算法笔记复习
3.0 常用函数以及定义
3.1 常用函数
ctype.h
- isdigit(int ch) 是数字返回非零,否则返回0
- isalpha(int ch) 是字母返回非零,否则返回0
- isalnum(int ch) 是数字或字母返回非零,否则返回0
- islower(int ch) 是小写字母返回非零,否则返回0
- isupper(int ch) 是大写字母返回非零,否则返回0
- int tolower(int ch) 返回大写字母的小写形式
- int toupper(int ch) 返回小写字母的大写形式
cstring
- int strcmp(const char*s1,const char *s2) 比较字符串s1,s2,s1=s2时返回0,s1<s2时返回负值,s1>s2时返回正值
- void memset(void *s,int ch,size_t n) 用ch填充s中的n个字节,用于对数组的快速初始化,通常初始化为0或1
- char *strcpy(char *dest,const char *src) 将含有结束符的字符串src复制到dest中(dest要有足够的空间),并返回指向dest的指针
- unsigned int strlen(char *s) 返回截止到结束符的字符串s的长度
algorithm
- max(a,b) 返回a,b中较大的那一个
- min(a,b) 返回a,b中较小的那一个
- abs(a) 返回a的绝对值,a必须为整型,浮点型需要用math.h下的fabs
- swap(a,b) 交换a,b的值
- reverse(a,a+n) 将a中元素倒序,一般用于数组,template的方法暂时还不会用-_-,a为数组首地址,n为数组长度
- fill(a,a+n,value) 将[a,a+n)的元素填充值value,可用template,memset一般填1或0,这个可以填充其他值
- sort(a,a+n,f) 将[a,a+n)中的元素按照比较函数f进行排序,可用template
- lower_bound(a,a+n,key) 返回[a,a+n)中第一个大于等于key的位置,如果所有元素小于key,返回末地址,末地址是正好越界的!查找方法为二分查找!
- upper_bound(a,a+n,key) 返回[a,a+n)中大于key的第一个位置,没找到返回末地址,末地址正好越界!查找方法为二分查找!
- max_element(a,a+n) 查找[a,a+n)最大值所在地址
- min_element(a,a+n) 查找[a,a+n)最小值所在地址
cmath
- ceil(x) 对x向上取整
- floor(x) 对x向下取整
- fabs(x) 返回x的绝对值
- sqrt(x) 返回x的开方
- pow(x,y) 返回x的y次方
- round(x) 将x四舍五入取整
- sin(x),cos(x),tan(x) x为弧度制的角度
- asin(x),acos(x),atan(x)
- log(x) 返回以自然指数为底的x的对数
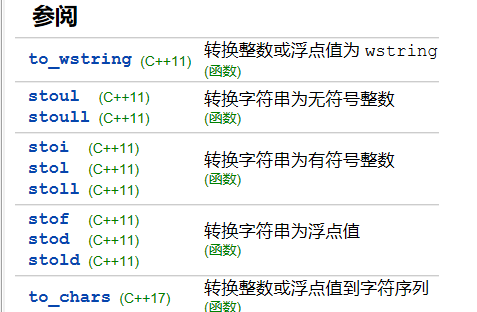
string
函数多种可以解析字符串为浮点数,整数的方法
stoi int stoi (const string& str, size_t* idx = 0, int base = 10);
std::stoi, std::stol, std::stoll
将字符串转换为整数解析str将其内容解释为指定基数的整数,并以int值的形式返回。
#include <iostream>
#include <string>
int main()
{
std::string str1 = "45";
std::string str2 = "3.14159";
std::string str3 = "31337 with words";
std::string str4 = "words and 2";
int myint1 = std::stoi(str1);
int myint2 = std::stoi(str2);
int myint3 = std::stoi(str3);
// 错误: 'std::invalid_argument'
// int myint4 = std::stoi(str4);
std::cout << "std::stoi(\"" << str1 << "\") is " << myint1 << '\n';
std::cout << "std::stoi(\"" << str2 << "\") is " << myint2 << '\n';
std::cout << "std::stoi(\"" << str3 << "\") is " << myint3 << '\n';
//std::cout << "std::stoi(\"" << str4 << "\") is " << myint4 << '\n';
}
std::atoi, std::atol, std::atoll
定义于头文件
需要将字符串使用c_str进行转换
int atoi( const char *str );
long atol( const char *str );
long long atoll( const char *str );
4.0 算法高效技巧
4.1 打表法的使用规则
打表法:典型用空间换时间,一般指将所有可能需要用到的结果事先计算出来
后面需要的时候可以直接查表获得,
问题出现的种类:
| 大概有三种可能 |
|---|
| 1.在程序中一次性计算出所有需要用到的结果,之后的查询直接读取这些结果 |
| 2.在程序B中分一次或者多次计算出所有需要的结果,手动把结果写在程序A的数组中,然后在程序A就可以直接使用这些结果 |
| 3.对一些不会做的题目,先用暴力法计算小范围数据结果,再找规律 |
4.2 活用递推
B1040 有几个PAT (25分)
字符串 APPAPT 中包含了两个单词 PAT,其中第一个 PAT 是第 2 位(P),第 4 位(A),第 6 位(T);第二个 PAT 是第 3 位(P),第 4 位(A),第 6 位(T)。
现给定字符串,问一共可以形成多少个 PAT?
