前言
上篇文章里笔者介绍了Ozone中使用的Apache Ratis的内部一致性实现原理,得益于底层的一致性封装实现,在Ozone层面,它只需要调用此库并实现自定义的StateMachine方法即可。在Ozone Datanode中,就自定义了ContainerStateMachine来实现Container操作在多副本间的一致性控制。本文我们来聊聊Ozone Datanode ContainerStateMachine的内部实现,这样我们能够进一步深入了解Container的请求操作处理过程。
ContainerStateMachine对于StateMachine/RaftLog的语义实现
因为Ozone使用了Apache Ratis的内部实现,里面会多次涉及到以下两个概念:
- RaftLog
- StateMachine
所以我们需要先了解清楚这2个概念在Ozone中是一个什么样的变量定义。
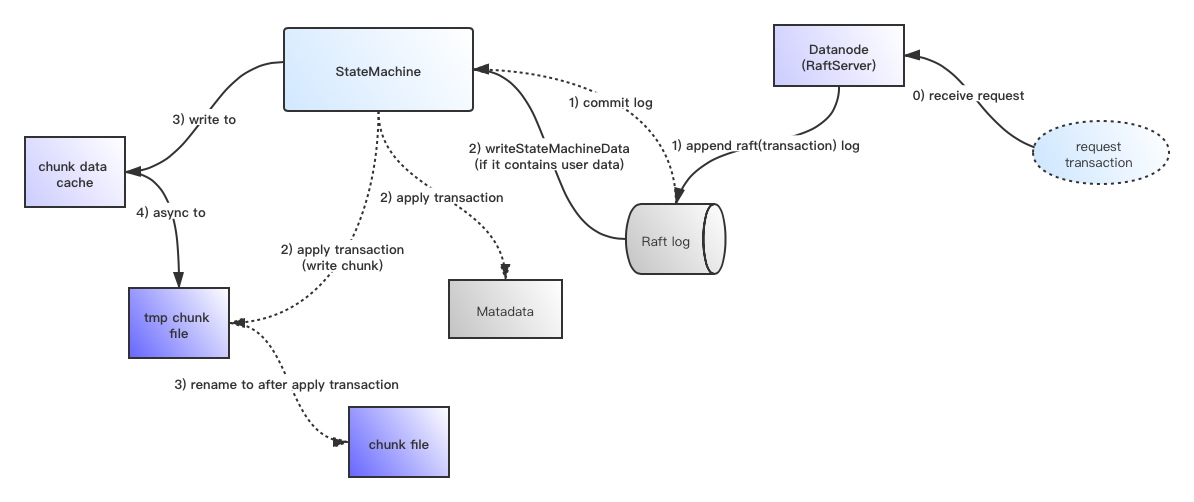
首先是RaftLog,RaftLog在Ozone中简单理解就是用户的每一次请求操作,在这里的表现形式为TransactionContext。这里面的过程如下所示:
首先Ozone层面会将用户请求包装为TransactionContext对象,
ContainerStateMachine的startTransaction操作方法,
public TransactionContext startTransaction(RaftClientRequest request)
throws IOException {
long startTime = Time.monotonicNowNanos();
final ContainerCommandRequestProto proto =
message2ContainerCommandRequestProto(request.getMessage());
Preconditions.checkArgument(request.getRaftGroupId().equals(gid));
try {
dispatcher.validateContainerCommand(proto);
} catch (IOException ioe) {
if (ioe instanceof ContainerNotOpenException) {
metrics.incNumContainerNotOpenVerifyFailures();
} else {
metrics.incNumStartTransactionVerifyFailures();
LOG.error("startTransaction validation failed on leader", ioe);
}
TransactionContext ctxt = TransactionContext.newBuilder()
.setClientRequest(request)
.setStateMachine(this)
.setServerRole(RaftPeerRole.LEADER)
.build();
ctxt.setException(ioe);
return ctxt;
}
...
}
然后Datanode把接收到的TransactionContext写入RaftLog时,会进行log entry的转化,
@Override
public LogEntryProto initLogEntry(long term, long index) {
Preconditions.assertTrue(serverRole == RaftPeerRole.LEADER);
Preconditions.assertNull(logEntry, "logEntry");
Objects.requireNonNull(smLogEntryProto, "smLogEntryProto == null");
return logEntry = ServerProtoUtils.toLogEntryProto(smLogEntryProto, term, index);
}
然后Datanode内部的RaftServer会将这些由TransactionContext转化而来的log entry写入到本地的RaftLog内。
在log entry的写入过程中,还需要再分为下面两种情况:
第一种,请求带有用户数据的情况,在Ozone中意为写数据操作请求,例如writeChunk请求,我们需要把这些数据独立写出到StateMachine中,RaftLog只保留Transaction信息本身。StateMachine在这里可以理解为Datanode的Metadata当前状态。
因为用户数据真正写出是需要时间的,因此Datanode ContainerStateMachine在里面实现了内部cache的方式先保存用户请求数据,然后再异步写出这部分chunk数据,不过是先保存为了tmp临时文件状态。
/*
* writeStateMachineData calls are not synchronized with each other
* and also with applyTransaction.
