文章目录
前言
在前面的文章中,笔者写过关于Ozone OM HA实现的相关文章(Ozone OM服务HA原理分析),里面谈论了目前OM HA的一些实现细节以及OM HA如何搭建这类的说明性文章。但是一套完整,高可用的系统,它需要确保其服务整体的健壮性,目前Ozone依赖的SCM服务还没有实现HA,是一个单点的服务。Ozone社区在实现了OM HA之后,已经在设计考虑实现SCM的HA方案(相关JIRA:HDDS-2823),以此能够达到一个稳定可使用的Ozone发布版本。本文笔者根据目前社区JIRA上对SCM HA的部分设计要点,来聊聊关于Ozone SCM服务的HA,我们有哪些主要设计要点以及其与OM HA的不同之处。
SCM HA相较于OM HA的区别点
这里SCM是StorageContainerManager名称的简写,而OM是OzoneManager的简称。在Ozone服务中,SCM是底层提供存储能力的基础服务,OM则是其上的应用服务。对于OM这样的应用服务,它在实现HA时重要考虑的点在于Leader/Follower服务节点上db元数据状态的一致。了解Ozone OM的同学应该清楚,OM的元数据不是类似HDFS NameNode的纯内存的维护,而是用外部K-V db库做存储的,而这个db是以文件形式持久化在本地的。因此OM HA在实现中只要做到这个外部db的数据同步更新,基本上就算完成OM HA的核心操作了。
SCM HA服务内存状态数据一致性的控制
但是SCM HA如果要去实现的话,它需要考虑的东西就要复杂很多了。首先它同样有类似OM db这样的元数据需要去同步,在SCM中这类的数据有Container,Pipeline数据。另外SCM在内存中还维护着Container,Pipeline的状态数据,它们的状态数据是根据下面Datanode实时汇报上来进行更新的。这类状态数据实质上不会更新在db文件里去,因此在SCM HA的实现中,内存状态数据的一致性同样是一个需要关注和考虑的点。
对于SCM HA的内存状态一致性控制,笔者个人的倾向是同样利用Apache Ratis做内存状态的控制,要定义相应内存状态更新的StateMachine来做。OM HA目前实行有db transaction更新的StateMachine实现了,SCM HA的db更新可借鉴于此。