输入格式:
输入只有一行,包含一个字符串,长度不超过105,只包含 P、A、T 三种字母。
输出格式:
在一行中输出给定字符串中包含多少个 PAT。由于结果可能比较大,只输出对 1000000007 取余数的结果。
输入样例:
APPAPT
输出样例:
2
解题步骤:要想知道构造多少个PAT,那么遍历字符串之后对于每一个位置的A来说,它前面P的个数和它后面T的个数乘积,就是能构造PAT的个数,然后把每一个A的结果相加即可.怎么统计那,这个属于双指针的方法了,在遇到A之前,如果遇到T则减去Count_T–;如果遇到P则统计Count_P个数,一但遇到A,则累加个数Count_T*Count_P;
1000000007 取余数这个是为什么?
大概是:
- 1000000007是一个质数(素数),对质数取余能最大程度避免冲突~
- int32位的最大值为2147483647,所以对于int32位来说1000000007足够大
- int64位的最大值为2^63-1,对于1000000007来说它的平方不会在int64中溢出
- 所以在大数相乘的时候,因为(a∗b)%c=((a%c)∗(b%c))%c,所以相乘时两边都对1000000007取模,再保存在int64里面不会溢出
这里我们知道乘法个模运算的优先级是一样的
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3dEPslOV-1598617566938)(算法笔记复习.assets/image-20200806085515202.png)]
#include<iostream>
#include<string>
using namespace std;
int main(){
string str;
cin>>str;
int len=str.size(),result= 0 ,Count_T=0,Count_P=0;
for(int i=0;i<len;i++){
if(str[i]=='T'){
Count_T++;
}
}
for(int i=0;i<len;i++){
if(str[i]=='P')Count_P++;
if(str[i]=='T')Count_T--;
if(str[i]=='A') result=(result+(Count_T*Count_P))%1000000007;
}
cout<< result;
return 0;
}
相似题型:A1093,B1045,A1101
B1045 快速排序
著名的快速排序算法里有一个经典的划分过程:我们通常采用某种方法取一个元素作为主元,通过交换,把比主元小的元素放到它的左边,比主元大的元素放到它的右边。 给定划分后的 N 个互不相同的正整数的排列,请问有多少个元素可能是划分前选取的主元?
例如给定 N = 5 N = 5 N=5, 排列是1、3、2、4、5。则:
- 1 的左边没有元素,右边的元素都比它大,所以它可能是主元;
- 尽管 3 的左边元素都比它小,但其右边的 2 比它小,所以它不能是主元;
- 尽管 2 的右边元素都比它大,但其左边的 3 比它大,所以它不能是主元;
- 类似原因,4 和 5 都可能是主元。
因此,有 3 个元素可能是主元。
输入格式:
输入在第 1 行中给出一个正整数 N(≤105); 第 2 行是空格分隔的 N 个不同的正整数,每个数不超过 109。
输出格式:
在第 1 行中输出有可能是主元的元素个数;在第 2 行中按递增顺序输出这些元素,其间以 1 个空格分隔,行首尾不得有多余空格。
输入样例:
5
1 3 2 4 5
输出样例:
3
1 4 5
思路::对原序列sort排序,逐个⽐较,当当前元素没有变化并且它左边的所有值的最⼤值都⽐它⼩的时候就可以认为它⼀定是主元(很容易证明正确性的,毕竟⽆论如何当前这个数要满⾜左边都⽐他⼤右边都⽐他⼩,那它的排名【当前数在序列中处在第⼏个】⼀定不会变)
就好像:一个符合升序的数组中插入一些混乱的值一样
两个条件卡住,就能轻松找到该数字
一个是符合排序之后的序列;
一个是数组中不能出现逆序;
#include<iostream>
#include<algorithm>
#include<cstdio>
int dp[100100];
int cnt=0;
using namespace std;
int main(){
int n,a[100100],b[100100],maxn=0;
cin>>n;
for(int i=0;i<n;i++){
cin>>a[i];
b[i]=a[i];
}
sort(a,a+n);
for(int i=0;i<n;i++){
if(a[i]==b[i]&&b[i]>maxn){
dp[cnt++]=b[i];
}
if(b[i]>maxn){
maxn=b[i];
}
}
cout<<cnt<<endl;
for(int i=0;i<cnt;i++){
if (i != 0) printf(" ");
printf("%d",dp[i]);
}
cout<<endl;
return 0;
}
5.0 cpp标准模板库
需要注意的是在STL容器之中,除了vector和string,其他容器都不支持*(it+i)的操作,只能使用迭代器访问
5.1 vector特点
没有find()函数,用来存储临接表
1.vector的定义
vector name;
2.vector容器元素的访问,(通过下标和通过迭代器访问)
3.vector常用函数解析
(1)push_back添加元素
(2)pop_back()删除元素0.
