hadoop中的序列化机制
Writable,接口是序列化的接口,Comparable是排序实现接口

1.自定义传递值的类型
package com.apollo.mr.flowsum;import org.apache.hadoop.io.WritableComparable;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;/** * Writable是序列化接口,Comparable是排序接口,MR中排序是按照key来排序的 * Created by 85213 on 2016/12/13. */public class FlowBean implements WritableComparable<FlowBean> {
private String phoneNB; private long u_flow; private long d_flow; private long s_flow; //在反序列化时,反射机制需要调用空参构造函数,所以显示定义了一个空参构造函数 public FlowBean(){} //为了对象数据的初始化方便,加入一个带参的构造函数 public FlowBean(String phoneNB,long u_flow,long d_flow){
this.phoneNB = phoneNB; this.u_flow = u_flow; this.d_flow = d_flow; this.s_flow = u_flow+d_flow; } //将对象数据序列化到流中 @Override public void write(DataOutput out) throws IOException {
out.writeUTF(phoneNB); out.writeLong(u_flow); out.writeLong(d_flow); out.writeLong(s_flow); } //注意顺序要和序列化的顺序一致 @Override public void readFields(DataInput in) throws IOException {
phoneNB = in.readUTF(); u_flow = in.readLong(); d_flow = in.readLong(); s_flow = in.readLong(); } //排序规则,这里实现倒序排序 @Override public int compareTo(FlowBean o) {
return s_flow > o.s_flow ?-1:1; } public String toString() {
return "" + u_flow + "\t" +d_flow + "\t" + s_flow; } public String getPhoneNB() {
return phoneNB; } public void setPhoneNB(String phoneNB) {
this.phoneNB = phoneNB; } public long getU_flow() {
return u_flow; } public void setU_flow(long u_flow) {
this.u_flow = u_flow; } public long getD_flow() {
return d_flow; } public void setD_flow(long d_flow) {
this.d_flow = d_flow; } public long getS_flow() {
return s_flow; } public void setS_flow(long s_flow) {
this.s_flow = s_flow; }}
2.mapper中输出类型使用自定义的类型
package com.apollo.mr.flowsum;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/** * FlowBean 是我们自定义的一种数据类型,要在hadoop的各个节点之间传输,应该遵循hadoop的序列化机制 * 就必须实现hadoop相应的序列化接口 * Created by 85213 on 2016/12/13. */public class FlowMapper extends Mapper<LongWritable,Text,Text,FlowBean> {
//拿到日志中的一行数据,切分各个字段,抽取出我们需要的字段:手机号,上行流量,下行流量,然后封装成kv发送出去 @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//拿到一行数据 String line = value.toString(); //解析字段 String[] fileds = line.split("\t"); String phoneNB = fileds[1]; long u_flow = Long.parseLong(fileds[7]); long d_flow = Long.parseLong(fileds[8]); context.write(new Text(phoneNB),new FlowBean(phoneNB,u_flow,d_flow)); }}
3.reducer中输出自定义的类型还需要在自定义类型中实现头string()方法
package com.apollo.mr.flowsum;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/** * Created by 85213 on 2016/12/13. */public class FlowReducer extends Reducer<Text,FlowBean,Text,FlowBean> {
@Override protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
long u_flow_counter = 0; long d_flow_counter = 0; for(FlowBean value : values){
u_flow_counter += value.getU_flow(); d_flow_counter += value.getD_flow(); } context.write(key,new FlowBean(key.toString(),u_flow_counter,d_flow_counter)); }}
4.标准的runner
package com.apollo.mr.flowsum;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.conf.Configured;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.util.Tool;import org.apache.hadoop.util.ToolRunner;/** * Created by 85213 on 2016/12/13. */public class FlowRunner extends Configured implements Tool {
@Override public int run(String[] strings) throws Exception {
Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(FlowRunner.class); job.setMapperClass(FlowMapper.class); job.setReducerClass(FlowReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowBean.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); FileOutputFormat.setOutputPath(job,new Path(strings[0])); FileInputFormat.setInputPaths(job,new Path(strings[1])); return job.waitForCompletion(true)?0:1; } public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(),new FlowRunner(),args); System.exit(res); }}
Hadoop的自定义排序
mr中的排序是在reducer阶段按照key的值排序的
1.实现comparable接口
package com.apollo.mr.flowsum;import org.apache.hadoop.io.WritableComparable;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;/** * Writable是序列化接口,Comparable是排序接口,MR中排序是按照key来排序的 * Created by 85213 on 2016/12/13. */public class FlowBean implements WritableComparable<FlowBean> {
private String phoneNB; private long u_flow; private long d_flow; private long s_flow; //在反序列化时,反射机制需要调用空参构造函数,所以显示定义了一个空参构造函数 public FlowBean(){} //为了对象数据的初始化方便,加入一个带参的构造函数 public FlowBean(String phoneNB,long u_flow,long d_flow){
this.phoneNB = phoneNB; this.u_flow = u_flow; this.d_flow = d_flow; this.s_flow = u_flow+d_flow; } //将对象数据序列化到流中 @Override public void write(DataOutput out) throws IOException {
out.writeUTF(phoneNB); out.writeLong(u_flow); out.writeLong(d_flow); out.writeLong(s_flow); } //注意顺序要和序列化的顺序一致 @Override public void readFields(DataInput in) throws IOException {
phoneNB = in.readUTF(); u_flow = in.readLong(); d_flow = in.readLong(); s_flow = in.readLong(); } //排序规则,这里实现倒序排序 @Override public int compareTo(FlowBean o) {
return s_flow > o.s_flow ?-1:1; } public String toString() {
return "" + u_flow + "\t" +d_flow + "\t" + s_flow; } public String getPhoneNB() {
return phoneNB; } public void setPhoneNB(String phoneNB) {
this.phoneNB = phoneNB; } public long getU_flow() {
return u_flow; } public void setU_flow(long u_flow) {
this.u_flow = u_flow; } public long getD_flow() {
return d_flow; } public void setD_flow(long d_flow) {
this.d_flow = d_flow; } public long getS_flow() {
return s_flow; } public void setS_flow(long s_flow) {
this.s_flow = s_flow; }}
2.mr
package com.apollo.mr.flowsort;import com.apollo.mr.flowsum.FlowBean;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;/** * Created by 85213 on 2016/12/14. */public class SortMR {
public static class SortMapper extends Mapper<LongWritable,Text,FlowBean,NullWritable>{
@Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString(); String[] fields = line.split("\t"); String phoneNB = fields[0]; long u_flow = Long.parseLong(fields[1]); long d_flow = Long.parseLong(fields[2]); context.write(new FlowBean(phoneNB,u_flow,d_flow),NullWritable.get()); } } public static class SortReducer extends Reducer<FlowBean,NullWritable,Text,FlowBean> {
@Override protected void reduce(FlowBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
String phoneNB = key.getPhoneNB(); context.write(new Text(phoneNB),key); } } public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(SortMR.class); job.setMapperClass(SortMapper.class); job.setReducerClass(SortReducer.class); job.setMapOutputKeyClass(FlowBean.class); job.setMapOutputValueClass(NullWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); FileInputFormat.setInputPaths(job,new Path(args[0])); FileOutputFormat.setOutputPath(job,new Path(args[1])); System.exit(job.waitForCompletion(true)?0:1); }}