*/
@Override
public CompletableFuture<Message> writeStateMachineData(LogEntryProto entry) {
try {
metrics.incNumWriteStateMachineOps();
long writeStateMachineStartTime = Time.monotonicNowNanos();
ContainerCommandRequestProto requestProto =
getContainerCommandRequestProto(
entry.getStateMachineLogEntry().getLogData());
//1) 构造write chunk请求操作
WriteChunkRequestProto writeChunk =
WriteChunkRequestProto.newBuilder(requestProto.getWriteChunk())
.setData(getStateMachineData(entry.getStateMachineLogEntry()))
.build();
requestProto = ContainerCommandRequestProto.newBuilder(requestProto)
.setWriteChunk(writeChunk).build();
Type cmdType = requestProto.getCmdType();
// For only writeChunk, there will be writeStateMachineData call.
// CreateContainer will happen as a part of writeChunk only.
switch (cmdType) {
case WriteChunk:
return handleWriteChunk(requestProto, entry.getIndex(),
entry.getTerm(), writeStateMachineStartTime);
default:
throw new IllegalStateException("Cmd Type:" + cmdType
+ " should not have state machine data");
}
} catch (IOException e) {
metrics.incNumWriteStateMachineFails();
return completeExceptionally(e);
}
}
private CompletableFuture<Message> handleWriteChunk(
ContainerCommandRequestProto requestProto, long entryIndex, long term,
long startTime) {
final WriteChunkRequestProto write = requestProto.getWriteChunk();
RaftServer server = ratisServer.getServer();
Preconditions.checkState(server instanceof RaftServerProxy);
try {
// 2) 如果是Leader服务,将chunk数据写入cache中,leader服务将从此cache中读chunk数据,
// 包装为raft log请求发送给Follower
if (((RaftServerProxy) server).getImpl(gid).isLeader()) {
stateMachineDataCache.put(entryIndex, write.getData());
}
} catch (IOException | InterruptedException ioe) {
return completeExceptionally(ioe);
}
DispatcherContext context =
new DispatcherContext.Builder()
.setTerm(term)
.setLogIndex(entryIndex)
// 标明此阶段为写数据阶段
.setStage(DispatcherContext.WriteChunkStage.WRITE_DATA)
.setContainer2BCSIDMap(container2BCSIDMap)
.build();
CompletableFuture<Message> raftFuture = new CompletableFuture<>();
// ensure the write chunk happens asynchronously in writeChunkExecutor pool
// thread.
...
return raftFuture;
}
对于Datanode RaftLeader角色,它还需要实现readStateMachineData方法从自身StateMachine中读取用户数据构造Raft log发送给哪些Raft Follower的Datanode。
ContainerStateMachine的readStateMachineData方法,
/*
* This api is used by the leader while appending logs to the follower
* This allows the leader to read the state machine data from the
* state machine implementation in case cached state machine data has been
* evicted.
*/
@Override
public CompletableFuture<ByteString> readStateMachineData(
LogEntryProto entry) {
...
try {
final ContainerCommandRequestProto requestProto =
getContainerCommandRequestProto(
entry.getStateMachineLogEntry().getLogData());
// readStateMachineData should only be called for "write" to Ratis.
Preconditions.checkArgument(!HddsUtils.isReadOnly(requestProto));
// 目前readStateMachineData只会被write chunk请求调用
if (requestProto.getCmdType() == Type.WriteChunk) {
final CompletableFuture<ByteString> future = new CompletableFuture<>();
CompletableFuture.supplyAsync(() -> {
try {
future.complete(
getCachedStateMachineData(entry.getIndex(), entry.getTerm(),
requestProto));
} catch (IOException e) {
metrics.incNumReadStateMachineFails();
future.completeExceptionally(e);
}
return future;
}, chunkExecutor);
return future;
} else {
throw new IllegalStateException("Cmd type:" + requestProto.getCmdType()
+ " cannot have state machine data");
}
} catch (Exception e) {
metrics.incNumReadStateMachineFails();
LOG.error("{} unable to read stateMachineData:", gid, e);
return completeExceptionally(e);
}
}
/**
* Reads the Entry from the Cache or loads it back by reading from disk.
*/
private ByteString getCachedStateMachineData(Long logIndex, long term,
ContainerCommandRequestProto requestProto)
throws IOException {
// 从本地cache中快速读取,如果cache中已不存在了,从本地tmp chunk文件中读取数据
ByteString data = stateMachineDataCache.get(logIndex);
if (data == null) {
data = readStateMachineData(requestProto, term, logIndex);
}
return data;
}
这部分请求处理最终在ChunkManagerImpl中的逻辑如下:
public void writeChunk(Container container, BlockID blockID, ChunkInfo info,
ChunkBuffer data, DispatcherContext dispatcherContext)
throws StorageContainerException {
Preconditions.checkNotNull(dispatcherContext);
DispatcherContext.WriteChunkStage stage = dispatcherContext.getStage();
try {
...
switch (stage) {
case WRITE_DATA:
//...
if (tmpChunkFile.exists()) {
// If the tmp chunk file already exists it means the raft log got
// appended, but later on the log entry got truncated in Ratis leaving
// behind garbage.
