一、简介
1.1、概述
1.1.1、Apache Kafka是 一个分布式流处理平台.
我们知道流处理平台有以下三种特性:
- 可以让你发布和订阅流式的记录。这一方面与消息队列或者企业消息系统类似。
- 可以储存流式的记录,并且有较好的容错性。
- 可以在流式记录产生时就进行处理。
1.1.2 、Kafka适合什么样的场景?
Kafka适用于两大类别的应用场景:
- 构造实时流数据管道,它可以在系统或应用之间可靠地获取数据。 (相当于message queue)
- 构建实时流式应用程序,对这些流数据进行转换或者影响。 (就是流处理,通过kafka streamtopic和topic之间内部进行变化)
1.1.3 Kafka的特性
为了理解Kafka是如何做到以上所说的功能,从下面开始,我们将深入探索Kafka的特性。
(1)Kafka的概念:
- Kafka作为一个集群,运行在一台或者多台服务器上.
- Kafka 通过 topic 对存储的流数据进行分类。
- 每条记录中包含一个key,一个value和一个timestamp(时间戳)。
(2)Kafka有四个核心的API:
- The Producer API 允许一个应用程序发布一串流式的数据到一个或者多个Kafka topic。
- The ConsumerAPI 允许一个应用程序订阅一个或多个 topic ,并且对发布给他们的流式数据进行处理。
- The Streams API允许一个应用程序作为一个流处理器,消费一个或者多个topic产生的输入流,然后生产一个输出流到一个或多个topic中去,在输入输出流中进行有效的转换。
- The Connector API 允许构建并运行可重用的生产者或者消费者,将Kafka topics连接到已存在的应用程序或者数据系统。比如,连接到一个关系型数据库,捕捉表(table)的所有变更内容。

1.1.4 、Topics和日志
首先Kafka的核心概念:提供一串流式的记录— topic 。
Topic 就是数据主题,是数据记录发布的地方,可以用来区分业务系统。Kafka中的Topics总是多订阅者模式,一个topic可以拥有一个或者多个消费者来订阅它的数据。
对于每一个topic, Kafka集群都会维持一个分区日志,如下所示:


每个分区都是有序且顺序不可变的记录集,并且不断地追加到结构化的commit log文件。分区中的每一个记录都会分配一个id号来表示顺序,我们称之为offset,offset用来唯一的标识分区中每一条记录。
Kafka 集群保留所有发布的记录—无论他们是否已被消费—并通过一个可配置的参数——保留期限来控制。 举个例子, 如果保留策略设置为2天,一条记录发布后两天内,可以随时被消费,两天过后这条记录会被抛弃并释放磁盘空间。Kafka的性能和数据大小无关,所以长时间存储数据没有什么问题.

事实上,在每一个消费者中唯一保存的元数据是offset(偏移量)即消费在log中的位置.偏移量由消费者所控制:通常在读取记录后,消费者会以线性的方式增加偏移量,但是实际上,由于这个位置由消费者控制,所以消费者可以采用任何顺序来消费记录。例如,一个消费者可以重置到一个旧的偏移量,从而重新处理过去的数据;也可以跳过最近的记录,从"现在"开始消费。
这些细节说明Kafka 消费者是非常廉价的—消费者的增加和减少,对集群或者其他消费者没有多大的影响。比如,你可以使用命令行工具,对一些topic内容执行 tail操作,并不会影响已存在的消费者消费数据。
日志中的 partition(分区)有以下几个用途。
- 当日志大小超过了单台服务器的限制,允许日志进行扩展。每个单独的分区都必须受限于主机的文件限制,不过一个主题可能有多个分区,因此可以处理无限量的数据。
- 可以作为并行的单元集。
1.1.5 、分布式
日志的分区partition (分布)在Kafka集群的服务器上。每个服务器在处理数据和请求时,共享这些分区。每一个分区都会在已配置的服务器上进行备份,确保容错性.
每个分区都有一台 server 作为 “leader”,零台或者多台server作为 follwers 。leader server 处理一切对 partition (分区)的读写请求,而follwers只需被动的同步leader上的数据。当leader宕机了,followers 中的一台服务器会自动成为新的 leader。每台 server 都会成为某些分区的 leader 和某些分区的 follower,因此集群的负载是平衡的。
1.1.6 、生产者
生产者可以将数据发布到所选择的topic(主题)中。生产者负责将记录分配到topic的哪一个 partition(分区)中。可以使用循环的方式来简单地实现负载均衡,也可以根据某些语义分区函数(例如:记录中的key)来完成。
1.1.7 、消费者
消费者使用一个 消费组 名称来进行标识,发布到topic中的每条记录被分配给订阅消费组中的一个消费者实例.消费者实例可以分布在多个进程中或者多个机器上。
如果所有的消费者实例在同一消费组中,消息记录会负载平衡到每一个消费者实例.
如果所有的消费者实例在不同的消费组中,每条消息记录会广播到所有的消费者进程.

