1.闲言
每天晚上睡觉之前,我都会说服自己白天发生的一切都是假的,都已经过去了。就好像每天早上醒来,我也会不由自主的觉得昨天晚上发生的一切也都是假的。其实仔细想一下,现实世界能够进入梦中的事物是很有限的。同样,梦中的事物能够流到现实世界的也是很有限的。那么在入口和出口的地方应该会有类似于过滤器一样的东西,把大部分的事物都给拦了下来。晚上我就好像一堆沙子一样躺在那个地方,当清晨的太阳照射进来的时候,再凝聚成人的样式起来活动。在此我想表述的意思,并不是说这个世界是虚幻的,而是说它无比的真实。真实的世界就是丰富多彩的,充满着各种各样神奇又美丽的事物。规则适用于规则以下的事物,更高的规则适用于更高的事物。你就尽管的胡思乱想,想破了天,也不会比这世界本来的样式更丰富。
2.语言模型
如何来理解语言模型,它相当于是人类对于信息进行编码和解码的方式。在人类大脑中存在的,除了一堆词汇之外,还有一些东西类似于风格、气质、调调等。仔细思考的话我们会发现,我们的表达其实并不像是一道论述题,而更像是一道选择题。我们会从自己记忆中存在的各种语言模型中,选择一种自己觉得最好的,以这种方式来对词汇进行组合编码,输出自己的观点。包括我们的思维、行为方式等很多看起来是自由和任意的东西,从本质上讲也都是选择的过程。也许这些东西的待选模型会比较多,但也是有限的。即使一个人在胡说八道,那他也一定是按照某种模型在胡说八道。这些模型的存在,实现了信息在人与人之间的编码和解码。模型和符号的有限性,也决定的人类本身的有限性。神经网络中的语言模型,更多描述的是词汇之间的组合方式,应用上下文去预测当前词。
3.N-gram
n-gram是一种统计语言模型,它基于马尔科夫假设,即未来的事件只取决于有限的历史。这种假设很容易理解,比如说我今天下午肚子饿了,那取决于我午饭吃的什么,或者早饭吃的什么;实在不行就基于昨天晚饭我吃的什么;但对于人类的消化系统来说,它无论如何也不会取决于我去年或者更早的时间吃的是什么。这只是一种假设,我也不知道是不是所有事件发生的原因都符合这种时间上的有限性,至少看起来大部分的事情都是这样的,最多就是有限时间长与短的问题而已。所以这种假设应该是堪用的。
将马尔科夫模型应用到语言模型中来那就是,每一个单词的出现都取决于它前面有限个单词。比如这句名言:“生存或者死亡,这是个值得思考的问题。”如果我们假设有限单词的个数为2,那么“死亡”这个词就取决于“生存”和“或者”,对于这有限个单词数量n的不同定义,组成了不同的gram模型。比如n为1那就是unigram,2就使bigram,3就是trigram。
那如何将我们上述的思想进行落地,应用到我们的语言模型中来呢?我们借助于贝叶斯公式,下面公式的前半部分就是贝叶斯公式,如果对于贝叶斯不是要特别了解可以戳这里;简答解释就是A条件下B出现的概率=AB的联合概率/A出现的概率。我们看到贝叶斯公式后面接了count统计数量,也就是说在数量很多的情况下,概率是和它们出现的次数的比例很接近的。
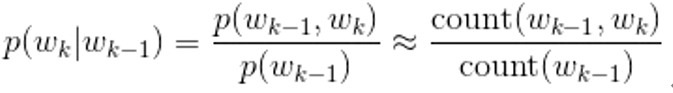
基于上面的公式我们对N-gram进行展开,下面公式解释一下就是:整体句子的出现概率等于每个单词在句子中出现的概率之积,单词在句子中的概率相当于是该单词在前N个单词条件下的概率。当N为1的时候各个单词之间相当于是独立的,直接概率相乘,相当于是采用最大似然;当N为2的时候,整个句子出现的概率相当于每个单词在前一个单词条件下的概率连乘,往后推也一样。