MR的自定义分区
实现自定义的分组主要实现:1.自定义分区规则 2.设置reduce任务的并发数
1.自定义分组规则
package com.apollo.mr.areapartition;import org.apache.hadoop.mapreduce.Partitioner;import java.util.HashMap;/** * Created by 85213 on 2016/12/14. */public class AreaPartitioner<KEY,VALUE> extends Partitioner<KEY,VALUE>{
private static HashMap<String,Integer> areaMap = new HashMap<>(); static{
areaMap.put("135", 0); areaMap.put("136", 1); areaMap.put("137", 2); areaMap.put("138", 3); areaMap.put("139", 4); } //reducer阶段会聚合组号分配到不同的reducer中 @Override public int getPartition(KEY key, VALUE value, int i) {
//从key中拿到手机号,查询手机归属地字典,不同的省份返回不同的组号 int areaCoder = areaMap.get(key.toString().substring(0, 3))==null?5:areaMap.get(key.toString().substring(0, 3)); return areaCoder; }}
2.设置reduce的并发任务数量
package com.apollo.mr.areapartition;import com.apollo.mr.flowsum.FlowBean;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;/** * 对流量原始日志进行流量统计,将不同省份的用户统计结果输出到不同文件 * 需要自定义改造两个机制: * 1、改造分区的逻辑,自定义一个partitioner * 2、自定义reduer task的并发任务数 * Created by 85213 on 2016/12/14. */ public class FlowSumArea {
public static class FlowSumAreaMapper extends Mapper<LongWritable,Text,Text,FlowBean>{
@Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString(); String[] fields = line.split("\t"); String phoneNB = fields[1]; long u_flow = Long.parseLong(fields[7]); long d_flow = Long.parseLong(fields[8]); context.write(new Text(phoneNB),new FlowBean(phoneNB,u_flow,d_flow)); } } public static class FlowSumAreaReducer extends Reducer<Text,FlowBean,Text,FlowBean>{
@Override protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
long u_flow_count = 0; long d_flow_count= 0; for(FlowBean flowBean : values){
u_flow_count += flowBean.getU_flow(); d_flow_count += flowBean.getU_flow(); } context.write(key,new FlowBean(key.toString(),u_flow_count,d_flow_count)); } } public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(FlowSumArea.class); job.setMapperClass(FlowSumAreaMapper.class); job.setReducerClass(FlowSumAreaReducer.class); //设置我们自定义的分组逻辑定义 job.setPartitionerClass(AreaPartitioner.class); //设置reduce的任务并发数,应该跟分组的数量保持一致 job.setNumReduceTasks(6); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowBean.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); FileOutputFormat.setOutputPath(job,new Path(args[0])); FileInputFormat.setInputPaths(job,new Path(args[1])); System.exit(job.waitForCompletion(true)?0:1); }}
Hadoop中Combiner的使用
在MapReduce中,当map生成的数据过大时,带宽就成了瓶颈,怎样精简压缩传给Reduce的数据,有不影响最终的结果呢。有一种方法就是使用Combiner,Combiner号称本地的Reduce,Reduce最终的输入,是Combiner的输出。
@Override public int run(String[] arg0) throws Exception {
Configuration conf = getConf(); Job job = new Job(conf, "demo1"); String inputPath = ArgsTool.getArg(arg0, "input"); String outputPath = ArgsTool.getArg(arg0, "output"); FileInputFormat.addInputPath(job, new Path(inputPath)); FileOutputFormat.setOutputPath(job, new Path(outputPath)); job.setJarByClass(Demo1.class); job.setMapperClass(DemoMap.class); job.setReducerClass(DemoReduce.class); //job.setCombinerClass(DemoReduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); return job.waitForCompletion(true)?0:1; }
Hadoop中的Shuffle
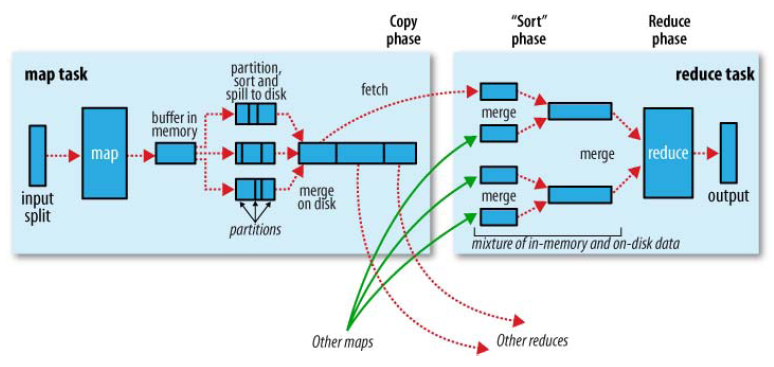