(3)size()
(4)clear()清空元素
(5)insert(it,x)向it处插入元素x
(6)erase()
- 删除单个元素,erase(it)
- 删除一个区间内的所有元素,erase(first,last]
5.2 set特点
内部自动有序,且不含重复元素的容器,
1.set定义
set name;
和vector的定义类似
2.set容器内元素的访问
set::iterator it;
set::iterator it;
3.常用函数解析
(1)insert(x)可以自动递增,排序和去重
(2)find (x)返回对应x的迭代器
(3)erase()同上可以删除一个,可以删除一个区间
5.3 string
可以使用find函数
直接上string常用函数
(1)operator+=
可以将两个字符串拼接起来
compare operator
两个string类型可以直接使用=.!=,<.<=,>,>=比较大小比较规则是字典序
str.find(str2)可以直接返回str2在str中出现的位置
replace
str.replace(pos,len,str2),从pos位置开始,长度为len的子串替换
这里做一个题
A1060
1060 Are They Equal (25分)
If a machine can save only 3 significant digits(有效数字), the float numbers 12300 and 12358.9 are considered equal since they are both saved as 0.123× 1 0 5 10^{5} 105 with simple chopping. Now given the number of significant digits on a machine and two float numbers, you are supposed to tell if they are treated equal in that machine.
Input Specification:
Each input file contains one test case which gives three numbers N, A and B, where N (<100) is the number of significant digits, and A and B are the two float numbers to be compared. Each float number is non-negative, no greater than 10100, and that its total digit number is less than 100.
Output Specification:
For each test case, print in a line YES if the two numbers are treated equal, and then the number in the standard form 0.d[1]...d[N]*10^k (d[1]>0 unless the number is 0); or NO if they are not treated equal, and then the two numbers in their standard form. All the terms must be separated by a space, with no extra space at the end of a line.
Note: Simple chopping is assumed without rounding.
Sample Input 1:
3 12300 12358.9
Sample Output 1:
YES 0.123*10^5
Sample Input 2:
3 120 128
Sample Output 2:
NO 0.120*10^3 0.128*10^3
思路:截取len为字符串进行比较
我们需要注意的是比如 3位有效数字,给出的数字是2,就需要补0了
给出的第一个数字n,使我们需要保留的有效数字
几组容易错的的数字
#include<iostream>
#include<sstream>
#include<string>
using namespace std;
int n;
string print(string s,int &e)
{
int k=0;
//去掉前导0
while(s.size()>0&&s[0]=='0'){
s.erase(s.begin());
}
//去掉前导0,后遇到小数点的话,这个数字为小数
if(s[0]=='.'){
s.erase(s.begin()); //去掉小数点
while(s.length()>0&&s[0]=='0'){
s.erase(s.begin());
e--;
}
}else{
//去掉前置0,还有数字,我们继续找点"."
while(k<s.size()&&s[k]!='.'){
k++;
e++;
}
if(k<s.size()){
//123.123,遇到"."了,我们需要继续往下找
s.erase(s.begin()+k); //0+k删除掉'.'
}
}
// 000.000
if(s.size()==0){
e=0; //说明数字是0,指数为0
}
// 我们开始截取123
string res;
int num=0;
k=0;
// 假如是0的话,我们知道,也只要返回一个n大小的“000”就行
while(num<n)
{
if(k<s.size()) res+=s[k++];
else res+='0';
num++;
}
return res;
}
int main()
{
string s1,s2,s3,s4;
int e1,e2;
cin>>n>>s1>>s2;
s3=print(s1, e1);
s4=print(s2, e2);
if(s3 == s4&&e1 == e2){
cout<<"YES 0."<<s3<<"*10^"<<e1<<endl;
}else{
cout<<"NO 0."<<s3<<"*10^"<<e1<<" 0."<<s4<<"*10^"<<e2<<endl;
}
return 0;
}
6.0 搜索专题
