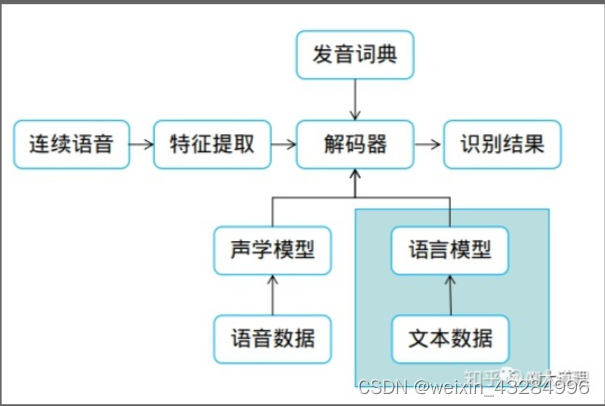
在语音识别过程中,通过前面介绍的GMM-HMM模型可以通过viterbi等算法求解得到最佳状态序列。但若针对的语音包括所有词汇、英文、数字,可能达到几十万个词,解码过程将非常复杂。同音字的不同排列组合结果有很多,识别结果不会太理想。故需要引入语言模型来约束识别结果,让“今天天气很好”的概率高于“今天天汽很好”的概率,得到声学模型概率高,又符合表达的句子。
在模型设计中有两个比较重要的问题:
1)自由参数问题:如果一句话中间每个词都互相关联,模型的自由参数是随着字符串长度的增加而指数级暴增的,这使我们几乎不可能正确的估计出这些参数。
2)零概率问题(OOV问题):汉字组合千千万,但十几种能拿来训练的语料并不会出现这么多种组合,那么依据极大似然估计,其最终结果概率很可能是0。(假设一种组合在模型训练中并没有出现,模型训练是求得参数使出现的组合出现概率最大,相对的,使没出现的组合概率最小。故当出现训练时没有出现的组合时,模型计算出的概率很有可能是 0,但这种组合可能并不是不合理的。)
N-Gram:
N-Gram是大词汇连续语音识别中常用的一种语言模型。该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。
N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。
对于形成的每一个字节片段(gram)进行频度统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。
自由参数问题:
根据之前GMM-HMM模型的思想,判断一个由 N 个词组成的句子是否合理,我们希望得到其出现的概率,且其概率是观测状态对应的所有句子中最大的,其概率为:
其中概率可以通过前期标注文本数据统计获得:
一般用 <s> 和 </s> 来标记开头结尾,没有在词汇表中的词(OOV, out of vocabulary)标记位 <UNK>。
显然,如果第 n 个词出现的概率与前面所有的词都相关,那么当我们要计算出最可能出现的句子时,计算量将是词长度 N 的指数倍。
我们不妨继续借鉴HMM的思想,假设当前词出现的概率仅仅与前面几个有限的词相关联,这样可以大幅减少计算量。现实中,我们所说大部分也是与最近时间的词相关。极端一点,今天说的话与去年今天说的话的相关性应该是很小甚至没有的。
当n=1时,即一个词的出现与它周围的词是独立,称为unigram。
当n=2时,即一个词的出现仅与它前面的一个词有关时,称为bigram。
当n=3时,即一个词的出现仅与它前面的两个词有关,称为trigram。
数据平滑算法:
由于训练语料的稀疏性,有些词序找不到,会出现 零概率问题,故需要对数据进行平滑。
举例(1):
假设现有训练集 T = (西瓜,西瓜,西瓜 | 吃),表示采集到的在 “吃” 后面可以跟的词组。
根据极大似然估计,会求得系统参数使得 p(西瓜,西瓜,西瓜 | 吃) 最大。最终系统会得到如下结果:
p(x) = (x == 西瓜 ? 1 : 0)
那么当实际测试集出现例如“吃苹果”、“吃香蕉”、“吃梨子”等合理词组,但是该词组不在训练集时,系统输出词组出现概率都为0,使得模型输出结果不理想,这就是零概率问题。
1)加一平滑/拉普拉斯平滑(Add-one Smoothing/Laplace Smoothing)
思路:将所有词序的计数都加一(可以是任意合适的数 a),从而任何词序都有计数,就可以避免0概率问题。为了保证所有实例的概率总和为1,将分母增加实例的种类数,即:
优点:算法简单,解决的 0 概率问题
缺点:由于语料的稀疏性,大部分的组合都没有出现过,Add-one给训练语料中没有出现过的 N-grams 分配了太多的概率空间,且认为所有未出现的N-grams概率相等也有点不合理。
补充此算法涉及的两个概念;
1)调整计数 :用于描述平滑算法对分子的影响,意思是自身概率在被分走之后,对原有概率的影响程度:
其中:为原始计数,N 为原始分母,V为分母增加的实例种类数。
2)相对打折率 :代表打折计数和原计数的比率,意思是对整体而言发生的变化:
2)古德-图灵平滑(Good-turing Smoothing)
思想:用你看见过一次的事情(Seen Once)估计你未看见的事件(Unseen Events),并依次类推。即修改训练样本中事件的实际计数,使样本中(实际出现的)不同事件的概率之和小于1,剩余的概率量分配给未见概率。利用频率的类别信息来对频率进行平滑。
定义出现频率为 r 的N-gram词组的个数(频率的频率,frequency of frequency c)为 :
那么有:
其中 N 为样本总数。
算法核心有两个:
1)调整出现频率为 r 的N-gram的出现频率为 :
对于零概率问题,还有一种解决思路是对样本进行分类,当他按某种分类标准与训练集中的某一种样本相同时,可以让其拥有相同的概率。例如:“西瓜”、“香蕉”、“梨子”都是水果,那么就使得:p(西瓜 | 吃) = p(香蕉 | 吃) = p(梨子 | 吃)。因为有新的样本进入,为使得所有样本出现概率和为 1,则还需按规则调整现有样本出现的概率。
古德-图灵平滑(Good-turing Smoothing)就是按频率对样本进行分类:
其中:
即序列共有
个元素,其中
在样本中出现频率都为 r,
样本总数量为
,那么:
当样本中出现了训练集中没有出现的样本时,即出现了:
对所有样本概率求和得:
由训练结果得,即零概率问题,此时便需要对概率分布进行调整。
古德-图灵平滑(Good-turing Smoothing)用你看见过一次的事情(Seen Once)估计你未看见的事件(Unseen Events),并依次类推。
即使用(Seen Once)估计
(Unseen Events),依次类推用
估计
...。
那么我们使调整后的概率
得:
约分移项后得中每个样本新的出现频率为
:
则在样本中出现频率为 r 的样本经过调整后出现的概率为:
2)一般情况下,我们选出现过一次(Seen Once)的概率,即使用刚才已经看过一次的事物的数量来帮助估计从来没有见过(Unseen Events)的事物的数量,则。
也称为遗漏量(missing mass)
中每个样本出现的概率为:
古德-图灵平滑关键是用出现一次事件的概率去预测未出现事件的概率,再调整所有出现事件的概率。当 不存在时,应该通过线性回归之类的方法来补充,再带入计算。
感性的理解,古德-图灵平滑是将训练集中的样本概率后移,将频率为 1 的样本概率空出来给 频率为 0 的样本。这样做的理由是,在自然语言语料库中,高频出现的词往往只是那几个单词,大部分的词都是低频出现的。那么在训练集中没有出现的词大概率是低频词,其概率应该与训练集中仅出现 1 次的低频词所占比例接近,故用一次去估计未看见的事物是可行的。事物一般具有连续特性,故也可依次类推对其他概率进行调整。