Follower SCM内部管理服务的“失效”处理
Ozone SCM内部包含许多管理服务类进行着Node,Container以及Pipeline的管理,此类服务在后面的Follower SCM内都应该"失效化",另外一种解释可以称之为“空跑”,不做任何实质的处理操作。我们只允许Leader SCM服务做请求操作处理,并同步replicate它的状态改变到Follower SCM上,这个状态改变包括
- db transaction
- 内存维护状态的update
这里提到的管理服务包括有以下几类:
- ReplicationManager,以及类似此Manager类。
- ReportHandler,以及类似此Handler类。
当然这里有人可能会说了,为什么我们不能维持Follower SCM中ReportHandler的功能,来做Container,Pipeline内存状态的更新呢?类似于HDFS NameNode那样呢?这里实质上有Container report信息到SCM服务的latency考量,以及此状态延时可能造成的后续问题还需要进一步地实现讨论。因此才有了前面小节提到的做到SCM服务间内存状态的完全一致性同步方案考虑。
SCM HA failover行为处理
SCM服务从单点模式变为HA模式,SCM服务本身Leader选举切换理应对其Client端(这里目前指的就是OM服务)来讲是透明的。SCM的做法和现有OM HA类似,Follower角色服务抛出异常并且附带当前的Leader角色的SCM地址id,然后Client进行返回结果SCM id的retry。
SCM HA的整体架构图
以下是社区SCM HA设计文档中 SCM HA的整体架构设计图:、
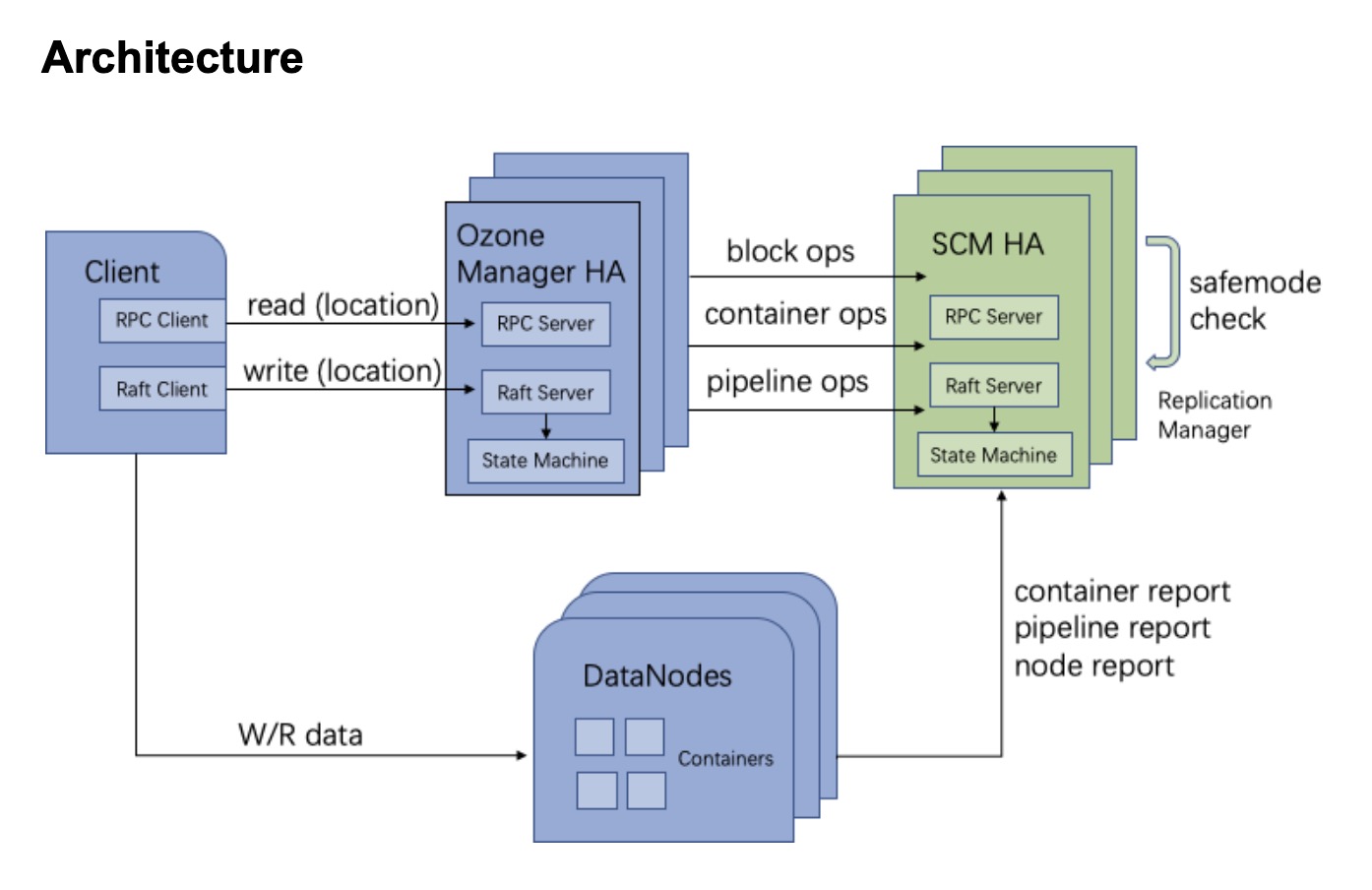
本文所阐述的SCM HA可详见下面的文档链接处。
引用
[1].https://issues.apache.org/jira/browse/HDDS-2823