6.1 深度优先搜索Depth First Search
深度搜索是一种枚举所有完整路径以遍历所有情况的搜索方法
6.1.1背包问题
有n件物品,每件物品的重量为w[i],价值为c[i].现在需要选出若干件物品放入一个容量为v的背包中,使得在选入背包的物品重量和不超过容量V的前提下,让背包中的物品价值之和最大,求最大价值(1<=n<=20)

const int maxn=30;
//物品件数n,背包容量V,最大价值maxValue
int n,V,maxValue=0 ;
//每件物品的重量,每件物品的价值
int w[maxn],c[maxn];
/*
时间复杂度为n^2倍数
*/
void DFS(int index,int sunW,int sumC)
{
//已经完成对n件物品的选择(死胡同)
if(index == n){
if(sumW<=V&&sumC>maxValue) {
maxValue=sumC;
}
return n;
}
//岔道口
DFS(index + 1, sumW , sumC) ; //不选第index件物品,不把价值放入
DFS(index + 1,sumW+w[index],sumC+c[index]);
}
这种方法,我们需要注意的是,在递归终止条件,只有达到背包容量n之后,才去判断递归是否终止,有些时候还没有装到n个物品,总重量就会超重,所以我们在这里直接进行判断,再放下一个物品的递归式子之前就判断,是否超重,这种通过题目条件的限制来节省DFS计算量的方法称做剪枝
测试数据
5 8
3 5 1 2 2
4 5 2 1 3
#include<iostream>
#include<cstdio>
using namespace std;
const int maxn=30;
//物品件数n,背包容量V,最大价值maxValue
int n,V,maxValue=0 ;
//每件物品的重量,每件物品的价值
int w[maxn],c[maxn];
/*
时间复杂度为n^2倍数
*/
void DFS(int index,int sumW,int sumC)
{
//已经完成对n件物品的选择(死胡同)
if(index == n){
if(sumW<=V&&sumC>maxValue) {
maxValue=sumC;
}
return ; //本次递归终止
}
//岔道口
DFS(index + 1, sumW , sumC) ; //不选第index件物品,不把价值放入
DFS(index + 1,sumW+w[index],sumC+c[index]);
}
/*
减少递归次数
*/
void DFS_1(int index,int sumW,int sumC)
{
if(index==n){
return ; //本次递归终止
}
DFS_1(index+1,sumW,sumC); //不选第index件物品
if(sunW + w[index]<=V){
if(sunC+c[index]>maxValue)
{
maxValue= sunC+c[index];
}
// 进入到
DFS_1(index+1,sumW+c[index],sumC+c[index]);
}
}
int main(){
cin>>n>>V;
// 输入每件物品的重量
for(int i=0;i<n;i++){
cin>>w[i];
}
// 输入每件物品的价值
for(int i=0;i<n;i++){
cin>>c[i];
}
DFS(0,0,0);
cout<<"该背包可以装入的最大价值为: "<<maxValue<<endl;
return 0;
}
6.1.2 枚举问题
给定一个序列,枚举这个序列的所有子序列(可以不连续),枚举所有序列的目的很明显,可以从中选择一个"最优"的子序列,满足每个最优条件
显然,这个问题也等价于枚举从N个整数中选择K个数的所有方案
所有给定问题:给出N个整数(有可能是负数),从中选择k个数,使得k个数字恰好等同于一个数字X,会出现多种方案,我们选择其中平方和最大的数字进行计算
#include<iostream>
#include<vector>
using namespace std;
const int maxn=30;
//序列A中共N个数字,选k个数使得和为x,我们选出符合条件K个数中最大平方和maxSumSqu
int n , k , x ,maxSumSqu = -1,A[maxn];
//我们接下来定义存放两种方法,一个是符合条件数,一个是符合条件数字的平方和
vector<int> temp , ans;
/*
函数的四个参数 1.当前处理index号整数 2.当前已选整数个数nowK
3.当前已选整数之和为sum,4.当前以选整数平方和为sumSqu
*/
void DFS(int index,int nowK,int sum,int sumSqu)
{
if(nowK==k&&sum==x){
if(sumSqu>maxSumSqu){
maxSumSqu=sumSqu;
ans=temp; //更新方案
}
return;
}
// 已经处理了n个数,或者超过k个数,或者和超过x,所有出错情况
if(index == n||nowK > k|| sum > k) return;
//没有出错,需要进行选择下一步的情况
//选index号数
temp.push_back(A[index]);
DFS(index+1,nowK+1,sum+A[index],sumSqu+A[index]*A[index]);
// 不选index号数
DFS(index+1,nowK,sum,sumSqu);
}
// 主函数
int main(){
int A[4]={
2,3,3,4};
n=4,k=2,x=6;
DFS(0,0,0,0);
for(int i=0;i<ans.size();i++){
cout<<ans[i]<<" ";
}
return 0;
}
6.2 广度优先搜索Breadth First Search
宽度优先搜索算法(又称广度优先搜索)宽度优先搜索算法(又称广度优先搜索)是最简便的图的搜索算法之一,这一算法也是很多重要的图的算法的原型。
我们先看一个例题
1.0 矩阵中块的个数
 题意:若干1是相邻的,符合上下左右
题意:若干1是相邻的,符合上下左右
//
// Created by jiayadong on 2020/8/24.