如图,这个 Kafka 集群有两台 server 的,四个分区(p0-p3)和两个消费者组。消费组A有两个消费者,消费组B有四个消费者。
通常情况下,每个 topic 都会有一些消费组,一个消费组对应一个"逻辑订阅者"。一个消费组由许多消费者实例组成,便于扩展和容错。这就是发布和订阅的概念,只不过订阅者是一组消费者而不是单个的进程。
在Kafka中实现消费的方式是将日志中的分区划分到每一个消费者实例上,以便在任何时间,每个实例都是分区唯一的消费者。维护消费组中的消费关系由Kafka协议动态处理。如果新的实例加入组,他们将从组中其他成员处接管一些 partition 分区;如果一个实例消失,拥有的分区将被分发到剩余的实例。
Kafka 只保证分区内的记录是有序的,而不保证主题中不同分区的顺序。每个 partition 分区按照key值排序足以满足大多数应用程序的需求。但如果你需要总记录在所有记录的上面,可使用仅有一个分区的主题来实现,这意味着每个消费者组只有一个消费者进程。
1.1.8 、保证
high-level Kafka给予以下保证:
- 生产者发送到特定topic partition 的消息将按照发送的顺序处理。
- 也就是说,如果记录M1和记录M2由相同的生产者发送,并先发送M1记录,那么M1的偏移比M2小,并在日志中较早出现
- 一个消费者实例按照日志中的顺序查看记录. 对于具有N个副本的主题,我们最多容忍N-1个服务器故障,从而保证不会丢失任何提交到日志中的记录.
关于保证的更多细节可以看文档的设计部分。
1.1.9 、Kafka作为消息系统
Kafka streams的概念与传统的企业消息系统相比如何?
传统的消息系统有两个模块: 队列 和 发布-订阅。 在队列中,消费者池从server读取数据,每条记录被池子中的一个消费者消费; 在发布订阅中,记录被广播到所有的消费者。两者均有优缺点。 队列的优点在于它允许你将处理数据的过程分给多个消费者实例,使你可以扩展处理过程。 不好的是,队列不是多订阅者模式的—一旦一个进程读取了数据,数据就会被丢弃。 而发布-订阅系统允许你广播数据到多个进程,但是无法进行扩展处理,因为每条消息都会发送给所有的订阅者。
消费组在Kafka有两层概念。在队列中,消费组允许你将处理过程分发给一系列进程(消费组中的成员)。 在发布订阅中,Kafka允许你将消息广播给多个消费组。
Kafka的优势在于每个topic都有以下特性—可以扩展处理并且允许多订阅者模式—不需要只选择其中一个.
Kafka相比于传统消息队列还具有更严格的顺序保证
传统队列在服务器上保存有序的记录,如果多个消费者消费队列中的数据, 服务器将按照存储顺序输出记录。 虽然服务器按顺序输出记录,但是记录被异步传递给消费者, 因此记录可能会无序的到达不同的消费者。这意味着在并行消耗的情况下, 记录的顺序是丢失的。因此消息系统通常使用“唯一消费者”的概念,即只让一个进程从队列中消费, 但这就意味着不能够并行地处理数据。
Kafka 设计的更好。topic中的partition是一个并行的概念。 Kafka能够为一个消费者池提供顺序保证和负载平衡,是通过将topic中的partition分配给消费者组中的消费者来实现的, 以便每个分区由消费组中的一个消费者消耗。通过这样,我们能够确保消费者是该分区的唯一读者,并按顺序消费数据。 众多分区保证了多个消费者实例间的负载均衡。但请注意,消费者组中的消费者实例个数不能超过分区的数量。
1.1.10 、Kafka 作为存储系统
许多消息队列可以发布消息,除了消费消息之外还可以充当中间数据的存储系统。那么Kafka作为一个优秀的存储系统有什么不同呢?
数据写入Kafka后被写到磁盘,并且进行备份以便容错。直到完全备份,Kafka才让生产者认为完成写入,即使写入失败Kafka也会确保继续写入
Kafka使用磁盘结构,具有很好的扩展性—50kb和50TB的数据在server上表现一致。