// TODO: once the checksum support for data chunks gets plugged in,
// instead of rewriting the chunk here, let's compare the checkSums
LOG.warn(
"tmpChunkFile already exists" + tmpChunkFile + "Overwriting it.");
}
// 写入的是临时tmp文件中,如果后续发送Raft log truncate操作,此tmp数据也可以被重新覆盖掉
// 此过程发生在ContainerStateMachine的writeStateMachineData阶段
ChunkUtils
.writeData(tmpChunkFile, info, data, volumeIOStats, doSyncWrite);
// No need to increment container stats here, as still data is not
// committed here.
break;
case COMMIT_DATA:
...
// 提交chunk数据阶段,rename tmp chunk文件为正式文件名,
// 此过程发生在ContainerStateMachine的applyTransaction阶段
commitChunk(tmpChunkFile, chunkFile);
// Increment container stats here, as we commit the data.
updateContainerWriteStats(container, info, isOverwrite);
break;
case COMBINED:
// directly write to the chunk file
ChunkUtils.writeData(chunkFile, info, data, volumeIOStats, doSyncWrite);
updateContainerWriteStats(container, info, isOverwrite);
break;
default:
throw new IOException("Can not identify write operation.");
}
} catch (StorageContainerException ex) {
...
}
}
注意上面笔者提到的writeStateMachineData操作只是将用户请求数据写出去,并不意味着这个动作的结束,成功结束还得在RaftLog apply到StateMachine的时候。
因此我们能够看到writechunk的请求操作只有在applyTransaction操作的时候才声明Stage为COMMIT_DATA阶段,
/*
* ApplyTransaction calls in Ratis are sequential.
*/
@Override
public CompletableFuture<Message> applyTransaction(TransactionContext trx) {
long index = trx.getLogEntry().getIndex();
// Since leader and one of the followers has written the data, it can
// be removed from the stateMachineDataMap.
stateMachineDataCache.remove(index);
DispatcherContext.Builder builder =
new DispatcherContext.Builder()
.setTerm(trx.getLogEntry().getTerm())
.setLogIndex(index);
long applyTxnStartTime = Time.monotonicNowNanos();
try {
applyTransactionSemaphore.acquire();
metrics.incNumApplyTransactionsOps();
ContainerCommandRequestProto requestProto =
getContainerCommandRequestProto(
trx.getStateMachineLogEntry().getLogData());
Type cmdType = requestProto.getCmdType();
// Make sure that in write chunk, the user data is not set
if (cmdType == Type.WriteChunk) {
Preconditions
.checkArgument(requestProto.getWriteChunk().getData().isEmpty());
builder
// apply transaction阶段为commit chunk data阶段
.setStage(DispatcherContext.WriteChunkStage.COMMIT_DATA);
}
...
}
而对于其它不带用户数据的请求,例如纯做metadata update的Container请求,将会在RaftLog applyTransaction到StateMachine时被处理,也就是上面展示的ContainerStateMachine的applyTransaction。这部分请求将会被传入到HddsDispatcher中进行异步地处理。
对于Read类型的请求,此部分是由于StateMachine的query方法处理的,操作如下:
ContainerStateMachine的query
@Override
public CompletableFuture<Message> query(Message request) {
try {
metrics.incNumQueryStateMachineOps();
final ContainerCommandRequestProto requestProto =
message2ContainerCommandRequestProto(request);
// 执行runCommand方法
return CompletableFuture
.completedFuture(runCommand(requestProto, null)::toByteString);
} catch (IOException e) {
metrics.incNumQueryStateMachineFails();
return completeExceptionally(e);
}
}
至于在其中过程中存在Datanode RaftFollower可能发生RaftLog不一致的情况,需要truncate操作的执行。同时ContainerStateMachine也需要做对应的处理,处理之前写入StateMachine的用户数据,处理操作如下:
@Override
public CompletableFuture<Void> truncateStateMachineData(long index) {
// 移除指定index之后的cache数据,写出的tmp chunk data将会后续的写操作中被覆盖
stateMachineDataCache.removeIf(k -> k >= index);
return CompletableFuture.completedFuture(null);
}
通过上述ContainerStateMachine对于StateMachine的必要方法实现,Ozone Datanode实现了基于Raft协议控制的请求一致性处理过程了。主要是涉及到额外用户数据的写请求处理时,需要有StateMachine data的写入读取操作处理。至于大部分的读写请求Transaction而言,实现于StateMachine的query和applyTransaction即可。Apache Ratis实现库底层都帮我们实现好了,对这部分感兴趣的同学可阅读了解笔者的上一篇文章:Ozone内部使用的RaftLeader/RaftFollower的一致性同步机理。
此过程的流程图展示如下所示,以下流程图能加深大家对于上述过程的了解,实线表示普通Raft log的写阶段,虚线表示commit log的阶段。