//
#include<iostream>
#include<queue>
using namespace std;
const int maxn=100;
//给出上下左右,的相对坐标为,快速判断,点关系
struct node
{
int x,y;
} Node;
int n,m;
int matrix[maxn][maxn];
bool inq[maxn][maxn]={
false};
//增量数组
int X[4]={
0,0,1,-1};
int Y[4]={
1,-1,0,0};
/**
* 函数含义:判断函数是否需要访问
* @param x
* @param y
* @return
*/
bool judge(int x,int y){
// 越界返回false
if (x >=n ||x<0||y>m||y<0) return false;
// 当前位置为值为0,或者已经被访问过了
if (matrix[x][y]==0 ||inq[x][y] == true) return false;
// 以上都不满足,返回true
return true;
}
//BFS函数访问位置(x,y)所在的块,将该快中所以"1"的inq都设置为true
void BFS(int x,int y)
{
queue<node> Q;
Node.x=x,Node.y=y;
// 将结点node入队
Q.push(Node);
inq[x][y] = true; //设置点已经入队
while (!Q.empty()){
node top=Q.front(); //取出队首
Q.pop(); //队首元素出队
for(int i=0;i<4;i++)
{
int newX=top.x+X[i];
int newY=top.y+Y[i];
if(judge(newX,newY)) {
// 新坐标符合规则,入队
Node.x=newX,Node.y=newY;
Q.push(Node);
// 将这个位置的结点加入队列中
inq[newX][newY] = true;
}
}
}
}
//主函数
int main(){
cin>>n>>m;
for(int i=0;i< n;i++)
{
for(int j=0;j< m; j++)
{
cin>>matrix[i][j];
}
}
int ans=0;//存放块数
// 枚举每一个位置
for(int i=0;i<n;i++)
{
for(int j=0;j<m;j++)
{
// 判断每一个1
if (matrix[i][j] == 1 && inq[i][j] == false){
ans++;
BFS(i,j);
}
}
}
cout<<"该矩阵一共多少个快: "<<ans<<endl;
return 0;
}
2.0 迷宫问题
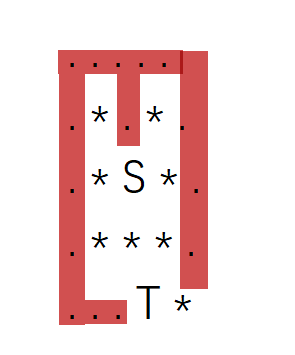
本题中,由于求得是最少步数,而BFS是通过层数的顺序来遍历的,因此可以从起点S开始技术遍历的层数,那么在到达终点T时的层数就是需要求解的起点到达终点T的最小步数
测试数据:
5 5
. . . . .
. * . * .
. * S * .
. * * * .
. . . T *
2 2 4 3
//
// Created by jiayadong on 2020/8/25.
//
#include <iostream>
#include <queue>
using namespace std;
const int maxn=100;
/**
* 定义位置,以及所在层数
*/
struct node{
int x,y;
int step; //层数
} S,T,Node;
int n,m;
//迷宫信息
char maze[maxn][maxn];
//位置是否访问过
bool inq[maxn][maxn];
//上,下,右,左
int X[4]={
0,0,1,-1};
int Y[4]={
1,-1,0,0};
/**
* 检测插入位置是否有效
* @param x
* @param y
* @return bool
*/
bool test(int x, int y)
{
if (x>=n||x<0||y>=m||y<0) return false;
if (maze[x][y]=='*') return false;
if (inq[x][y] == true) return false;
return true; //有效位置
}
/**
*
* @return
*/
int BFS()
{
queue<node> q; //定义队列
q.push(S); //初始启动
while (!q.empty()){
node top= q.front(); //取出队首元素
q.pop();
if (top.x==T.x && top.y==T.y){
return top.step;
}
// 循环四次,得到四个相邻位置
for(int i=0;i<4;i++)
{
int newX=top.x+X[i];
int newY=top.y+Y[i];
//该位置有效
if (test(newX,newY)){
// 设置Node的坐标为x,y
Node.x=newX,Node.y=newY;
Node.step=top.step+1;
q.push(Node);
// 标记访问位置,以及入列
inq[newX][newY] =true;
}
}
}
return -1;
//无法到达终点T时返回-1;
}
int main(){
cin>>n>>m;
for (int i = 0; i <n ; ++i) {
for(int j=0;j<m;j++)
{
cin>>maze[i][j];
}
}
cin>>S.x>>S.y>>T.x>>T.y;
// 初始这个参数为0
S.step=0;
cout<<BFS();
return 0;
}
2.0 使用队列小技巧
使用STL的queue时,元素入队的push操作只是制作了该元素的一个副本入队,因此在入队后对元素的修改不会影响队列中的副本,而对副本的修改也不会影响本来元素
//
// Created by jiayadong on 2020/8/25.
//
/**
* 用来检测queue是否能修改数据
*/
#include <iostream>
#include <queue>
using namespace std;
struct node{
int data;
}a[10];
int main(){
queue<node> q;
for(int i=1;i<=3;i++)
{
a[i].data=i;
q.push(a[i]);
}
// 尝试直接把队首元素修改为100
node top= q.front();
top.data=100;
cout<<a[1].data<<a[2].data<<a[3].data<<endl;
a[1].data=200;
node top1= q.front();
cout<<top1.data<<endl;
return 0;
}
所以说我们使用队列,对队列进行修改而不仅仅是访问的时候,队列中存放的元素最好不要是元素本身,而是它们的编号(如果是数组的话则是下标)
//
// Created by jiayadong on 2020/8/25.