可以存储大量数据,并且可通过客户端控制它读取数据的位置,您可认为Kafka是一种高性能、低延迟、具备日志存储、备份和传播功能的分布式文件系统。
1.1.11 、Kafka用做流处理
Kafka 流处理不仅仅用来读写和存储流式数据,它最终的目的是为了能够进行实时的流处理。
在Kafka中,流处理器不断地从输入的topic获取流数据,处理数据后,再不断生产流数据到输出的topic中去。
例如,零售应用程序可能会接收销售和出货的输入流,经过价格调整计算后,再输出一串流式数据。
简单的数据处理可以直接用生产者和消费者的API。对于复杂的数据变换,Kafka提供了Streams API。 Stream API 允许应用做一些复杂的处理,比如将流数据聚合或者join。
这一功能有助于解决以下这种应用程序所面临的问题:处理无序数据,当消费端代码变更后重新处理输入,执行有状态计算等。
Streams API建立在Kafka的核心之上:它使用Producer和Consumer API作为输入,使用Kafka进行有状态的存储, 并在流处理器实例之间使用相同的消费组机制来实现容错。
1.1.12 、批处理
将消息、存储和流处理结合起来,使得Kafka看上去不一般,但这是它作为流平台所备的.
像HDFS这样的分布式文件系统可以存储用于批处理的静态文件。 一个系统如果可以存储和处理历史数据是非常不错的。
传统的企业消息系统允许处理订阅后到达的数据。以这种方式来构建应用程序,并用它来处理即将到达的数据。
Kafka结合了上面所说的两种特性。作为一个流应用程序平台或者流数据管道,这两个特性,对于Kafka 来说是至关重要的。
通过组合存储和低延迟订阅,流式应用程序可以以同样的方式处理过去和未来的数据。 一个单一的应用程序可以处理历史记录的数据,并且可以持续不断地处理以后到达的数据,而不是在到达最后一条记录时结束进程。 这是一个广泛的流处理概念,其中包含批处理以及消息驱动应用程序
同样,作为流数据管道,能够订阅实时事件使得Kafk具有非常低的延迟; 同时Kafka还具有可靠存储数据的特性,可用来存储重要的支付数据, 或者与离线系统进行交互,系统可间歇性地加载数据,也可在停机维护后再次加载数据。流处理功能使得数据可以在到达时转换数据。
二、安装Kafka
2.1 、kafka的下载与解压
2.1.1 、通过Wget指令下载Kafka
[hadoop@master ~]$ wget https://mirrors.bfsu.edu.cn/apache/kafka/2.7.0/kafka_2.12-2.7.0.tgz ##备注通过wget指令下载Kafa
--2021-01-27 14:21:09-- https://mirrors.bfsu.edu.cn/apache/kafka/2.7.0/kafka_2.12-2.7.0.tgz
Resolving mirrors.bfsu.edu.cn (mirrors.bfsu.edu.cn)... 39.155.141.16, 2001:da8:20f:4435:4adf:37ff:fe55:2840
Connecting to mirrors.bfsu.edu.cn (mirrors.bfsu.edu.cn)|39.155.141.16|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 68684719 (66M) [application/octet-stream]
Saving to: ‘kafka_2.12-2.7.0.tgz’
100%[===========================================================================================================>] 68,684,719 43.9MB/s in 1.5s
2021-01-27 14:21:11 (43.9 MB/s) - ‘kafka_2.12-2.7.0.tgz’ saved [68684719/68684719]