此处举例,二元模型概率分布表。可以得到每一个单词和另外一个单词条件下的概率,其中的概率是使用这两个单词组合出现的次数除以所有的两两单词组合出现的次数。一般来说三元模型用到比较多,但是如果二元可以用的话就不要去用三元。

相关问题:
1.OOV问题,即如果一个词我们以前没有。那么这个词的概率就会是0,从而导致整个句子概率为0;处理方式为设置阈值,只有对出现次数大于某个阈值的才计入计入词表,其它的就用特殊字符代替UNK。相当于是阈值太小的字符不参与到总概率的计算中来。
2.平滑:如果组合在我们的语料库中没有,则count就为0,这时候计算的概率也为零。对于这种情况我们采用给每个数加1,做一个平滑处理。
2.可区别性和可靠性:如果N过于大则会导致对于当前单词的约束过强,那么容易导致过拟合。那么可区别性就会更高,可靠性相应的会减少。说人话就是,特征太多训练集上是更准了,却容易过拟合。
评价:
优点:因为是基于有限单词个数,所以效率高;
缺点:无法关联更早的信息,无法体现出相似度,可能出现概率为0的情况;
总结:n-gram是基于马尔科夫假设,使用统计学的方式,来表达文本中词汇分布情况的一种模型。整体文本的分布概率可以使用每个词汇条件概率的连乘来表示。其优点是,基于有限的历史所以效率高;缺点是,无法体现文本相似度,无法关联更早的信息。
4.N-gram神经网络语言模型
N-gram神经网络语言模型,就是将N-gram的思想与神经网络结合起来,根据上下文信息预测当前词的一套网络模型。前面我们所说的基于统计的N-gram有一些缺点,属于机器学习的范畴。那么基于深度学习的神经网络会是什么样的呢?
请看下面这张网络示意图,简单说就是把上下文信息输入模型,预测词表中每一个词出现的概率,概率最大的作为我们的预测值。这就是一个非常简单的四层神经网络,我们来结识一些关键点。首先将context中的每一个词进行one-hot编码,然后通过词向量表(该词向量表也是通过训练得到)找到对应词的词向量,使用一个projection(投影层)将所有上下文向量拼接起来,然后经过隐层使用tanh非线性激活,最后输出为softmax多分类。
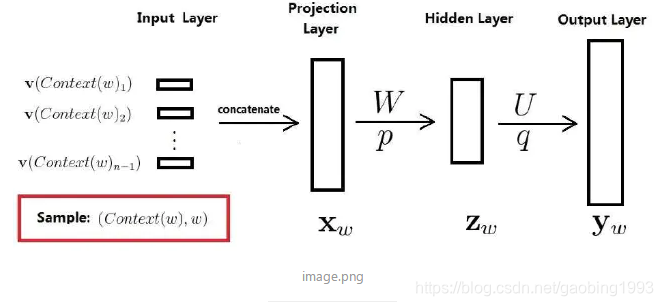
训练好的模型可以干的事情就是,给一个上下文,就会预测出来当前的词是什么。然后还会得到模型的副产品-词向量表。各参数描述:输入层V(context(W))的数量跟上下文中的词数量一致;词向量表的形状为(词表中词的数量*词向量长度);
总结:上面我们介绍了N-gram神经网络语言模型,主要就是将N-gram的思想套用到神经网络的架构中来,区别于上面我们基于统计的语言模型。这个模型可以根据词向量来计算出词之间的相似度。
5.总结
本文我们描述了N-gram的思想,以及神经网络语言模型。它是一种基于马尔科夫假设的语言模型。可以用来提炼出文本中隐含的词汇之间的关系,通过给定的上下文,会给出预测的词汇。就好像是一个爱接别人话茬的小孩子。
没有希望的未来不是我所期待的,在暴风雨来临之前,我不需要保护的伞;我要通过自己的不断努力,使自己成为一把伞,为了家人。因为年轻,所以我没有什么可以失去的;也因为年轻,我告诉自己没有资格谈害怕这两个字。因为骄傲的花儿,不愿意永远躲在花骨朵中遮风避雨,为了见一见阳光,它早就不怕被碾那无情的风雨碾做尘土。花开一时,人活一世,披荆斩棘,逆风飞翔。请欣赏下面这首永恒的经典-青鸟。
【火影忍者】青鸟—现场演唱