//
#include <iostream>
#include <queue>
using namespace std;
struct node{
int data;
}a[10];
int main(){
queue<int> q;
for(int i=1;i<=3;i++)
{
a[i].data=i;
q.push(i);
}
a[q.front()].data=100;
cout<<a[1].data<<endl;
return 0;
}
7.0 树的总结
7.1 树的性质
树的七种比较重要的性质
- 树可以没有结点,这种情况下把树称为空树(empty tree)
- 树的层次(layer) 从根节点算起,根节点为第一层,根节点子树的根节点为第二层,依次类推
- 把节点的子树颗数称为结点的度(degree),而树中结点的最大度称为树的度(也称为树的宽度)
- 由于一条边连接两个顶点,且树中不存在环,因此对有n个结点的树,边数一定是n-1.反推—>满足连通,边数等于顶点数减一的结构一定是一颗树
- 叶子节点被定义为度为0的结点因此,树中只有一个结点时根节点也是叶子节点
- 节点的深度(depth)是从根节点(深度为1)开始自顶向下最层累加至该节点时的深度值,节点的高度(height)是指从最底层叶子结点开始自顶向上逐层累计额至该结点的最高值.树的深度和高度相等
二叉树的性质
- 可以没有根节点,是一颗空树
- 可以有根节点,左右子树组成,且左子树和右子树都是二叉树
特殊的几种二叉树
- 满二叉树.每一层的节点数都达到了当层能达到的最大结点数
- 完全二叉树:除了叶子节点以外,其他层都达到当层能达到的最大结点数,且最后一层连续存在若干结点
7.2 树的存储结构与基本操作
- 二叉链表存储
struct node{
typename data;
node *lchild;
node *rchild;
};
- 二叉树根节点
//一般设为空,因为建树前可能不存在
node *root=NULL;
二叉树结点的查找和修改
我们常说二叉树的递归定义,其中包含了二叉树递归的两个重要元素
- 递归式—>对左右子树分别递归
- 递归边界—>当前结点为空时到达死胡同
/**
* 二叉树的查找修改
* @param root
* @param x
* @param newdata
*/
void search(node *root,int x,int newdata)
{
if (root==NULL){
return; //空树,死胡同(递归边界)
}
if (root->data==x){
root->data=newdata;
}
search(root->lchild,x,newdata);
search(root->rchild,x,newdata);
}
二叉树的插入
二叉树的插入位置:一定是递归查找过程之中,选择左子树或者右子树中的一颗子树进行递归,且最后到达空树(死树)的地方,就是查找失败的地方,也就是结点需要插入的地方