简要说明:
------------shuffler-----------------
一、map task shuffler
1.partition,分区
2.sort,排序
[3.combiner,合并]默认情况下没有combiner(合并内存中数据)
4.merge on disk,合并小的溢写文件合并成一个大文件
二、fetch/copy shuffler
1.reduce从所有的maptask的文件按照分区号抓取数据。
三、reduce shuffler
1.sort,因为从各个maptask取过来的数据所以数据已经乱了,二次排序
2.group,分组 默认分组算法是根据key相等为一组
------------shuffler-----------------详细解说:
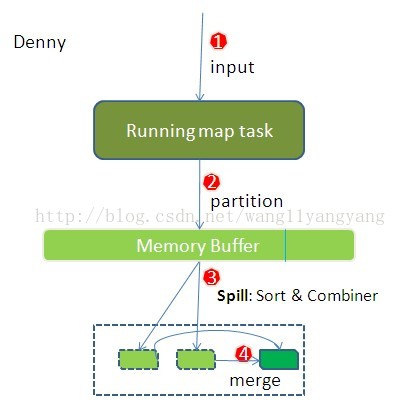
1.map输出后放在buffer in memory
接下来,需要将数据写入内存缓冲区中,缓冲区的作用是批量收集map结果,减少磁盘IO的影响。我们的key/value对以及Partition的结果都会被写入缓冲区。当然写入之前,key与value值都会被序列化成字节数组。
3.spill to disk
这个内存缓冲区是有大小限制的,默认是100MB。当map task的输出结果很多时,就可能会撑爆内存,所以需要在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区。这个从内存往磁盘写数据的过程被称为Spill,中文可译为溢写,字面意思很直观。这个溢写是由单独线程来完成,不影响往缓冲区写map结果的线程。溢写线程启动时不应该阻止map的结果输出,所以整个缓冲区有个溢写的比例spill.percent。这个比例默认是0.8,也就是当缓冲区的数据已经达到阈值(buffer size * spill percent = 100MB * 0.8 = 80MB),溢写线程启动,锁定这80MB的内存,执行溢写过程。Map task的输出结果还可以往剩下的20MB内存中写,互不影响。
4.sort
当溢写线程启动后,需要对这80MB空间内的key做排序(Sort)。排序是MapReduce模型默认的行为,这里的排序也是对序列化的字节做的排序。
5.combiner(对内存中的数据进行合并)
如果设置了combiner会启用执行分组函数
将有相同key的key/value对的value加起来,减少溢写到磁盘的数据量。
6.Merge(对大磁盘文件的合并)
每次溢写会在磁盘上生成一个溢写文件,如果map的输出结果真的很大,有多次这样的溢写发生,磁盘上相应的就会有多个溢写文件存在。当map task真正完成时,内存缓冲区中的数据也全部溢写到磁盘中形成一个溢写文件。最终磁盘中会至少有一个这样的溢写文件存在(如果map的输出结果很少,当map执行完成时,只会产生一个溢写文件),因为最终的文件只有一个,所以需要将这些溢写文件归并到一起,这个过程就叫做Merge。
请注意,因为merge是将多个溢写文件合并到一个文件,所以可能也有相同的key存在,在这个过程中如果client设置过Combiner,也会使用Combiner来合并相同的key。
2.partition
MapReduce提供Partitioner接口,它的作用就是根据key或value及reduce的数量来决定当前的这对输出数据最终应该交由哪个reduce task处理。默认对key hash后再以reduce task数量(默认一个MR的reduce task数量是1)取模。默认的取模方式只是为了平均reduce的处理能力,如果用户自己对Partitioner有需求,可以订制并设置到job上。
3.spill to disk
这个内存缓冲区是有大小限制的,默认是100MB。当map task的输出结果很多时,就可能会撑爆内存,所以需要在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区。这个从内存往磁盘写数据的过程被称为Spill,中文可译为溢写,字面意思很直观。这个溢写是由单独线程来完成,不影响往缓冲区写map结果的线程。溢写线程启动时不应该阻止map的结果输出,所以整个缓冲区有个溢写的比例spill.percent。这个比例默认是0.8,也就是当缓冲区的数据已经达到阈值(buffer size * spill percent = 100MB * 0.8 = 80MB),溢写线程启动,锁定这80MB的内存,执行溢写过程。Map task的输出结果还可以往剩下的20MB内存中写,互不影响。
4.sort
当溢写线程启动后,需要对这80MB空间内的key做排序(Sort)。排序是MapReduce模型默认的行为,这里的排序也是对序列化的字节做的排序。
5.combiner(对内存中的数据进行合并)
如果设置了combiner会启用执行分组函数
将有相同key的key/value对的value加起来,减少溢写到磁盘的数据量。
6.Merge(对大磁盘文件的合并)
每次溢写会在磁盘上生成一个溢写文件,如果map的输出结果真的很大,有多次这样的溢写发生,磁盘上相应的就会有多个溢写文件存在。当map task真正完成时,内存缓冲区中的数据也全部溢写到磁盘中形成一个溢写文件。最终磁盘中会至少有一个这样的溢写文件存在(如果map的输出结果很少,当map执行完成时,只会产生一个溢写文件),因为最终的文件只有一个,所以需要将这些溢写文件归并到一起,这个过程就叫做Merge。
请注意,因为merge是将多个溢写文件合并到一个文件,所以可能也有相同的key存在,在这个过程中如果client设置过Combiner,也会使用Combiner来合并相同的key。

------------------
1.Copy过程,简单地拉取数据。Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求map task所在的TaskTracker获取map task的输出文件。因为map task早已结束,这些文件就归TaskTracker管理在本地磁盘中。
2.Merge阶段。这里的merge如map端的merge动作,只是数组中存放的是不同map端copy来的数值。Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置,因为Shuffle阶段Reducer不运行,所以应该把绝大部分的内存都给Shuffle用。这里需要强调的是,merge有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。默认情况下第一种形式不启用,让人比较困惑,是吧。当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map 端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的那个文件。
3.Sort排序,因为从各个maptask取过来的数据所以数据已经乱了,所以需要重新排序(二次排序)
4.Group分组,排序之后进行分组,默认按照key是否相等来决定是否是一组,一组数据对应一个reduce。
split的计算公式
MapReduce的 Split大小– max.split(100M)
– min.split(10M)
– block(64M)
– max( min.split , min( max.split , block ))
Mapreduce的输出进行压缩