2.1.2 、解压Kafka
将下载好的kafka_2.12-2.7.0.tgz文件包解压到当前目录下
tar xzvf kafka_2.12-2.7.0.tgz

2.2 、Kafka配置
2.2.1 、修改Kafka配置文件
进入kafka_2.12-2.7.0目录下config文件夹,修改配置文件server.properties
[hadoop@master ~]$ cd kafka_2.12-2.7.0/config/
[hadoop@master config]$ vim server.properties
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=101
# 当前机器在集群中的唯一标识,和zookeeper的myid性质一样
# The address the socket server listens on. It will get the value returned from
# java.net.InetAddress.getCanonicalHostName() if not configured.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
# listeners=PLAINTEXT://:9092
listeners=PLAINTEXT://10.10.10.101:9092
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=10.10.10.100:2181,10.10.10.101:2181,10.10.10.102:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=60000
2.2.2 、将配置完成的文件分发到其他节点
以上的步骤我们操作了一个节点,还有两个节点,我们可以直接将刚刚配置好的直接分发到其它两个节点。因为配置文件都是一样的,唯一不同的是 borker.id不同就行。(以下的命令中,slave1和slave2是我另外两个节点的别名。)
[hadoop@master ~]$ scp –r /home/hadoop/ kafka_2.12-2.7.0 hadoop03:/home/hadoop/
[hadoop@master ~]$ scp –r /home/hadoop/ kafka_2.12-2.7.0 hadoop04:/home/hadoop/
三,启动集群
3.1 先启动zookeeper,再依次在各自节点上启动kafka
- 加守护进程启动
在bin的上一级目录执行命令:
[hadoop@master kafka_2.12-2.7.0]$
bin/kafka-server-start.sh -daemon config/server.properties
- 通过后台来启动
在bin的上一级目录执行命令:
[hadoop@master kafka_2.12-2.7.0]$
nohup bin/kafka-server-start.sh config/server.properties &
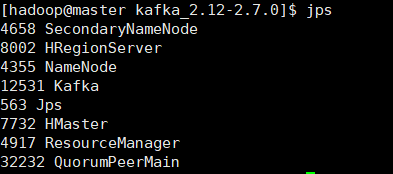
3.2 、输入jps查看Kafka
[hadoop@master kafka_2.12-2.7.0]$ jps
4658 SecondaryNameNode
8002 HRegionServer
4355 NameNode
12531 Kafka
563 Jps
7732 HMaster
4917 ResourceManager
32232 QuorumPeerMain
3.3 、使用Kafka
3.3.1 创建主题与查看主题
通过使用Kafka创建主题XXXXxxx,然后查看主题是否创建
[hadoop@slave2 ~]$ cd kafka_2.12-2.7.0/
[hadoop@slave2 kafka_2.12-2.7.0]$ ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic XXXXxxx
Created topic XXXXxxx.
[hadoop@slave2 kafka_2.12-2.7.0]$ ./bin/kafka-topics.sh --list --zookeeper localhost:2181
Test
Test1
XXXXxxx
__consumer_offsets

3.3.2 、创建生产者与消费者
在终端master创建生产者XXXx,另开一个终端slave2,创建消费者XXXx
- master 创建生产者
[hadoop@master kafka_2.12-2.7.0]$ ./bin/kafka-console-producer.sh --broker-list 10.10.10.101:9092 --topic XXXx
>zxc123asd789
>qwe123rty456
>951753zseqsc
- slave2 创建消费者
[hadoop@slave2 kafka_2.12-2.7.0]$ ./bin/kafka-console-consumer.sh --bootstrap-server 10.10.10.102:9092 --topic XXXx
zxc123asd789
qwe123rty456
951753zseqsc
生产者页面随意输入消息回车,可以看到消费者页面出现输入的消息。


四 、参考文章
Kafka 1.0 文档 https://kafka.apachecn.org/documentation.html#quickstart
问题总结
kafka连接生产者(消费者其实也一样的问题)出现了下面这个报错:(
WARN [Producer clientId=console-producer] Connection to node -1 could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient)
找到配置文件

将命令
.bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
改为:
。bin/kafka-console-producer.sh --broker-list 10.10.10.101:9092 --topic test
问题解决