在二叉树的插入过程中,我们使用了函数参数的引用传递目的是为了修改指针root,插入一个指针,但是在查找的时候,我们是为了查找指针root指向的内容
/**
* 将数据插入到二叉树的数据域中
* @param root 引用传递
* @param x
*/
void insert(node* &root,int x)
{
if (root ==NULL){
root=newNode(x); //有一个申请新结点函数
return;
}
insert(root->lchild,x);
insert(root->rchild,x);
}
二叉树的创建
边创建二叉树,边插入数据会更加方便
/**
* 二叉树的建立
* @param data
* @param n
* @return 头结点
*/
node * Create(int data[],int n)
{
node *root=NULL;
for (int i = 0; i <n ; ++i) {
insert(root,data[i]);
}
return root;
}
7.3 树的静态实现
静态二叉链表是指,结点的左右指针域使用int型替代,所以需要建立一个大小为结点上限数组个数的node型数组,所有动态生成的结点都直接使用数组中的结点,所有对指针的操作都改为对数组下标的访问
struct node{
int data;
int lchild;
int rchild;
}Node[maxn];
在这种定义之下,结点动态生成就可以转变为如下的静态指定
/**
*
* @param v
* @return index++返回下一个结点个位置
*/
int newNode(int v)
{
Node[index].data = v;
Node[index].lchild= -1;
Node[index].rchild= -1;
return index++;
}
7.3.1查找,插入函数
/**
* 插入,root为根节点在数组中的下标
* @param &root
* @param x
*/
void insert(int &root, int x)
{
if (root ==-1){
root = newNode(x);
return;
}
//这里是说,如果插入左子树的过程之中
//左子树建立,右子树建立
insert(Node[root].lchild,x);
insert(Node[root].rchild,x);
}
/**
* 二叉树的建立,函数返回根节点root的下标
* @param data
* @param n
* @return root
*/
int Create(int data[],int n)
{
int root = -1;
for(int i=0;i<n;i++)
{
insert(root , data[i]);
}
return root;
}
