的右孩子(回到子树的头结点或者访问右结点)
3>.重复上述操作,直至访问完整棵树。
Morris算法图示:
配图来源
class Solution {
public void Search(TreeNode root) {
TreeNode node=root;
TreeNode morrisBack;
while(node!=null){
if(node.left!=null){
morrisBack=node.left;
while(morrisBack.right!=null&&morrisBack.right!=node)
morrisBack=morrisBack.right;
if(morrisBack.right==null){
morrisBack.right=node;
node=node.left;
}
else{
morrisBack.right=null;
node=node.right;
}
}
else
node=node.right;
}
}
}
5.二叉树的遍历分类
二叉树的遍历算法有三种特殊的形式,分别是前序遍历、中序遍历、后续遍历。
对于前序遍历而言,就是对于当前节点,先访问该节点,然后访问他的左孩子,最后访问他的右孩子。
对于中序遍历而言,就是对于当前结点,先访问它的左孩子,然后访问该结点,最后访问它的右孩子。(对于二叉搜索树来说,中序遍历是以结点key值升序为顺序进行访问的,可以得到以结点key值升序排列的数组)
对于后续遍历而言,就是对于当前结点,先访问它的左孩子,然后访问它的右孩子,最后访问该结点。
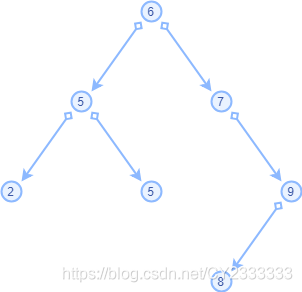
以上图二叉搜索树为例:
前序遍历:
//递归算法
class Solution {
public void search(TreeNode root) {
if(root ==null)
return;
System.out.print(root.val+" ");
search(root.left);
search(root.right);
}
}
//非递归算法
public void search(TreeNode root) {
TreeNode node = root;
Stack<TreeNode> DFS = new Stack<>();
while (!DFS.isEmpty() || node != null) {
while (node != null) {
System.out.print(node.val+" ");
DFS.push(node);
node = node.left;
}
node = DFS.pop().right;
}
}
输出结果:6 5 2 5 7 9 8
中序遍历:
//递归算法
class Solution {
public void search(TreeNode root) {
if(root ==null)
return;
search(root.left);
System.out.print(root.val+" ");
search(root.right);
}
}
//非递归算法
public void search(TreeNode root) {
TreeNode node = root;
Stack<TreeNode> DFS = new Stack<>();
while (!DFS.isEmpty() || node != null) {
while (node != null) {
DFS.push(node);
node = node.left;
}
node = DFS.pop();
System.out.print(root.val+" ");
node=node.right;
}
}
输出结果:2 5 5 6 7 8 9
后序遍历:
//递归算法
class Solution {
public void search(TreeNode root) {
if(root ==null)
return;
search(root.left);
search(root.right);
System.out.print(root.val+" ");
}
}
//非递归算法
public void search(TreeNode root) {
HashMap<TreeNode,Integer>check=new HashMap<>();
TreeNode node = root;
Stack<TreeNode> DFS = new Stack<>();
while (!DFS.isEmpty() || node != null) {
while (node != null) {
check.put(node,1);
DFS.push(node);
node = node.left;
}
node=DFS.peek();
if(check.get(node)==1){
check.put(node,2);
node=node.right;
}
else{
DFS.pop();
System.out.print(node.val+" ");
node=null;
}
}
}
输出结果:2 5 5 8 9 7 6