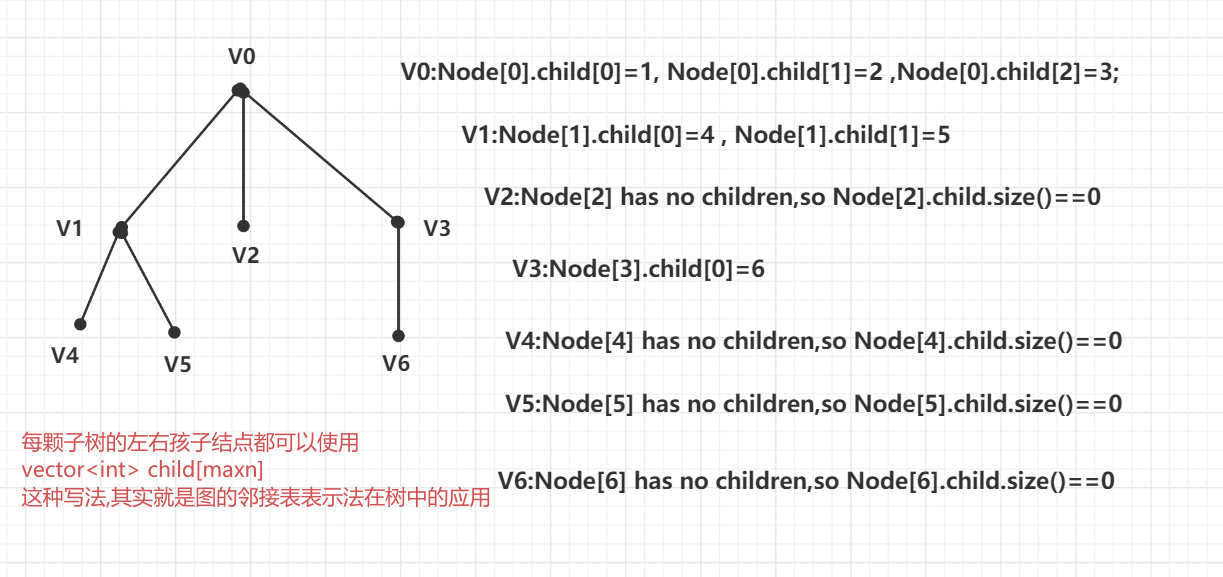
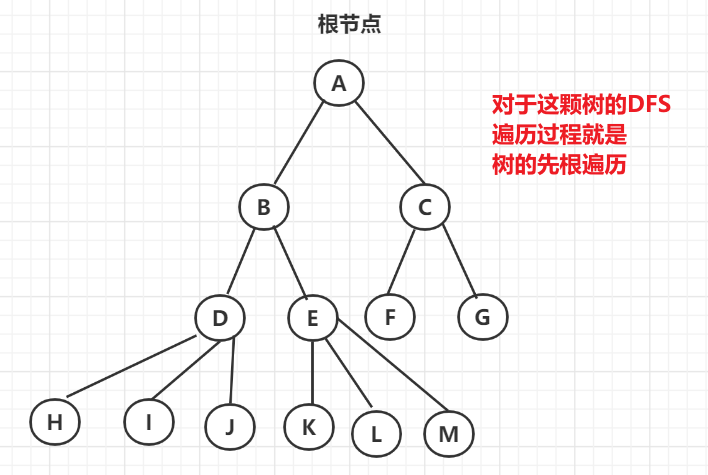
7.3.2 树的先根遍历
先遍历根节点再遍历若干子树
/**
* 树的先根遍历
* 问题:为什么没有递归边界
* @param root
*/
void preOrder(int root)
{
cout<<Node[root].data;
for(int i=0;i<Node[root].child.size();i++)
{
// 递归问节点root的所有子节点
preOrder(Node[root].child[i]);
}
}
 #### 7.3.3 树的层序遍历
#### 7.3.3 树的层序遍历
树的层序遍历与二叉树的层序遍历的思路一致的,即总是从树根开始,一层一层遍历
方法:树的层序遍历的实现方法和二叉树相似,一个队里来存放结点在数组中的下标,每次取出队首元素来访问,并将其所有子节点加入队列,直到队列为空
/**
* 树的层数遍历
* @param root
*/
void LayerOrder(int root)
{
queue<int> Q;
// 将
Q.push(root);
while (!Q.empty()){
int front=Q.front();
// 访问当前元素的数据域
cout<<Node[front].data<<" ";
Q.pop();
for(int i=0;i<Node[front].child.size();i++)
{
// 将当前结点的所有子节点入队
Q.push(Node[front].child[i]);
}
}
}
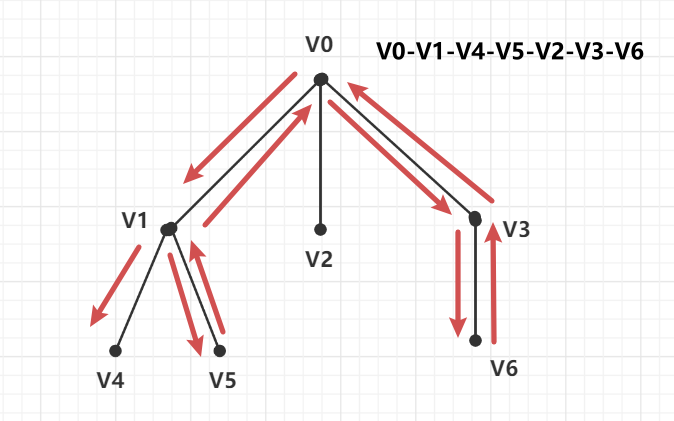
7.3.4 从树的遍历看DFS与BFS
- 深度优先遍历(DFS)与先根遍历
前面我们在DFS进行迷宫问题搜索的时候
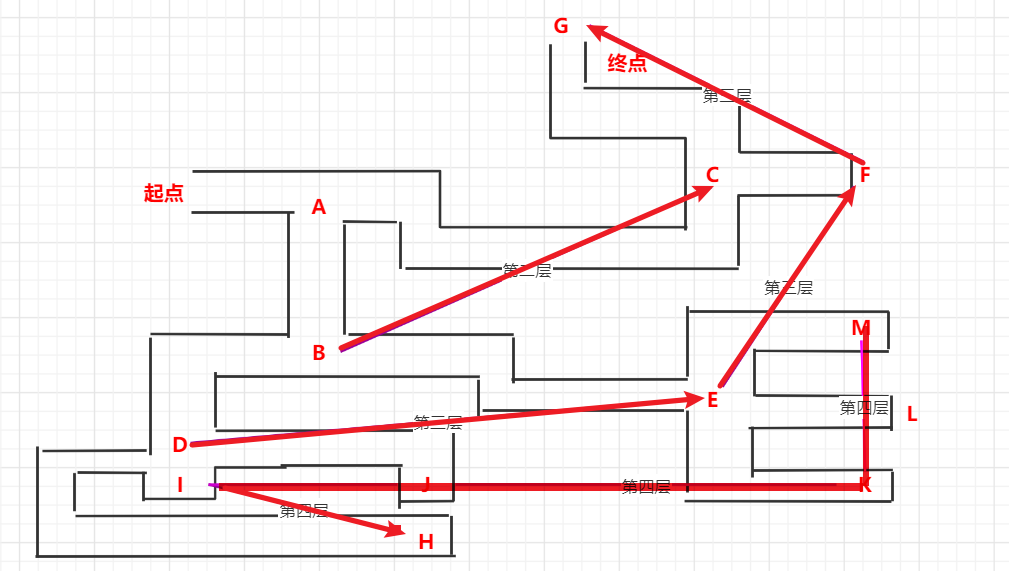
可以把岔道口和死胡同都当作节点,并将它们的关系表示出来
所以我们在遇到一些要使用DFS做的题目,可以把状态作为树的结点,然后问题就会转换成直观的对树进行先根遍历的问题
如果想要得到树的某些信息,也可以借用DFS深度作为第一关键词的思想对结点进行遍历,例如求解叶子节点的带权路径和(即从根节点到叶子节点的路径上的结点点权路径),
- 广度优先搜索(BFS)与层序遍历
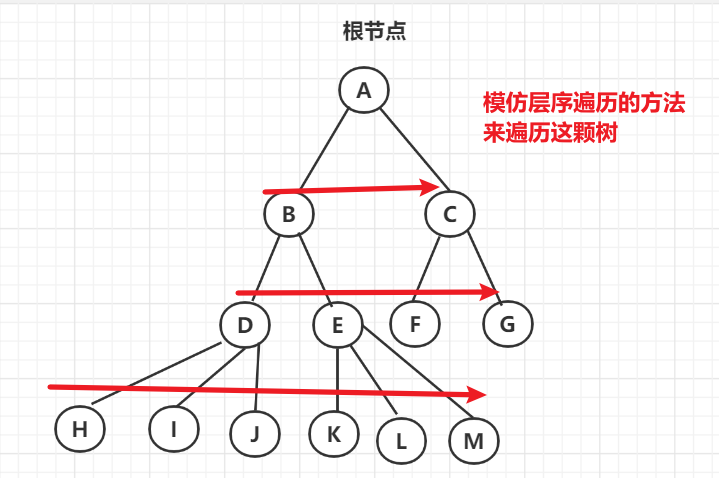
对于所有合法的BFS求解过程,都可以像DFS中那样画一颗树,并且将广度优先搜索问题转换为树的程序遍历的过程
7.4 二叉查找树(BST)
二叉查找树(Binary Search Tree)是一种特殊二叉树
- 排序二叉树
- 二叉搜索树
- 二叉排序树
7.4.1 二叉查找树的基本操作
二叉查找树的基本操作有查找,插入,建树,删除
- 查找操作
因为二叉树的